机器学习项目(一)——垃圾邮件的过滤技术
一、垃圾邮件过滤技术项目需求与设计方案


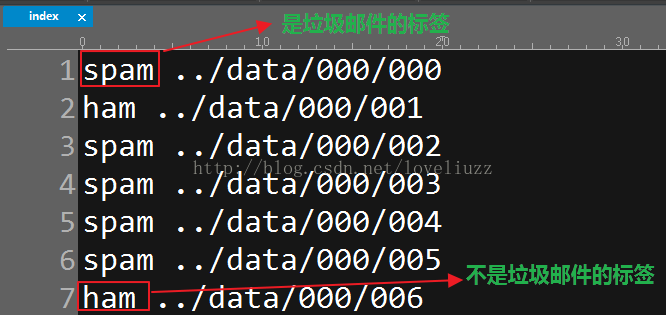
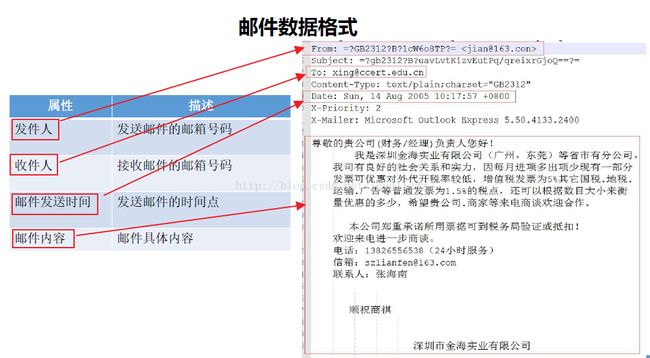
二、数据的内容分析
(1、是否为垃圾邮件的标签,spam——是垃圾邮件;ham——不是垃圾邮件)
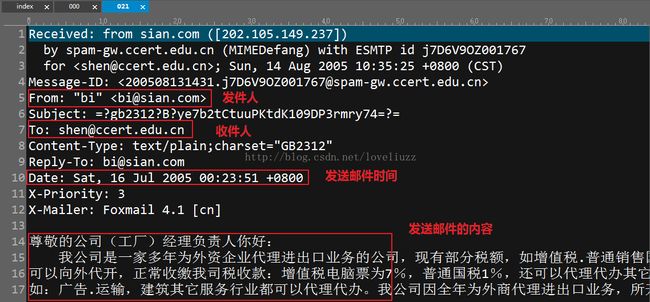
(2、邮件的内容分析——主要包含:发件人、收件人、发件时间以及邮件的内容)
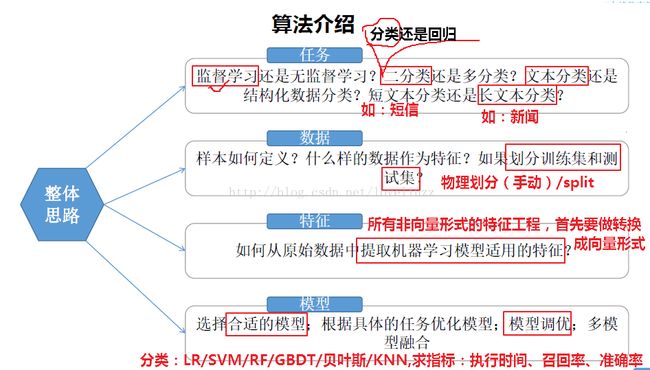
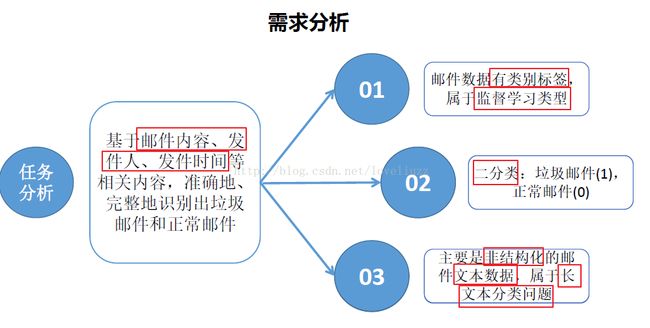
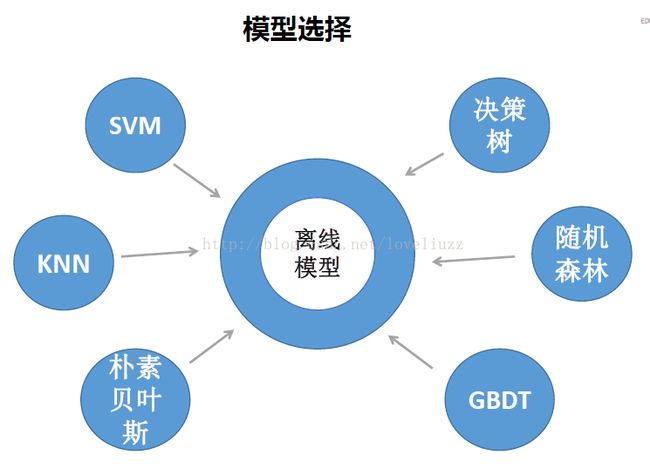
三、需求分析、模型选择与架构
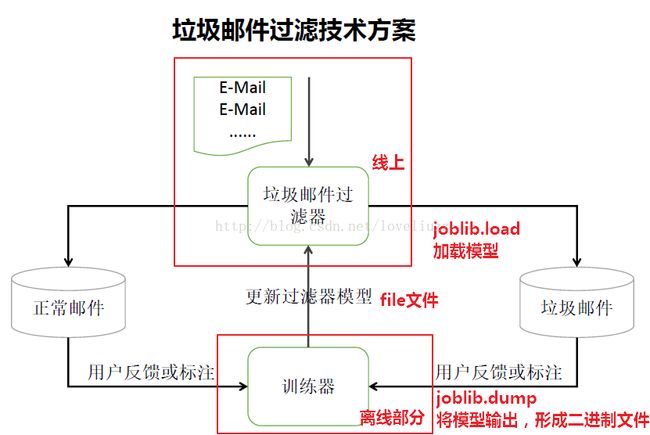
四、数据清洗
(一)·代码中应用的知识点
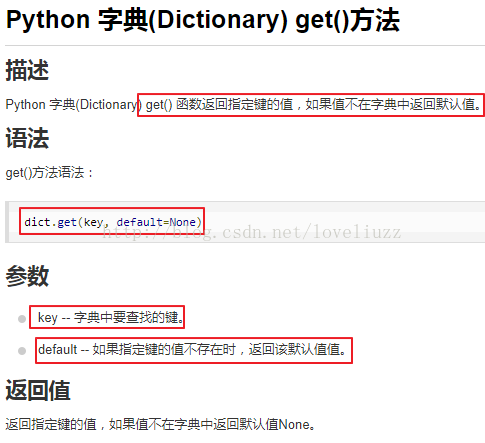
(1)字典的get()函数
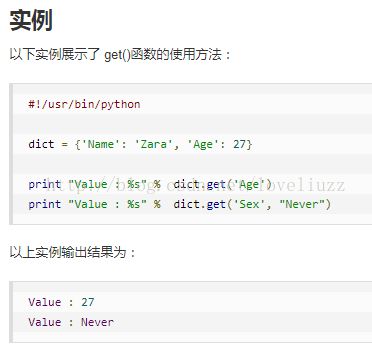
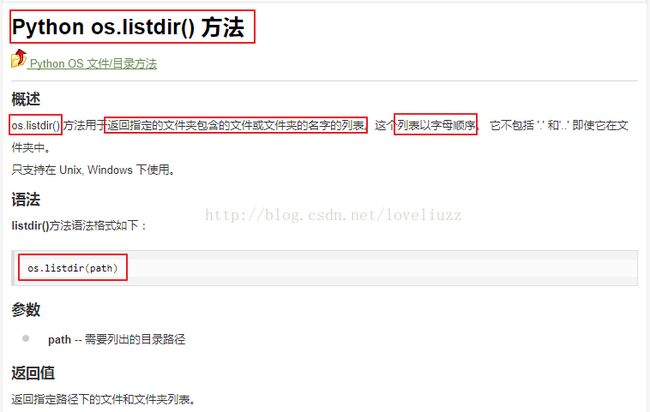
(2)os.listdir()
(二)数据清洗代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
import os
#1、索引文件(分类标签)读取,该文件中分为两列
#第一列:分类标签是否为垃圾邮件(是:spam、否:ham);
# 第二列:存放邮件对应文件夹路径,两列之间通过空格分割
def read_index_file(file_path):
type_dict = {"spam":"1","ham":"0"} #用字典存放垃圾邮件的分类标签
index_file = open(file_path)
index_dict = {}
try:
for line in index_file: # 按行循环读取文件
arr = line.split(" ") # 用“空格”进行分割
#pd.read_csv("full/index",sep=" ") #pandas来写与上面等价
if len(arr) == 2: #分割完之后如果长度是2
key,value = arr ##分别将spam ../data/178/129赋值给key与value
#添加到字段中
value = value.replace("../data","").replace("\n","") #替换
# 字典赋值,字典名[键]=值,lower()将所有的字母转换成小写
index_dict[value] = type_dict[key.lower()] #
