深度学习一些基础
深度学习中Embedding层有什么用?

这篇博客翻译自国外的深度学习系列文章的第四篇,想查看其他文章请点击下面的链接,人工翻译也是劳动,如果你觉得有用请打赏,转载请打赏:
- Setting up AWS & Image Recognition
- Convolutional Neural Networks
- More on CNNs & Handling Overfitting
在深度学习实验中经常会遇Eembedding层,然而网络上的介绍可谓是相当含糊。比如 Keras中文文档中对嵌入层 Embedding的介绍除了一句 “嵌入层将正整数(下标)转换为具有固定大小的向量”之外就不愿做过多的解释。那么我们为什么要使用嵌入层 Embedding呢? 主要有这两大原因:
-
使用One-hot 方法编码的向量会很高维也很稀疏。假设我们在做自然语言处理(NLP)中遇到了一个包含2000个词的字典,当时用One-hot编码时,每一个词会被一个包含2000个整数的向量来表示,其中1999个数字是0,要是我的字典再大一点的话这种方法的计算效率岂不是大打折扣?
-
训练神经网络的过程中,每个嵌入的向量都会得到更新。如果你看到了博客上面的图片你就会发现在多维空间中词与词之间有多少相似性,这使我们能可视化的了解词语之间的关系,不仅仅是词语,任何能通过嵌入层 Embedding 转换成向量的内容都可以这样做。
上面说的概念可能还有点含糊. 那我们就举个栗子看看嵌入层 Embedding 对下面的句子做了什么:)。Embedding的概念来自于word embeddings,如果您有兴趣阅读更多内容,可以查询 word2vec 。
“deep learning is very deep”
使用嵌入层embedding 的第一步是通过索引对该句子进行编码,这里我们给每一个不同的句子分配一个索引,上面的句子就会变成这样:
1 2 3 4 1
接下来会创建嵌入矩阵,我们要决定每一个索引需要分配多少个‘潜在因子’,这大体上意味着我们想要多长的向量,通常使用的情况是长度分配为32和50。在这篇博客中,为了保持文章可读性这里为每个索引指定6个潜在因子。嵌入矩阵就会变成这样:
【latent Factors】

这样,我们就可以使用嵌入矩阵来而不是庞大的one-hot编码向量来保持每个向量更小。简而言之,嵌入层embedding在这里做的就是把单词“deep”用向量[.32, .02, .48, .21, .56, .15]来表达。然而并不是每一个单词都会被一个向量来代替,而是被替换为用于查找嵌入矩阵中向量的索引。其次这种方法面对大数据时也可有效计算。由于在深度神经网络的训练过程中嵌入向量也会被更新,我们就可以探索在高维空间中哪些词语之间具有彼此相似性,再通过使用t-SNE 这样的降维技术就可以将这些相似性可视化。

Not Just Word Embeddings
These previous examples showed that word embeddings are very important in the world of Natural Language Processing. They allow us to capture relationships in language that are very difficult to capture otherwise. However, embedding layers can be used to embed many more things than just words. In my current research project I am using embedding layers to embed online user behavior. In this case I am assigning indices to user behavior like ‘page view on page type X on portal Y’ or ‘scrolled X pixels’. These indices are then used for constructing a sequence of user behavior.
In a comparison of ‘traditional’ machine learning models (SVM, Random Forest, Gradient Boosted Trees) with deep learning models (deep neural networks, recurrent neural networks) I found that this embedding approach worked very well for deep neural networks.
The ‘traditional’ machine learning models rely on a tabular input that is feature engineered. This means that we, as researchers, decide what gets turned into a feature. In these cases features could be: amount of homepages visited, amount of searches done, total amount of pixels scrolled. However, it is very difficult to capture the spatial (time) dimension when doing feature-engineering. By using deep learning and embedding layers we can efficiently capture this spatial dimension by supplying a sequence of user behavior (as indices) as input for the model.
In my research the Recurrent Neural Network with Gated Recurrent Unit/Long-Short Term Memory performed best. The results were very close. From the ‘traditional’ feature engineered models Gradient Boosted Trees performed best. I will write a blog post about this research in more detail in the future. I think my next blog post will explore Recurrent Neural Networks in more detail.
Other research has explored the use of embedding layers to encode student behavior in MOOCs (Piech et al., 2016) and users’ path through an online fashion store (Tamhane et al., 2017).
Recommender Systems
Embedding layers can even be used to deal with the sparse matrix problem in recommender systems. Since the deep learning course (fast.ai) uses recommender systems to introduce embedding layers I want to explore them here as well.
Recommender systems are being used everywhere and you are probably being influenced by them every day. The most common examples are Amazon’s product recommendation and Netflix’s program recommendation systems. Netflix actually held a $1,000,000 challenge to find the best collaborative filtering algorithm for their recommender system. You can see a visualization of one of these models here.
There are two main types of recommender systems and it is important to distinguish between the two.
- Content-based filtering. This type of filtering is based on data about the item/product. For example, we have our users fill out a survey on what movies they like. If they say that they like sci-fi movies we recommend them sci-fi movies. In this case al lot of meta-information has to be available for all items.
- Collaborative filtering: Let’s find other people like you, see what they liked and assume you like the same things. People like you = people who rated movies that you watched in a similar way. In a large dataset this has proven to work a lot better than the meta-data approach. Essentially asking people about their behavior is less good compared to looking at their actual behavior. Discussing this further is something for the psychologists among us.
In order to solve this problem we can create a huge matrix of the ratings of all users against all movies. However, in many cases this will create an extremely sparse matrix. Just think of your Netflix account. What percentage of their total supply of series and movies have you watched? It’s probably a pretty small percentage. Then, through gradient descent we can train a neural network to predict how high each user would rate each movie. Let me know if you would like to know more about the use of deep learning in recommender systems and we can explore it further together. In conclusion, embedding layers are amazing and should not be overlooked.
If you liked this posts be sure to recommend it so others can see it. You can also follow this profile to keep up with my process in the Fast AI course. See you there!
References
Piech, C., Bassen, J., Huang, J., Ganguli, S., Sahami, M., Guibas, L. J., & Sohl-Dickstein, J. (2015). Deep knowledge tracing. In Advances in Neural Information Processing Systems (pp. 505–513).
Tamhane, A., Arora, S., & Warrier, D. (2017, May). Modeling Contextual Changes in User Behaviour in Fashion e-Commerce. In Pacific-Asia Conference on Knowledge Discovery and Data Mining (pp. 539–550). Springer, Cham.
Embedding layers in keras
嵌入层embedding用在网络的开始层将你的输入转换成向量,所以当使用 Embedding前应首先判断你的数据是否有必要转换成向量。如果你有categorical数据或者数据仅仅包含整数(像一个字典一样具有固定的数量)你可以尝试下Embedding 层。
如果你的数据是多维的你可以对每个输入共享嵌入层或尝试单独的嵌入层。
from keras.layers.embeddings import Embedding
Embedding(input_dim, output_dim, embeddings_initializer='uniform', embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None)
- 1
- 2
- 3
-The first value of the Embedding constructor is the range of values in the input. In the example it’s 2 because we give a binary vector as input.
- The second value is the target dimension.
- The third is the length of the vectors we give.
- input_dim: int >= 0. Size of the vocabulary, ie. 1+maximum integer
index occuring in the input data.
本文译自:https://medium.com/towards-data-science/deep-learning-4-embedding-layers-f9a02d55ac12
How does embedding work? An example demonstrates best what is going on.
Assume you have a sparse vector [0,1,0,1,1,0,0] of dimension seven. You can turn it into a non-sparse 2d vector like so:
model = Sequential()
model.add(Embedding(2, 2, input_length=7))
model.compile('rmsprop', 'mse')
model.predict(np.array([[0,1,0,1,1,0,0]]))
- 1
- 2
- 3
- 4
array([[[ 0.03005414, -0.02224021],
[ 0.03396987, -0.00576888],
[ 0.03005414, -0.02224021],
[ 0.03396987, -0.00576888],
[ 0.03396987, -0.00576888],
[ 0.03005414, -0.02224021],
[ 0.03005414, -0.02224021]]], dtype=float32)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Where do these numbers come from? It’s a simple map from the given range to a 2d space:
model.layers[0].W.get_value()
- 1
array([[ 0.03005414, -0.02224021],
[ 0.03396987, -0.00576888]], dtype=float32)
- 1
- 2
The 0-value is mapped to the first index and the 1-value to the second as can be seen by comparing the two arrays. The first value of the Embedding constructor is the range of values in the input. In the example it’s 2 because we give a binary vector as input. The second value is the target dimension. The third is the length of the vectors we give.
So, there is nothing magical in this, merely a mapping from integers to floats.
Now back to our ‘shining’ detection. The training data looks like a sequences of bits:
X
- 1
array([[ 0., 1., 1., 1., 0., 1., 0., 1., 0., 0., 0., 0., 0.,
1., 0., 0., 0., 0., 0.],
[ 0., 1., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1.,
0., 0., 0., 0., 0., 0.],
[ 0., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.,
0., 0., 1., 0., 1., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0.,
0., 1., 0., 1., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 1., 0., 1., 0., 1., 0., 0.,
0., 0., 0., 0., 0., 1.]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
If you want to use the embedding it means that the output of the embedding layer will have dimension (5, 19, 10). This works well with LSTM or GRU (see below) but if you want a binary classifier you need to flatten this to (5, 19*10):
model = Sequential()
model.add(Embedding(3, 10, input_length= X.shape[1] ))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='rmsprop')
model.fit(X, y=y, batch_size=200, nb_epoch=700, verbose=0, validation_split=0.2, show_accuracy=True, shuffle=True)
- 1
- 2
- 3
- 4
- 5
- 6
It detects ‘shining’ flawlessly:
model.predict(X)
- 1
array([[ 1.00000000e+00],
[ 8.39483363e-08],
[ 9.71878720e-08],
[ 7.35597965e-08],
[ 9.91844118e-01]], dtype=float32)
- 1
- 2
- 3
- 4
- 5
An LSTM layer has historical memory and so the dimension outputted by the embedding works in this case, no need to flatten things:
model = Sequential()
model.add(Embedding(vocab_size, 10))
model.add(LSTM(5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='rmsprop')
model.fit(X, y=y, nb_epoch=500, verbose=0, validation_split=0.2, show_accuracy=True, shuffle=True)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Obviously, it predicts things as well:
model.predict(X)
- 1
array([[ 0.96855599],
[ 0.01917232],
[ 0.01917362],
[ 0.01917258],
[ 0.02341695]], dtype=float32)
- 1
- 2
- 3
- 4
- 5
本文译自:http://www.orbifold.net/default/2017/01/10/embedding-and-tokenizer-in-keras/
================================================================================================================================================================================================================================================================================================================================================================================================
Embedding理解与代码实现
2018年12月19日 16:39:49 lyshello123 阅读数 6290
版权声明:本文为博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/songyunli1111/article/details/85100616
Embedding 字面理解是 “嵌入”,实质是一种映射,从语义空间到向量空间的映射,同时尽可能在向量空间保持原样本在语义空间的关系,如语义接近的两个词汇在向量空间中的位置也比较接近。
下面以一个基于Keras的简单的文本情感分类问题为例解释Embedding的训练过程:
首先,导入Keras的相关库
from keras.layers import Dense, Flatten, Input
from keras.layers.embeddings import Embedding
from keras.models import Model
from keras.preprocessing.sequence import pad_sequences
from keras.preprocessing.text import one_hot
import numpy as np
给出文本内容和label
# define documents
docs = ['Well done!',
'Good work',
'Great effort',
'nice work',
'Excellent!',
'Weak',
'Poor effort!',
'not good',
'poor work',
'Could have done better.']
# define class labels
labels = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
然后将文本编码成数字格式并padding到相同长度
# integer encode the documents
vocab_size = 50
encoded_docs = [one_hot(d, vocab_size) for d in docs]
print(encoded_docs)
# pad documents to a max length of 4 words
max_length = 4
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post')
print(padded_docs)
上面两个print输出如下,每次运行得到的数字可能会不一样,但同一个单词对应相同的数字。上述one_hot编码映射到[1,n],不包括0,n为上述的vocab_size,为估计的词汇表大小。然后padding到最大的词汇长度,用0向后填充,这也是为什么前面one-hot不会映射到0的原因。
[[41, 13], [14, 5], [11, 19], [30, 5], [47], [16], [37, 19], [26, 14], [37, 5], [38, 40, 13, 19], [37], [14]]
[[41 13 0 0]
[14 5 0 0]
[11 19 0 0]
[30 5 0 0]
[47 0 0 0]
[16 0 0 0]
[37 19 0 0]
[26 14 0 0]
[37 5 0 0]
[38 40 13 19]
[37 0 0 0]
[14 0 0 0]]
模型的定义
# define the model
input = Input(shape=(4, ))
x = Embedding(vocab_size, 8, input_length=max_length)(input) #这一步对应的参数量为50*8
x = Flatten()(x)
x = Dense(1, activation='sigmoid')(x)
model = Model(inputs=input, outputs=x)
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
# summarize the model
print(model.summary()) #输出模型结构
输出的模型结构如下所示:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 4) 0
_________________________________________________________________
embedding_1 (Embedding) (None, 4, 8) 400
_________________________________________________________________
flatten_1 (Flatten) (None, 32) 0
_________________________________________________________________
dense_1 (Dense) (None, 1) 33
=================================================================
这里先介绍一下Keras中的Embedding函数,详细见z官方文档:Embedding
keras.layers.Embedding(input_dim, output_dim, input_length)
- 1
- input_dim:这是文本数据中词汇的取值可能数。例如,如果您的数据是整数编码为0-9之间的值,那么词汇的大小就是10个单词;
- output_dim:这是嵌入单词的向量空间的大小。它为每个单词定义了这个层的输出向量的大小。例如,它可能是32或100甚至更大,可以视为具体问题的超参数;
- input_length:这是输入序列的长度,就像您为Keras模型的任何输入层所定义的一样,也就是一次输入带有的词汇个数。例如,如果您的所有输入文档都由1000个字组成,那么input_length就是1000。
再看一下keras中embeddings的源码,其构建函数如下:
def build(self, input_shape):
self.embeddings = self.add_weight(
shape=(self.input_dim, self.output_dim),
initializer=self.embeddings_initializer,
name='embeddings',
regularizer=self.embeddings_regularizer,
constraint=self.embeddings_constraint,
dtype=self.dtype)
self.built = True
可以看到它的参数shape为(self.input_dim, self.output_dim),在上述例子中即(50,8)
上面输出的模型结构中Embedding层的参数为400,它实质就是50*8得到的,这是一个关键要理解的信息。
我们知道one-hot 是无法考虑语义间的相互关系的,但embedding向量的训练是要借助one-hot的。上面的one-hot把每一个单词映射成一个整数,但实际上这个整数就表示了50维向量中 1 所在的索引位置,用整数显示是为了更好理解和表示,而实际在网络中,它的形式可以理解为如下图(下面相当于one-hot向量为5维,输出embedding向量为3维)

右边的神经元为one-hot输入,左边为得到的embedding表示,图中1所对应的红线权重就是该单词对应的词向量,这一层神经元只能作为第一层嵌入,是没有偏置和激活函数的,它也可以被理解为如下的一个矩阵相乘,输出就是该单词的词向量。然后词向量再输入到下一层。这一层总的参数量就是这些权重,也是下面中间的矩阵。