finally:
index_file.close()
return index_dict
#2、邮件的文件内容数据读取
def read_file(file_path):
# 读操作,邮件数据编码为"gb2312",数据读取有异常就ignore忽略
file = open(file_path,"r",encoding="gb2312",errors="ignore")
content_dict = {}
try:
is_content = False
for line in file: # 按行读取
line = line.strip() # 每行的空格去掉用strip()
if line.startswith("From:"):
content_dict["from"] = line[5:]
elif line.startswith("To:"):
content_dict["to"] = line[3:]
elif line.startswith("Date:"):
content_dict["data"] = line[5:]
elif not line:
# 邮件内容与上面信息存在着第一个空行,遇到空行时,这里标记为True以便进行下面的邮件内容处理
# line文件的行为空时是False,不为空时是True
is_content = True
# 处理邮件内容(处理到为空的行时接着处理邮件的内容)
if is_content:
if "content" in content_dict:
content_dict["content"] += line
else:
content_dict["content"] = line
finally:
file.close()
return content_dict
#3、邮件数据处理(内容的拼接,并用逗号进行分割)
def process_file(file_path):
content_dict = read_file(file_path)
#进行处理(拼接),get()函数返回指定键的值,指定键的值不存在用指定的默认值unkown代替
result_str = content_dict.get("from","unkown").replace(",","").strip()+","
result_str += content_dict.get("to","unkown").replace(",","").strip()+","
result_str += content_dict.get("data","unkown").replace(",","").strip()+","
result_str += content_dict.get("content","unkown").replace(",","").strip()
return result_str
#4、开始进行数据处理——函数调用
## os.listdir 返回指定的文件夹包含的文件或文件夹包含的名称列表
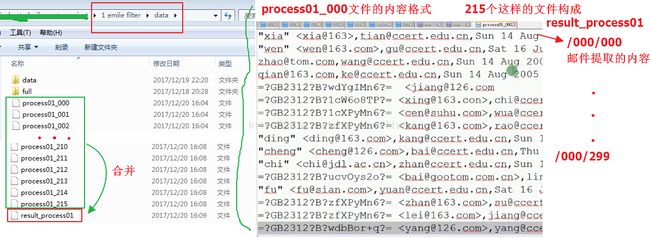
index_dict = read_index_file('../data/full/index')
list0 = os.listdir('../data/data') #list0是范围为[000-215]的列表
# print(list0)
for l1 in list0: # l1:循环000--215
l1_path = '../data/data/' + l1 #l1_path ../data/data/215
print('开始处理文件夹:' + l1_path)
list1 = os.listdir(l1_path) #list1:['000', '001', '002', '003'....'299']
# print(list1)
write_file_path = '../data/process01_' + l1
with open(write_file_path, "w", encoding='utf-8') as writer:
for l2 in list1: # l2:循环000--299
l2_path = l1_path + "/" + l2 # l2_path ../data/data/215/000
# 得到具体的文件内容后,进行文件数据的读取
index_key = "/" + l1 + "/" + l2 # index_key: /215/000
if index_key in index_dict:
# 读取数据
content_str = process_file(l2_path)
# 添加分类标签(0、1)也用逗号隔开
content_str += "," + index_dict[index_key] + "\n"
# 进行数据输出
writer.writelines(content_str)
# 再合并所有第一次构建好的内容
with open('../data/result_process01', 'w', encoding='utf-8') as writer:
for l1 in list0:
file_path = '../data/process01_' + l1
print("开始合并文件:" + file_path)
with open(file_path, encoding='utf-8') as file:
for line in file:
writer.writelines(line)
(三)邮件存放路径框架与各步骤运行结果
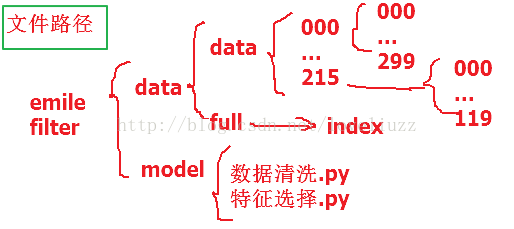