一个词组中有多个单词,如上面例子中有四个,那就分别经过这一层得到四个词向量,然后Flatten 到一层,再后接全连接层进行分类。因此,在这个模型中,embedding向量和分类模型是同时训练的,当然也可以用他人在大预料库中已经训练好的向量来直接训练分类。
上述例子的完整代码如下:
from keras.layers import Dense, Flatten, Input
from keras.layers.embeddings import Embedding
from keras.models import Model
from keras.preprocessing.sequence import pad_sequences
from keras.preprocessing.text import one_hot
import numpy as np
# define documents
docs = ['Well done!',
'Good work',
'Great effort',
'nice work',
'Excellent!',
'Weak',
'Poor effort!',
'not good',
'poor work',
'Could have done better.']
# define class labels
labels = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
# integer encode the documents
vocab_size = 50
encoded_docs = [one_hot(d, vocab_size) for d in docs] #one_hot编码到[1,n],不包括0
print(encoded_docs)
# pad documents to a max length of 4 words
max_length = 4
padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post')
print(padded_docs)
# define the model
input = Input(shape=(4, ))
x = Embedding(vocab_size, 8, input_length=max_length)(input) #这一步对应的参数量为50*8
x = Flatten()(x)
x = Dense(1, activation='sigmoid')(x)
model = Model(inputs=input, outputs=x)
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
# summarize the model
print(model.summary())
# fit the model
model.fit(padded_docs, labels, epochs=100, verbose=0)
# evaluate the model
loss, accuracy = model.evaluate(padded_docs, labels, verbose=0)
loss_test, accuracy_test = model.evaluate(padded_docs, labels, verbose=0)
print('Accuracy: %f' % (accuracy * 100))
# test the model
test = one_hot('good',50)
padded_test = pad_sequences([test], maxlen=max_length, padding='post')
print(model.predict(padded_test))
图片参考自:https://blog.csdn.net/laolu1573/article/details/77170407
================================================================================================================================================================================================================================================================================================
自然语言处理中的语言模型预训练方法(ELMo、GPT和BERT)
自然语言处理中的语言模型预训练方法(ELMo、GPT和BERT)
最近,在自然语言处理(NLP)领域中,使用语言模型预训练方法在多项NLP任务上都获得了不错的提升,广泛受到了各界的关注。就此,我将最近看的一些相关论文进行总结,选取了几个代表性模型(包括ELMo [1],OpenAI GPT [2]和BERT [3])和大家一起学习分享。
1. 引言
在介绍论文之前,我将先简单介绍一些相关背景知识。首先是语言模型(Language Model),语言模型简单来说就是一串词序列的概率分布。具体来说,语言模型的作用是为一个长度为m的文本确定一个概率分布P,表示这段文本存在的可能性。在实践中,如果文本的长度较长,P(wi | w1, w2, . . . , wi−1)的估算会非常困难。因此,研究者们提出使用一个简化模型:n元模型(n-gram model)。在 n 元模型中估算条件概率时,只需要对当前词的前n个词进行计算。在n元模型中,传统的方法一般采用频率计数的比例来估算n元条件概率。当n较大时,机会存在数据稀疏问题,导致估算结果不准确。因此,一般在百万词级别的语料中,一般也就用到三元模型。

为了缓解n元模型估算概率时遇到的数据稀疏问题,研究者们提出了神经网络语言模型。代表性工作是Bengio等人在2003年提出的神经网络语言模型,该语言模型使用了一个三层前馈神经网络来进行建模。其中有趣的发现了第一层参数,用做词表示不仅低维紧密,而且能够蕴涵语义,也就为现在大家都用的词向量(例如word2vec)打下了基础。其实,语言模型就是根据上下文去预测下一个词是什么,这不需要人工标注语料,所以语言模型能够从无限制的大规模单语语料中,学习到丰富的语义知识。
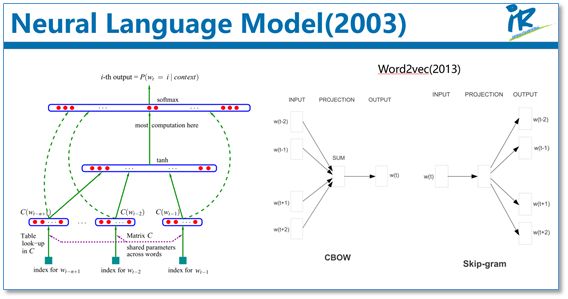
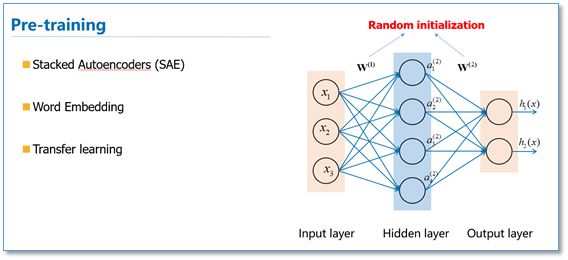
接下来在简单介绍一下预训练的思想。我们知道目前神经网络在进行训练的时候基本都是基于后向传播(BP)算法,通过对网络模型参数进行随机初始化,然后通过BP算法利用例如SGD这样的优化算法去优化模型参数。那么预训练的思想就是,该模型的参数不再是随机初始化,而是先有一个任务进行训练得到一套模型参数,然后用这套参数对模型进行初始化,再进行训练。其实早期的使用自编码器栈式搭建深度神经网络就是这个思想。还有词向量也可以看成是第一层word embedding进行了预训练,此外在基于神经网络的迁移学习中也大量用到了这个思想。
接下来,我们就具体看一下这几篇用语言模型进行预训练的工作。
2. ELMo
2.1 引言
《Deep Contextualized Word Representations》这篇论文来自华盛顿大学的工作,最后是发表在今年的NAACL会议上,并获得了最佳论文。其实这个工作的前身来自同一团队在ACL2017发表的《Semi-supervised sequence tagging with bidirectional language models》 [4],只是在这篇论文里,他们把模型更加通用化了。首先我们来看看他们工作的动机,他们认为一个预训练的词表示应该能够包含丰富的句法和语义信息,并且能够对多义词进行建模。而传统的词向量(例如word2vec)是上下文无关的。例如下面"apple"的例子,这两个"apple"根据上下文意思是不同的,
但是在word2vec中,只有apple一个词向量,无法对一词多义进行建模。

所以他们利用语言模型来获得一个上下文相关的预训练表示,称为ELMo,并在6个NLP任务上获得了提升。

2.2 方法
在EMLo中,他们使用的是一个双向的LSTM语言模型,由一个前向和一个后向语言模型构成,目标函数就是取这两个方向语言模型的最大似然。
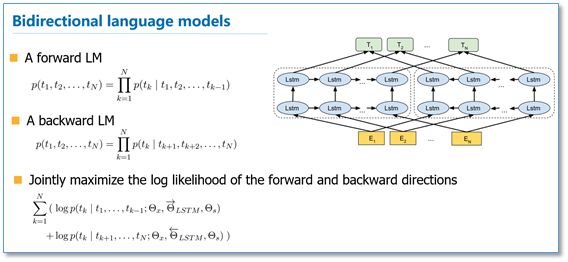
在预训练好这个语言模型之后,ELMo就是根据下面的公式来用作词表示,其实就是把这个双向语言模型的每一中间层进行一个求和。最简单的也可以使用最高层的表示来作为ELMo。

然后在进行有监督的NLP任务时,可以将ELMo直接当做特征拼接到具体任务模型的词向量输入或者是模型的最高层表示上。总结一下,不像传统的词向量,每一个词只对应一个词向量,ELMo利用预训练好的双向语言模型,然后根据具体输入从该语言模型中可以得到上下文依赖的当前词表示(对于不同上下文的同一个词的表示是不一样的),再当成特征加入到具体的NLP有监督模型里。
2.3 实验
这里我们简单看一下主要的实验,具体实验还需阅读论文。首先是整个模型效果的实验。他们在6个NLP任务上进行了实验,首先根据目前每个任务搭建了不同的模型作为baseline,然后加入ELMo,可以看到加入ELMo后6个任务都有所提升,平均大约能够提升2个多百分点,并且最后的结果都超过了之前的先进结果(SOTA)。

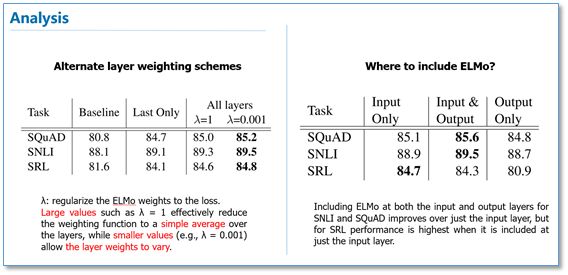
在下面的分析实验中,我们可以看到使用所有层的效果要比只使用最后一层作为ELMo的效果要好。在输入还是输出上面加EMLo效果好的问题上,并没有定论,不同的任务可能效果不一样。
3. Open AI GPT
3.1 引言
我们来看看第二篇论文《Improving Language Understanding by Generative Pre-Training》,这是OpenAI 团队前一段时间放出来的预印版论文。他们的目标是学习一个通用的表示,能够在大量任务上进行应用。这篇论文的亮点主要在于,他们利用了Transformer网络代替了LSTM作为语言模型来更好的捕获长距离语言结构。然后在进行具体任务有监督微调时使用了语言模型作为附属任务训练目标。最后再12个NLP任务上进行了实验,9个任务获得了SOTA。