最后运行的结果:

五、特征工程
(一)邮件服务器处理

知识点应用:


#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
import re
import time
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
## 设置字符集,防止中文乱码
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=False
# 1、文件数据读取
df = pd.read_csv("../data/result_process01",sep=",",header=None,
names=["from","to","date","content","label"])
# print(df.head())
#2(1)、特征工程1 =>提取发件人和收件人的邮件服务器地址
def extract_email_server_address(str1):
it = re.findall(r"@([A-Za-z0-9]*\.[A-Za-z0-9\.]+)",str(str1))
result = ""
if len(it)>0:
result = it[0]
if not result:
result = "unknown"
return result
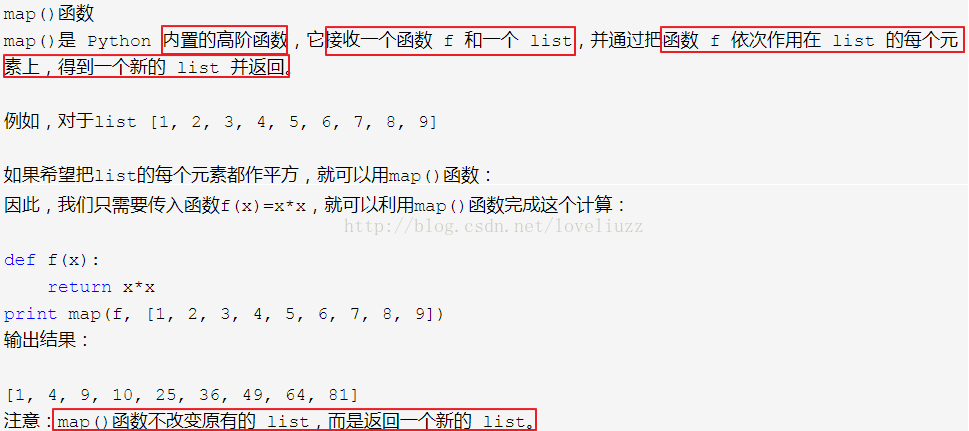
df["to_address"] = pd.Series(map(lambda str:extract_email_server_address(str),df["to"]))
df["from_address"] = pd.Series(map(lambda str:extract_email_server_address(str),df["from"]))
# print(df.head(2))
#2(2)、特征工程1 =>查看邮件服务器的数量
print("=================to address================")
print(df.to_address.value_counts().head(5))
print("总邮件接收服务器类别数量为:"+str(df.to_address.unique().shape))
print("=================from address================")
print(df.from_address.value_counts().head(5))
print("总邮件接收服务器类别数量为:"+str(df.from_address.unique().shape))
from_address_df = df.from_address.value_counts().to_frame()
len_less_10_from_adderss_count = from_address_df[from_address_df.from_address<=10].shape
print("发送邮件数量小于10封的服务器数量为:"+str(len_less_10_from_adderss_count))
(二)时间属性处理