3.2 方法
首先我们来看一下他们无监督预训练时的语言模型。他们仍然使用的是标准的语言模型目标函数,即通过前k个词预测当前词,但是在语言模型网络上他们使用了google团队在《Attention is all your need》论文中提出的Transformer解码器作为语言模型。Transformer模型主要是利用自注意力(self-attention)机制的模型,这里我就不多进行介绍,大家可以看论文或者参考我之前的博客(https://www.cnblogs.com/robert-dlut/p/8638283.html)。

然后再具体NLP任务有监督微调时,与ELMo当成特征的做法不同,OpenAI GPT不需要再重新对任务构建新的模型结构,而是直接在transformer这个语言模型上的最后一层接上softmax作为任务输出层,然后再对这整个模型进行微调。他们额外发现,如果使用语言模型作为辅助任务,能够提升有监督模型的泛化能力,并且能够加速收敛。

由于不同NLP任务的输入有所不同,在transformer模型的输入上针对不同NLP任务也有所不同。具体如下图,对于分类任务直接讲文本输入即可;对于文本蕴涵任务,需要将前提和假设用一个Delim分割向量拼接后进行输入;对于文本相似度任务,在两个方向上都使用Delim拼接后,进行输入;对于像问答多选择的任务,就是将每个答案和上下文进行拼接进行输入。
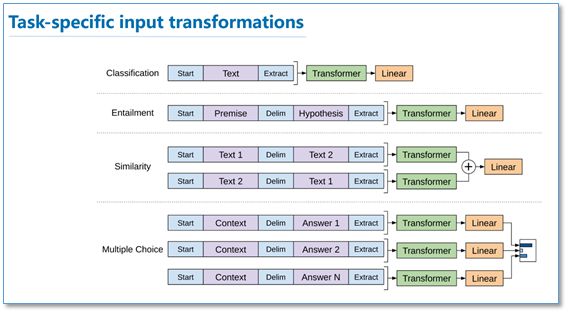
3.3 实验
下面我简单的列举了一下不同NLP任务上的实验结果。
语言推理任务:

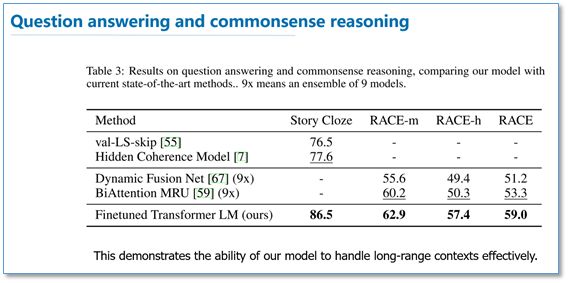
问答和常识推理任务:
语义相似度和分类任务:
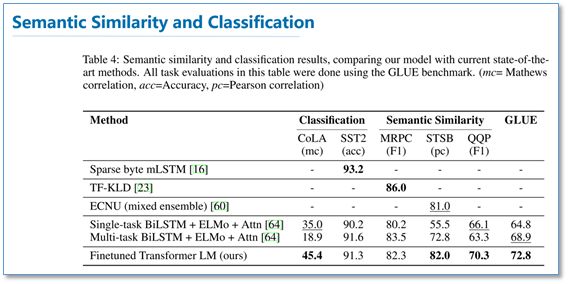
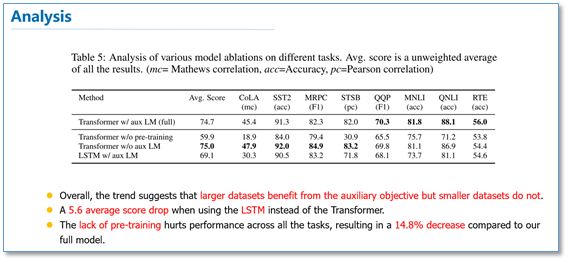
可以看到在多项任务上,OpenAI GPT的效果要比ELMo的效果更好。从下面的消除实验来看,在去掉预训练部分后,所有任务都大幅下降,平均下降了14.8%,说明预训练很有效;在大数据集上使用语言模型作为附加任务的效果更好,小数据集不然;利用LSTM代替Transformer后,结果平均下降了5.6%,也体现了Transformer的性能。
4. BERT
4.1引言
上周Google放出了他们的语言模型预训练方法,瞬时受到了各界广泛关注,不少媒体公众号也进行了相应报道,那我们来看看这篇论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》。这篇论文把预训练语言表示方法分为了基于特征的方法(代表ELMo)和基于微调的方法(代表OpenAI GPT)。而目前这两种方法在预训练时都是使用单向的语言模型来学习语言表示。

这篇论文中,作者们证明了使用双向的预训练效果更好。其实这篇论文方法的整体框架和GPT类似,是进一步的发展。具体的,他们BERT是使用Transformer的编码器来作为语言模型,在语言模型预训练的时候,提出了两个新的目标任务(即遮挡语言模型MLM和预测下一个句子的任务),最后在11个NLP任务上取得了SOTA。

4.2方法
在语言模型上,BERT使用的是Transformer编码器,并且设计了一个小一点Base结构和一个更大的Large网络结构。

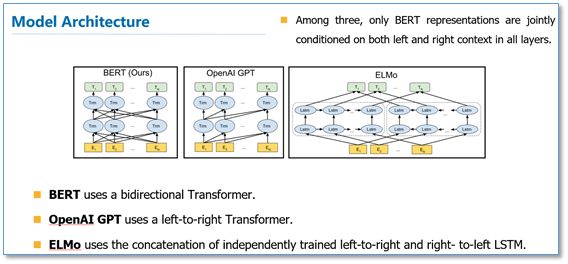
对比一下三种语言模型结构,BERT使用的是Transformer编码器,由于self-attention机制,所以模型上下层直接全部互相连接的。而OpenAI GPT使用的是Transformer解码器,它是一个需要从左到右的受限制的Transformer,而ELMo使用的是双向LSTM,虽然是双向的,但是也只是在两个单向的LSTM的最高层进行简单的拼接。所以作者们任务只有BERT是真正在模型所有层中是双向的。
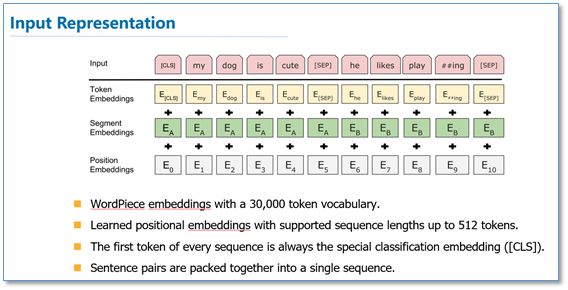
而在模型的输入方面,BERT做了更多的细节,如下图。他们使用了WordPiece embedding作为词向量,并加入了位置向量和句子切分向量。并在每一个文本输入前加入了一个CLS向量,后面会有这个向量作为具体的分类向量。
在语言模型预训练上,他们不在使用标准的从左到右预测下一个词作为目标任务,而是提出了两个新的任务。第一个任务他们称为MLM,即在输入的词序列中,随机的挡上15%的词,然后任务就是去预测挡上的这些词,可以看到相比传统的语言模型预测目标函数,MLM可以从任何方向去预测这些挡上的词,而不仅仅是单向的。但是这样做会带来两个缺点:1)预训练用[MASK]提出挡住的词后,在微调阶段是没有[MASK]这个词的,所以会出现不匹配;2)预测15%的词而不是预测整个句子,使得预训练的收敛更慢。但是对于第二点,作者们觉得虽然是慢了,但是效果提升比较明显可以弥补。

对于第一点他们采用了下面的技巧来缓解,即不是总是用[MASK]去替换挡住的词,在10%的时间用一个随机词取替换,10%的时间就用这个词本身。

而对于传统语言模型,并没有对句子之间的关系进行考虑。为了让模型能够学习到句子之间的关系,作者们提出了第二个目标任务就是预测下一个句子。其实就是一个二元分类问题,50%的时间,输入一个句子和下一个句子的拼接,分类标签是正例,而另50%是输入一个句子和非下一个随机句子的拼接,标签为负例。最后整个预训练的目标函数就是这两个任务的取和求似然。

在微调阶段,不同任务的模型如下图,只是在输入层和输出层有所区别,然后整个模型所有参数进行微调。

4.3 实验
下面我们列出一下不同NLP上BERT的效果。
GLUE结果:

QA结果:
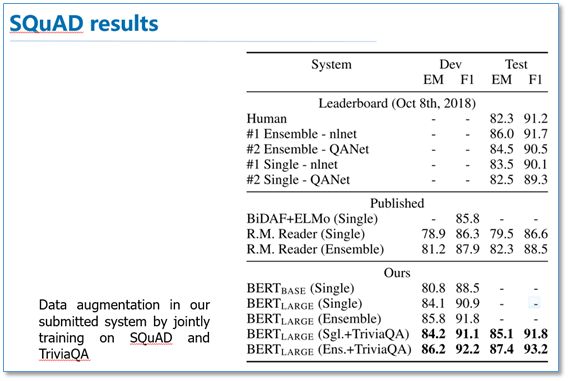
实体识别结果:

SWAG结果:

可以看到在这些所有NLP任务上,BERT都取得了SOTA,而且相比EMLo和GPT的效果提升还是比较大的。
在预训练实验分析上,可以看到本文提出的两个目标任务的作用还是很有效的,特别是在MLM这个目标任务上。
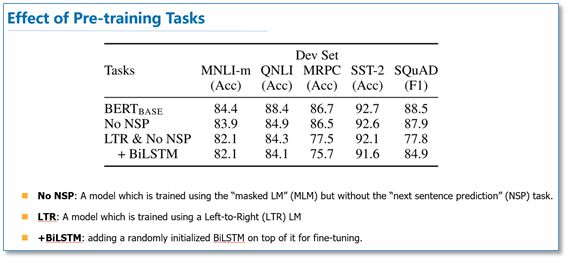
作者也做了模型规模的实验,大规模的模型效果更好,即使在小数据集上。
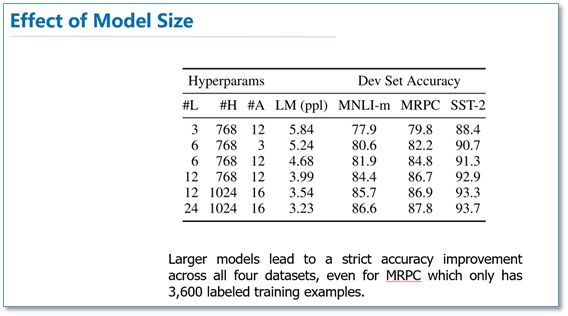
此外,作者也做了像ELMo当成特征加入的实验,从下图可以看到,当成特征加入最好效果能达到96.1%和微调的96.4%差不多,说明BERT对于基于特征和基于微调这两种方法都是有效的。

5. 总结
最后进行简单的总结,和传统的词向量相比,使用语言模型预训练其实可以看成是一个句子级别的上下文的词表示,它可以充分利用大规模的单语语料,并且可以对一词多义进行建模。而且从后面两篇论文可以看到,通过大规模语料预训练后,使用统一的模型或者是当成特征直接加到一些简单模型上,对各种NLP任务都能取得不错的效果,说明很大程度上缓解了具体任务对模型结构的依赖。在目前很多评测上也都取得了SOTA。ELMo也提供了官网供大家使用。但是这些方法在空间和时间复杂度上都比较高,特别是BERT,在论文中他们训练base版本需要在16个TGPU上,large版本需要在64个TPU上训练4天,对于一般条件,一个GPU训练的话,得用上1年。还有就是可以看出这些方法里面都存在很多工程细节,一些细节做得不好的话,效果也会大大折扣。
参考文献
[1] Peters, M. E. et al. Deep contextualized word representations. naacl (2018).
[2] Radford, A. & Salimans, T. Improving Language Understanding by Generative Pre-Training. (2018).
[3] Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. (2018).
[4] Peters, M. E., Ammar, W., Bhagavatula, C. & Power, R. Semi-supervised sequence tagging with bidirectional language models. Acl (2017).
================================================================================================================================================================================================================================================================================================================================================================================================
Transformer详解(二):Attention机制
 Max_7 关注
Max_7 关注
0.7 2019.02.12 16:29* 字数 654 阅读 1056评论 1喜欢 10
Encoder-Decoder中的attention机制
上一篇文章最后,在Encoder-Decoder框架中,输入信息的全部信息被保存在了C。而这个C很容易受到输入句子长度的影响。当句子过长时,C就有可能存不下这些信息,导致模型后续的精度下降。Attention机制对于这个问题的解决方案是在decoder阶段,每个时间点输入的C都是不一样的。而这个C,会根据当前要输出的y,去选取最适合y的上下文信息。
整体的流程如下图所示