#3、特征工程2 =>邮件的时间提取
def extract_email_date(str1):
if not isinstance(str1,str): #判断变量是否是str类型
str1 = str(str1) #str类型的强转
str_len = len(str1)
week = ""
hour = ""
# 0表示:上午[8,12];1表示:下午[13,18];2表示:晚上[19,23];3表示:凌晨[0,7]
time_quantum = ""
if str_len < 10:
#unknown
week = "unknown"
hour = "unknown"
time_quantum ="unknown"
pass
elif str_len == 16:
# 2005-9-2 上午10:55
rex = r"(\d{2}):\d{2}" # \d 匹配任意数字,这里匹配10:55
it = re.findall(rex,str1)
if len(it) == 1:
hour = it[0]
else:
hour = "unknown"
week = "Fri"
time_quantum = "0"
pass
elif str_len == 19:
# Sep 23 2005 1:04 AM
week = "Sep"
hour = "01"
time_quantum = "3"
pass
elif str_len == 21:
# August 24 2005 5:00pm
week = "Wed"
hour = "17"
time_quantum = "1"
pass
else:
#匹配一个字符开头,+表示至少一次 \d 表示数字 ?表示可有可无 *? 非贪婪模式
rex = r"([A-Za-z]+\d?[A-Za-z]*) .*?(\d{2}):\d{2}:\d{2}.*"
it = re.findall(rex,str1)
if len(it) == 1 and len(it[0]) == 2:
week = it[0][0][-3]
hour = it[0][1]
int_hour = int(hour)
if int_hour < 8:
time_quantum = "3"
elif int_hour < 13:
time_quantum = "0"
elif int_hour < 19:
time_quantum = "1"
else:
time_quantum = "2"
pass
else:
week = "unknown"
hour = "unknown"
time_quantum = "unknown"
week = week.lower()
hour = hour.lower()
time_quantum = time_quantum.lower()
return (week,hour,time_quantum)
#数据转换
data_time_extract_result = list(map(lambda st:extract_email_date(st),df["date"]))
df["date_week"] = pd.Series(map(lambda t:t[0],data_time_extract_result))
df["date_hour"] = pd.Series(map(lambda t:t[1],data_time_extract_result))
df["date_time_quantum"] = pd.Series(map(lambda t:t[2],data_time_extract_result))
print(df.head(2))
print("=======星期属性字段描述======")
print(df.date_week.value_counts().head(3))
print(df[["date_week","label"]].groupby(["date_week","label"])["label"].count())
print("=======小时属性字段描述======")
print(df.date_hour.value_counts().head(3))
print(df[['date_hour', 'label']].groupby(['date_hour', 'label'])['label'].count())
print("=======时间段属性字段描述======")
print(df.date_hour.value_counts().head(3))
print(df[["date_time_quantum","label"]].groupby(["date_time_quantum","label"])["label"].count())
#添加是否有时间
df["has_date"] = df.apply(lambda c: 0 if c["date_week"] == "unknown" else 1,axis=1)
print(df.head(2))
(三)邮件内容分词——jieba分词

#4、特征工程之三 => jieba分词操作
#将文本类型全部转换为str类型,然后进行分词操作
df["content"] = df["content"].astype("str")
'''
#1、jieba分词的重点在于:自定义词典
#2、jieba添加分词字典,jieba.load_userdict("userdict.txt"),字典格式为:单词 词频(可选的) 词性(可选的)
# 词典构建方式:一般都是基于jieba分词之后的效果进行人工干预
#3、添加新词、删除词 jieba.add_word("") jieba.del_word("")
#4、jieba.cut: def cut(self, sentence, cut_all=False, HMM=True)
# sentence:需要分割的文本,cut_all:分割模式,分为精准模式False、全分割True,HMM:新词可进行推测
#5、长文本采用精准分割,短文本采用全分割模式
# 一般在短文本处理过程中还需要考虑词性,并且还可能将分割好的单词进行组合
# 词性需要导入的包:import jieba.posseg
'''
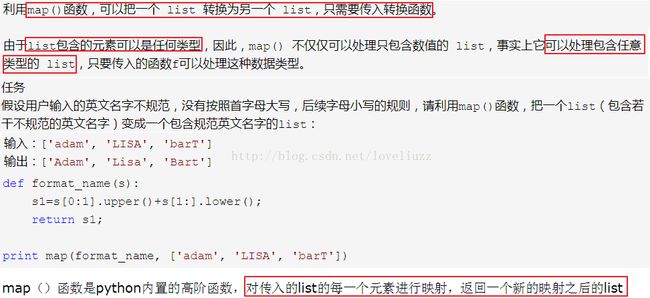
df["jieba_cut_content"] = list(map(lambda st:" ".join(jieba.cut(st)),df["content"])) #分开的词用空格隔开
print(df.head(2))运行结果为:

注意内容:

(四)邮件信息量/长度对是否为垃圾邮件的影响
(1)应用知识点——groupby()技术
详细参照链接:http://www.jianshu.com/p/2d49cb87626b
在数据分析中,我们往往需要在将数据拆分,在每一个特定的组里进行运算。比如根据教育水平和年龄段计算某个城市的工作人口的平均收入。pandas中的groupby提供了一个高效的数据的分组运算。我们通过一个或者多个分类变量数据拆分,然后分别在拆分以后的数据上进行需要的计算。


#5、特征工程之四 =>邮件长度对是否是垃圾邮件的影响
def process_content_length(lg):
if lg < 10:
return 0
elif lg <= 100:
return 1
elif lg <= 500:
return 2
elif lg <= 1000:
return 3
elif lg <= 1500:
return 4
elif lg <= 2000:
return 5
elif lg <= 2500:
return 6
elif lg <= 3000:
return 7
elif lg <= 4000:
return 8
elif lg <= 5000:
return 9
elif lg <= 10000:
return 10
elif lg <= 20000:
return 11
elif lg <= 30000:
return 12
elif lg <= 50000:
return 13
else:
return 14
df["content_length"] = pd.Series(map(lambda st:len(st),df["content"]))
df["content_length_type"] = pd.Series(map(lambda st:process_content_length(st),df["content_length"]))
#按照邮件长度类别和标签进行分组groupby,抽取这两列数据相同的放到一起,
# 用agg和内置函数count聚合不同长度邮件分贝是否为垃圾邮件的数量,
# reset_insex:将对象重新进行索引的构建
df2 = df.groupby(["content_length_type","label"])["label"].agg(["count"]).reset_index()
#label == 1:是垃圾邮件,对长度和数量进行重命名,count命名为c1
df3 = df2[df2.label == 1][["content_length_type","count"]].rename(columns={"count":"c1"})
df4 = df2[df2.label == 0][["content_length_type","count"]].rename(columns={"count":"c2"})
df5 = pd.merge(df3,df4) #数据集的合并,pandas.merge可依据一个或多个键将不同DataFrame中的行连接起来
df5["c1_rage"] = df5.apply(lambda r:r["c1"]/(r["c1"]+r["c2"]),axis=1) #按行进行统计
df5["c2_rage"] = df5.apply(lambda r:r["c2"]/(r["c1"]+r["c2"]),axis=1)
print(df5.head())
#画图
plt.plot(df5["content_length_type"],df5["c1_rage"],label=u"垃圾邮件比例")
plt.plot(df5["content_length_type"],df5["c2_rage"],label=u"正常邮件比例")
plt.xlabel(u"邮件长度标记")
plt.ylabel(u"邮件比例")
plt.grid(True)
plt.legend(loc=0)
plt.savefig("垃圾和正常邮件比例.png")
plt.show()运行结果:

(五)添加信号量
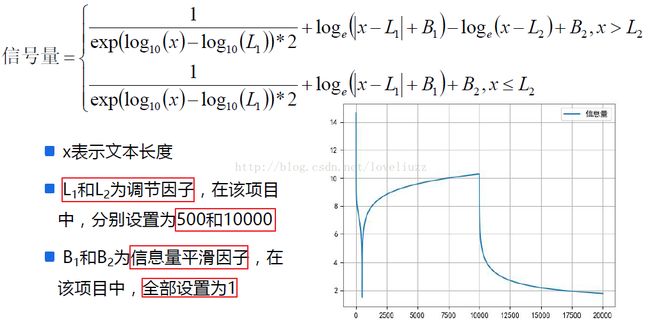
#6、特征工程之五 ==> 添加信号量
def precess_content_sema(x):
if x>10000:
return 0.5/np.exp(np.log10(x)-np.log10(500))+np.log(abs(x-500)+1)-np.log(abs(x-10000))+1
else:
return 0.5/np.exp(np.log10(x)-np.log10(500))+np.log(abs(x-500)+1)+1
a = np.arange(1,20000)
plt.plot(a,list(map(lambda t:precess_content_sema(t),a)),label=u"信息量")
plt.grid(True)
plt.legend(loc=0)
plt.savefig("信息量.png")
plt.show()
df["content_sema"] = list(map(lambda st:precess_content_sema(st),df["content_length"]))
print(df.head(2))#查看列名称
print(df.dtypes)
#获取需要的列,drop删除不需要的列
df.drop(["from","to","date","content","to_address","from_address",
"date_week","date_hour","date_time_quantum","content_length",
"content_length_type"],1,inplace=True)
print(df.info())
print(df.head())
#结果输出到CSV文件中
df.to_csv("../data/result_process02",encoding="utf-8",index=False)运行结果:



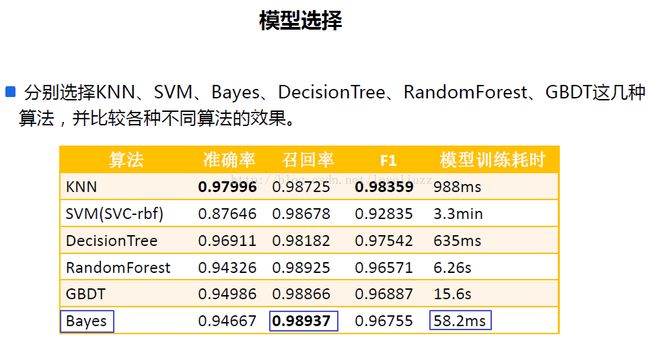
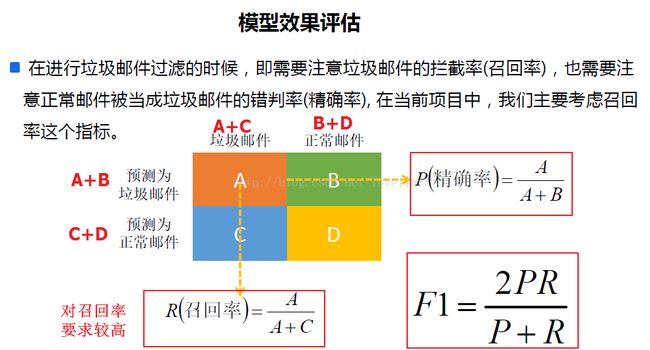
六、模型效果评估
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
import time
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.decomposition import TruncatedSVD #降维
from sklearn.naive_bayes import BernoulliNB #伯努利分布的贝叶斯公式
from sklearn.metrics import f1_score,precision_score,recall_score
## 设置字符集,防止中文乱码
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=False
#1、文件数据读取
df = pd.read_csv("../data/result_process02",encoding="utf-8",sep=",")
#如果有nan值,进行上删除操作
df.dropna(axis=0,how="any",inplace=True) #删除表中含有任何NaN的行
print(df.head())
print(df.info())
#2、数据分割
x_train,x_test,y_train,y_test = train_test_split(df[["has_date","jieba_cut_content","content_sema"]],
df["label"],test_size=0.2,random_state=0)
print("训练数据集大小:%d" %x_train.shape[0])
print("测试数据集大小:%d" %x_test.shape[0])
print(x_train.head())
#3、开始模型训练
#3.1、特征工程,将文本数据转换为数值型数据
transformer = TfidfVectorizer(norm="l2",use_idf=True)
svd = TruncatedSVD(n_components=20) #奇异值分解,降维
jieba_cut_content = list(x_train["jieba_cut_content"].astype("str"))
transformer_model = transformer.fit(jieba_cut_content)
df1 = transformer_model.transform(jieba_cut_content)
svd_model = svd.fit(df1)
df2 = svd_model.transform(df1)
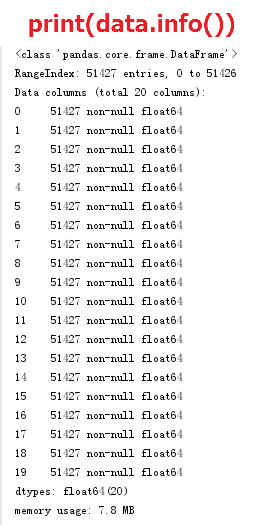
data = pd.DataFrame(df2)
print(data.head())
print(data.info())
#3.2、数据合并
data["has_date"] = list(x_train["has_date"])
data["content_sema"] = list(x_train["content_sema"])
print("========数据合并后的data信息========")
print(data.head())
print(data.info())
t1 = time.time()
nb = BernoulliNB(alpha=1.0,binarize=0.0005) #贝叶斯分类模型构建
model = nb.fit(data,y_train)
t = time.time()-t1
print("贝叶斯模型构建时间为:%.5f ms" %(t*1000))
#4.1 对测试数据进行转换
jieba_cut_content_test = list(x_test["jieba_cut_content"].astype("str"))
data_test = pd.DataFrame(svd_model.transform(transformer_model.transform(jieba_cut_content_test)))
data_test["has_date"] = list(x_test["has_date"])
data_test["content_sema"] = list(x_test["content_sema"])
print(data_test.head())
print(data_test.info())
#4.2 对测试数据进行测试
y_predict = model.predict(data_test)
#5、效果评估
print("准确率为:%.5f" % precision_score(y_test,y_predict))
print("召回率为:%.5f" % recall_score(y_test,y_predict))
print("F1值为:%.5f" % f1_score(y_test,y_predict))
运行结果:





![]()