从图上可以看出,在Decoder结构中,每一个时间点的输入都是不同的。这就是attention机制起作用的地方。对于Encoder中包含的输入内容的信息,attention机制会根据当前的输出,对Encoder中获得的输入做一个权重分配。这一点和
人类的注意力也很像。当人在翻译句子中某个词的时候,肯定也会有所针对的看原句中的对应部分,而不是把原句所有词都同等看待。
下面举一个具体的翻译的例子,
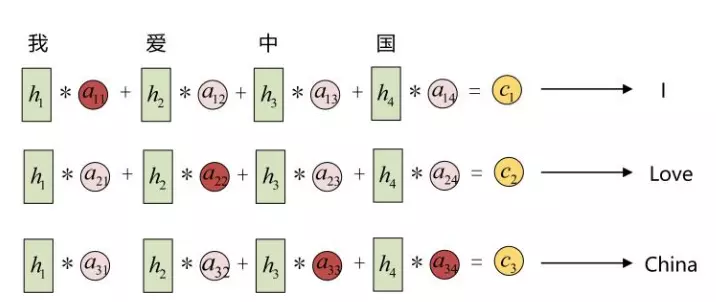
Encoder模型中的h1,h2,h3,h4可以看做是输入‘我爱中国’所代表的信息。如果不做处理的话,那么c就是一个包含h1到h4的全部信息一个状态。现在对于不同的隐状态h,配以不同的权重a。这样,在输出不同的词的时候,虽然h的值都一样,但h对应的a的值是不同的。这就会导致c是不一样的。在输出每一个y的时候,输入进来的c都是不同的。
这个过程人的注意力非常相像。以图中的翻译为例,输出的一个词 I 与中文的我关系最密切,所以h1分配的权重最大,也就是将翻译的注意力集中在h1。这里的权重a,是通过训练得来的。对于
而言,是通过decoder的上一个隐状态
和encoder的隐状态
,学习得来的。
具体到RNN模型的docoder模型来讲,在时刻i,如果要生成yi单词,我们可以得到在生成Yi之前的时刻i-1时,隐层节点i-1时刻的输出值
的,而我们的目的是要计算生成Yi时输入句子中的每个词对Yi来说的注意力分配概率分布,那么可以用Target输出句子i-1时刻的隐层节点状态
去和输入句子Source中每个单词对应的RNN隐层节点状态hj进行对比,即通过函数
来获得目标单词yi和每个输入单词对应的对齐可能性,这个F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
总结一下,对于encoder-decoder模型中的attention机制。
在decoder阶段,生成最后的输出时
...
其中,每个
包含了对于最初输入句子中每个词的注意力分配。
这里f2表示encoder模型中的变换函数。在RNN的实例中,f2的结果就是RNN模型中的隐层状态值h。
g函数通常使用求和函数。
这里的L表示了句子的长度。
以上内容就是在Encoder-Decoder结构下的attention机制。
Attention机制
如果离开上面提到的Encoder-Decoder框架,单纯的讨论attention机制,会发现attention机制的核心就是从大量的信息中有选择的选择重要信息。捕获到对当前任务有用的重要的信息。
我们把输入的内容作为source,生成的目标作为target。
source可以看成由一个一个的
Attention机制的作用就是计算每一个query,在source中的值。
整个的计算过程分成两步。
第一步,计算source中的所有的key与query的相似性,并对计算得到的全部相似性做softmax归一化处理。
第二步,根据第一步中得到的权重,对value进行加权求和。
整个计算流程如下图所示
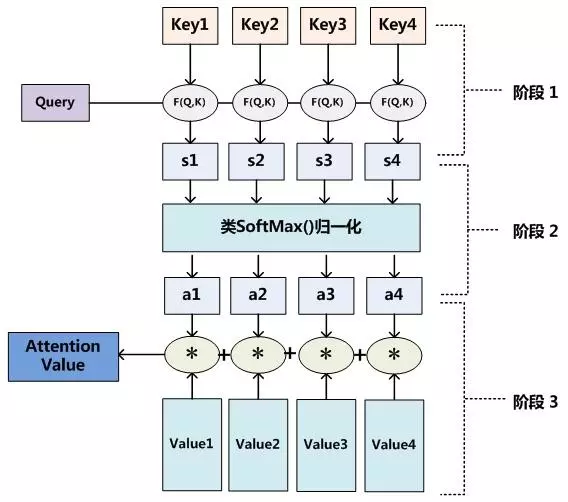
Self-Attention
在前面机器翻译的例子中,输入和输出的长度是不一样的。因为语言不通,所以句子长度通常不一样。在 self-attention中,我们可以认为source = target。 self-attention可以捕捉到句子里面的长依赖关系。
比如,对于句子
The animal didn't cross the street because it was too tired。
这里想要知道这个it代指的到底是什么,self-attention可以捕捉到句子中的长依赖关系。将其结果可视化如下图所示,
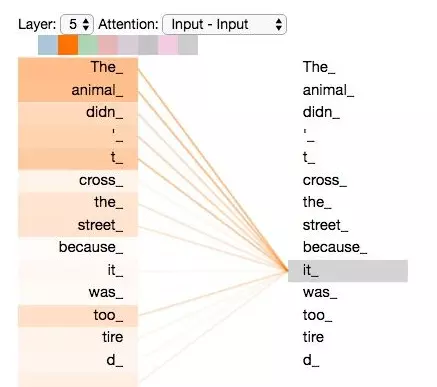
传统的RNN,LSTM网络,如果面对长句子的话,这种距离较远的依赖关系相比之下很难捕获到,因为根据RNN/LSTM的结构,需要按顺序进行序列计算,所以距离越远,关系越难捕捉。 而self-attention是针对句子中所有词两两计算,不存在距离长短这一说。此外,self-attention相比循环网络还有另外一个优点是便于并行计算。
下面将介绍self-attention的具体计算。
首先,对于每一个词向量,我们创建3个向量,分别是query,key,value。
这三个向量是词向量与训练好的权重矩阵
分别相乘得到的。
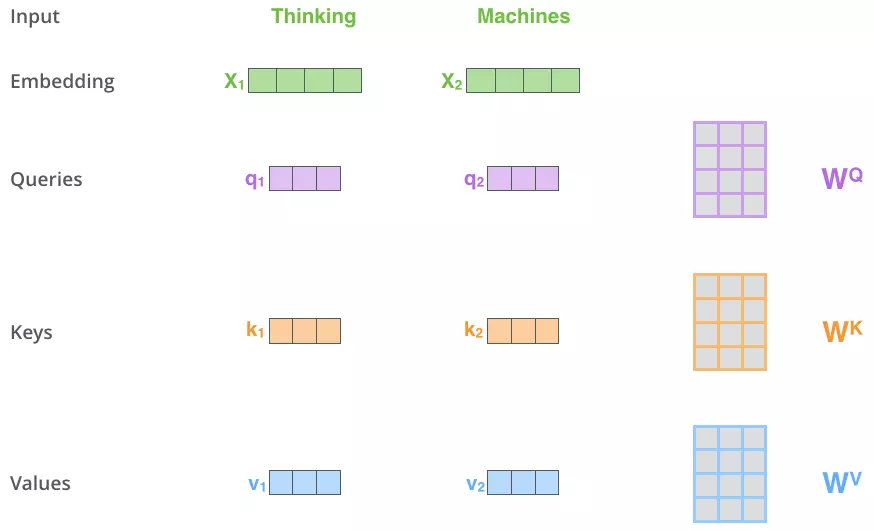
接下来,对于每个q而言,分别计算这个q与所有k的得分。计算公式
这里除以分母的作用是为了后面计算中有稳定的梯度。对于
而言,经过计算后,获得了
n为句子的长度。
下一步把这些socore进行softmax归一化。然后将归一化的结果与value向量相乘,获得最后的结果。

计算过程图
当一个词的时候,整个的计算流程就和刚才介绍的一样。那么整个这个self-attention的作用是什么呢?其实是针对输入的句子,构建了一个attention map。假设输入句子是‘I have a dream’,整个句子作为输入,矩阵运算后,会得到一个4*4的attention map。如下图所示。
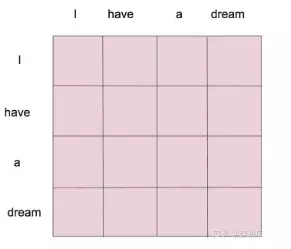
self-attention结构在Transformer结构中是非常重要的一步,这里先将其的基本过程梳理清楚。
对于Transformer结构的讲解,将在下一篇文章中详细介绍。
================================================================================================================================================================================================================================================================================================================================================================================================
-------------------------------------------------------------------------Attention------------------------------------------------------------------------------------
图解RNN、RNN变体、Seq2Seq、Attention机制
 xingzai 关注
xingzai 关注
2018.08.27 17:01* 字数 1670 阅读 410评论 0喜欢 0
本文主要是利用图片的形式,详细地介绍了经典的RNN、RNN几个重要变体,以及Seq2Seq模型、Attention机制。仅此作为个人理解笔记。
1. 从单层网络谈起
在学习RNN之前,首先要了解一下最基本的单层网络,它的结构如图:
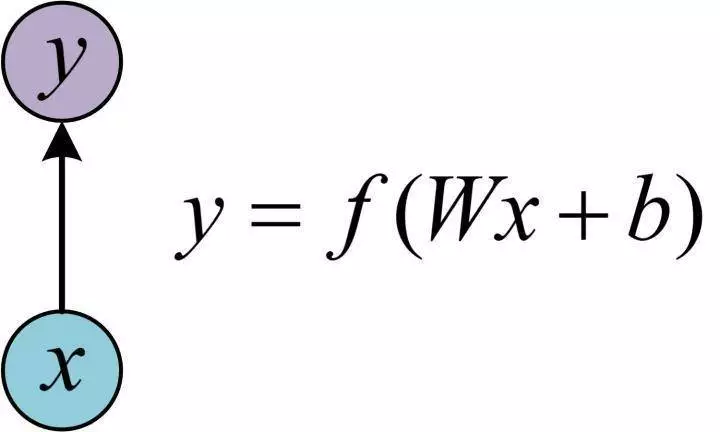
输入是x,经过变换Wx+b和激活函数f得到输出y。相信大家对这个已经非常熟悉了。
2. 经典的RNN结构(N vs N)
在实际应用中,我们还会遇到很多序列形的数据:

如:
- 自然语言处理问题。x1可以看做是第一个单词,x2可以看做是第二个单词,依次类推;
- 语音处理。此时,x1、x2、x3……是每帧的语音信号;
- 时间序列问题。例如每天的股票价格等等。
序列形的数据就不太好用原始的神经网络处理了。为了建模序列问题,RNN引入了隐状态h(hidden state)的概念,h可以对序列形的数据提取特征,接着再转换为输出。我们先从h1的计算开始看:

图示中记号的含义是:
- 圆圈或方块表示的是向量。
- 一个箭头就表示对该向量做一次变换。如上图中h0和x1分别有一个箭头连接,就表示对h0和x1各做了一次变换。
在很多论文中也会出现类似的记号,初学的时候很容易搞乱,但只要把握住以上两点,就可以比较轻松地理解图示背后的含义。
h2的计算和h1类似。要注意的是,在计算时,每一步使用的参数U、W、b都是一样的,也就是说每个步骤的参数都是共享的,这是RNN的重要特点,一定要牢记。

依次计算剩下来的(使用相同的参数U、W、b):
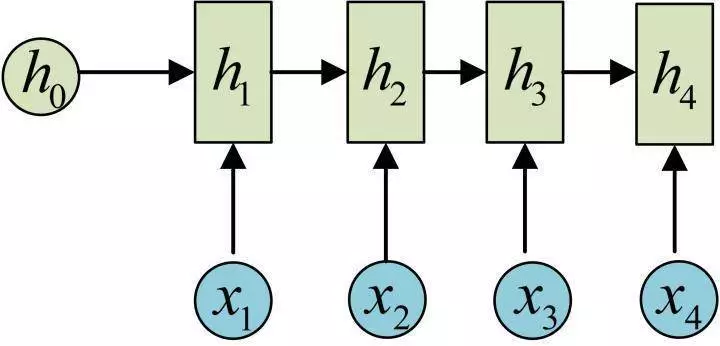
我们这里为了方便起见,只画出序列长度为4的情况,实际上,这个计算过程可以无限地持续下去。
我们目前的RNN还没有输出,得到输出值的方法就是直接通过h进行计算:

正如之前所说,一个箭头就表示对对应的向量做一次类似于f(Wx+b)的变换,这里的这个箭头就表示对h1进行一次变换,得到输出y1。
剩下的输出类似进行(使用和y1同样的参数V和c):
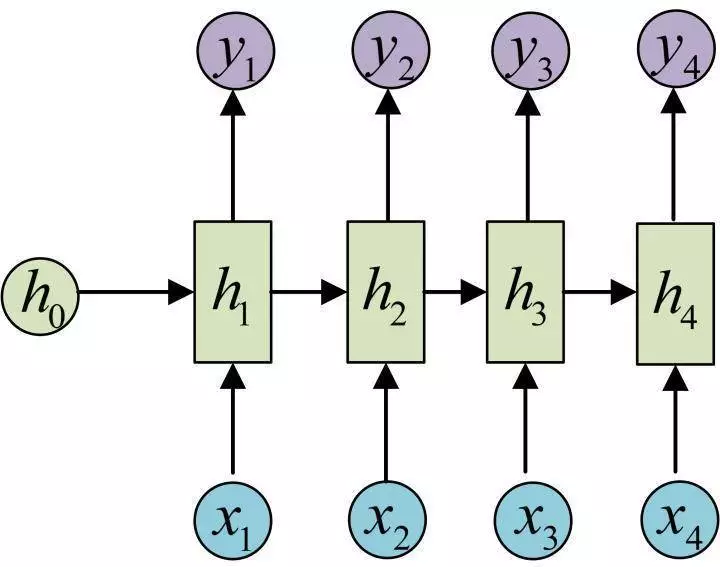
OK!大功告成!这就是最经典的RNN结构,我们像搭积木一样把它搭好了。它的输入是x1, x2, .....xn,输出为y1, y2, ...yn,也就是说,输入和输出序列必须要是等长的。
由于这个限制的存在,经典RNN的适用范围比较小,但也有一些问题适合用经典的RNN结构建模,如:
- 计算视频中每一帧的分类标签。因为要对每一帧进行计算,因此输入和输出序列等长。
- 输入为字符,输出为下一个字符的概率。这就是著名的Char RNN(详细介绍请参考:The Unreasonable Effectiveness of Recurrent Neural Networks,Char RNN可以用来生成文章,诗歌,甚至是代码,非常有意思)。
3. N VS 1
有的时候,我们要处理的问题输入是一个序列,输出是一个单独的值而不是序列,应该怎样建模呢?实际上,我们只在最后一个h上进行输出变换就可以了:
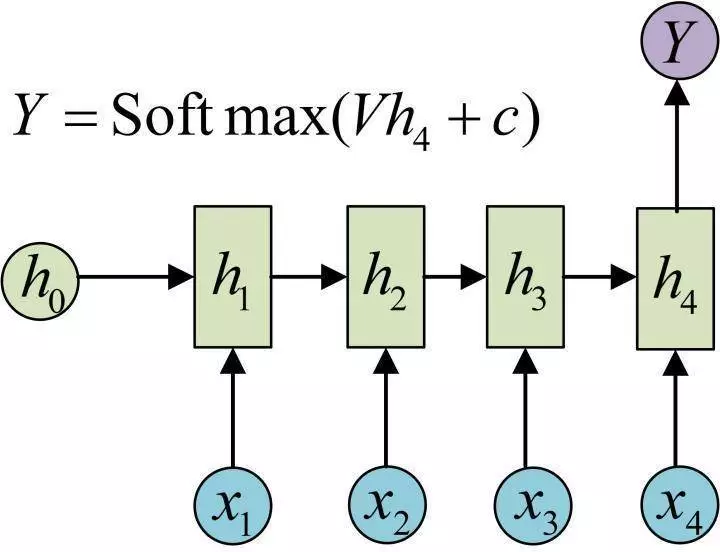
这种结构通常用来处理序列分类问题。如输入一段文字判别它所属的类别,输入一个句子判断其情感倾向,输入一段视频并判断它的类别等等。
4. 1 VS N
输入不是序列而输出为序列的情况怎么处理?我们可以只在序列开始进行输入计算:
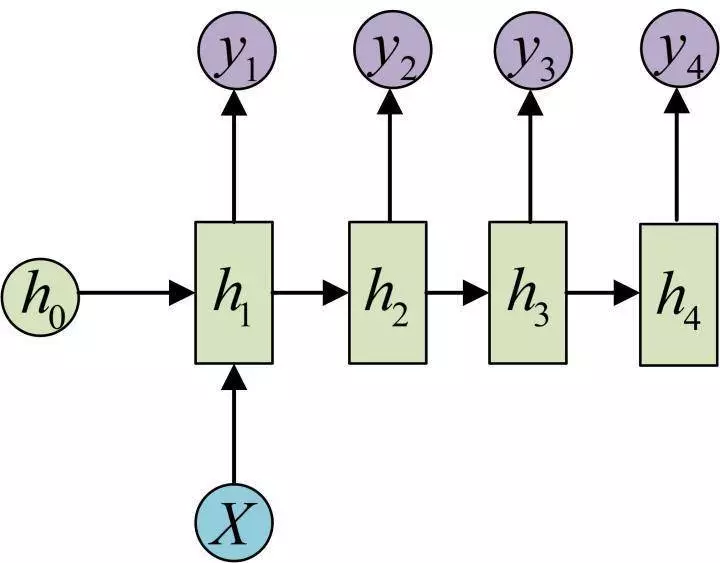
还有一种结构是把输入信息X作为每个阶段的输入:
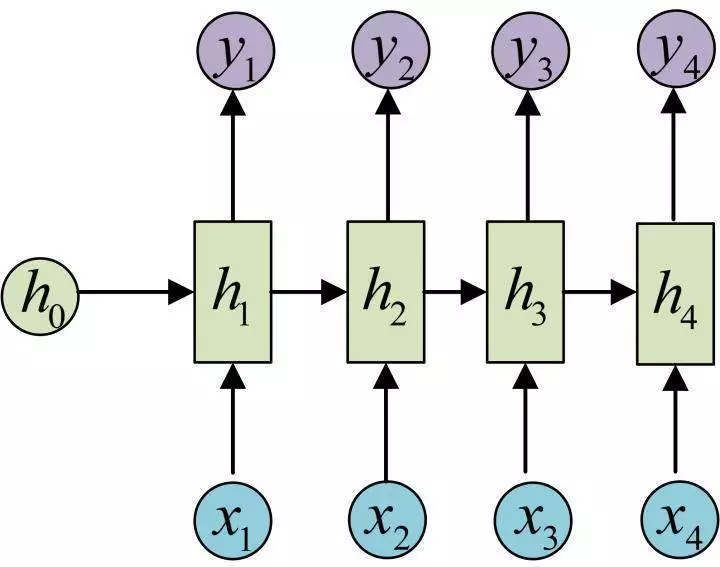
下图省略了一些X的圆圈,是一个等价表示:

这种1 VS N的结构可以处理的问题有:
- 从图像生成文字(image caption),此时输入的X就是图像的特征,而输出的y序列就是一段句子;
- 从类别生成语音或音乐等。
5. N vs M
下面我们来介绍RNN最重要的一个变种:N vs M。这种结构又叫Encoder-Decoder模型,也可以称之为Seq2Seq模型。
原始的N vs N RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
为此,Encoder-Decoder结构先将输入数据编码成一个上下文向量c:

得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
得到c之后,就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。具体做法就是将c当做之前的初始状态h0输入到Decoder中:

还有一种做法是将c当做每一步的输入:

由于这种Encoder-Decoder结构不限制输入和输出的序列长度,因此应用的范围非常广泛,比如:
- 机器翻译。
Encoder-Decoder的最经典应用,事实上这一结构就是在机器翻译领域最先提出的; - 文本摘要。输入是一段文本序列,输出是这段文本序列的摘要序列;
- 阅读理解。将输入的文章和问题分别编码,再对其进行解码得到问题的答案;
- 语音识别。输入是语音信号序列,输出是文字序列。
6. Attention机制
在Encoder-Decoder结构中,Encoder把所有的输入序列都编码成一个统一的语义特征c再解码,因此, c中必须包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个c可能存不下那么多信息,就会造成翻译精度的下降。
Attention机制通过在每个时间输入不同的c来解决这个问题,下图是带有Attention机制的Decoder:
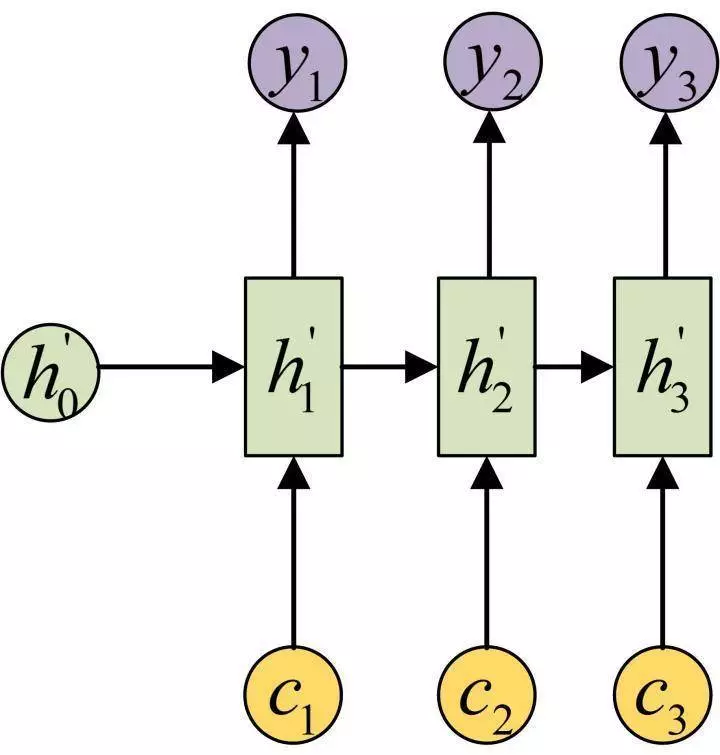
每一个 c 会自动去选取与当前所要输出的 y 最合适的上下文信息。具体来说,我们用 aij 衡量Encoder中第 j 阶段的 hj 和解码时第 i 阶段的相关性,最终Decoder中第i阶段的输入的上下文信息 ci 就来自于所有 hj 对 aij 的加权和。
以机器翻译为例(将中文翻译成英文):
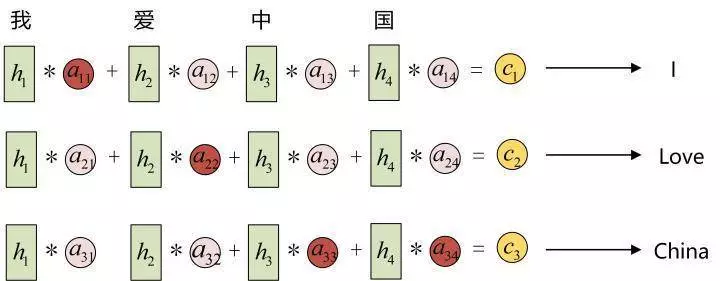
输入的序列是“我爱中国”,因此,Encoder中的h1、h2、h3、h4就可以分别看做是“我”、“爱”、“中”、“国”所代表的信息。在翻译成英语时,第一个上下文c1应该和“我”这个字最相关,因此对应的 [图片上传失败 a11 就比较大,而相应的 a12、a13 、a14 就比较小。c2应该和“爱”最相关,因此对应的 a22 就比较大。最后的c3和h3、h4最相关,因此 a33、a34 的值就比较大。
至此,关于Attention模型,我们就只剩最后一个问题了,那就是:aij 是怎么来的?
事实上,aij 同样是从模型中学出的,它实际和Decoder的第i-1阶段的隐状态、Encoder第j个阶段的隐状态有关。
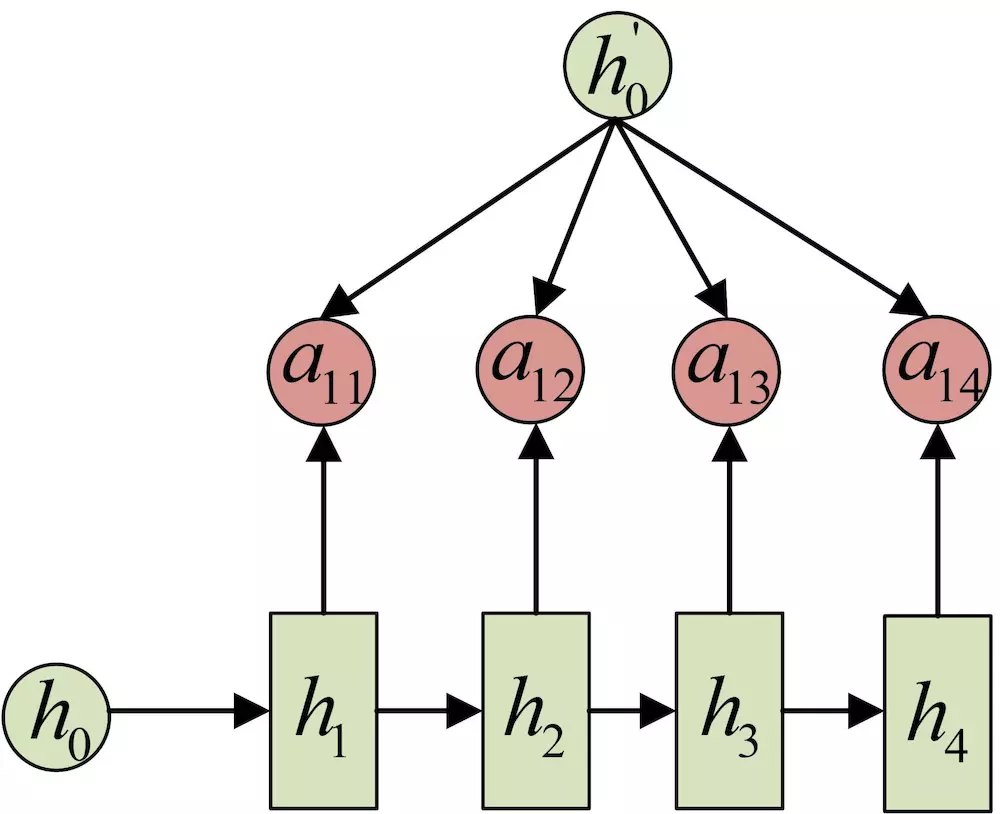
同样还是拿上面的机器翻译举例,a1j 的计算(此时箭头就表示对h'和 hj 同时做变换):

a2j 的计算:
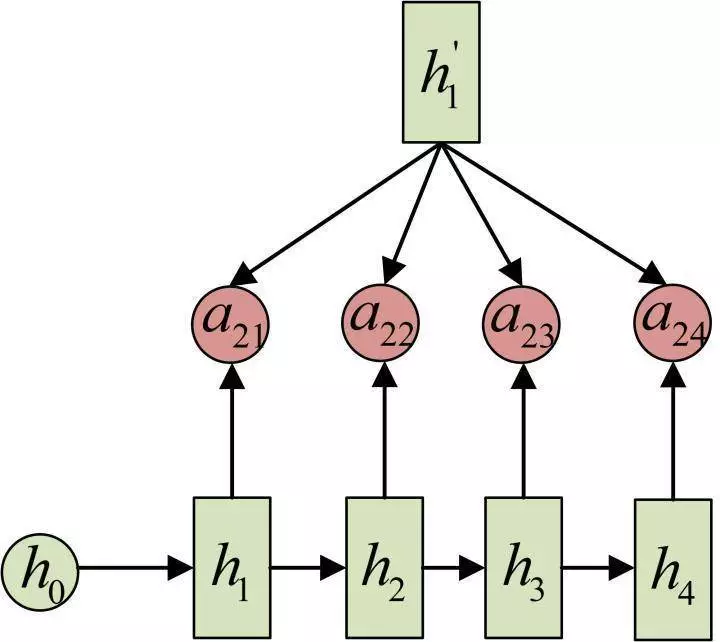
a3j 的计算:
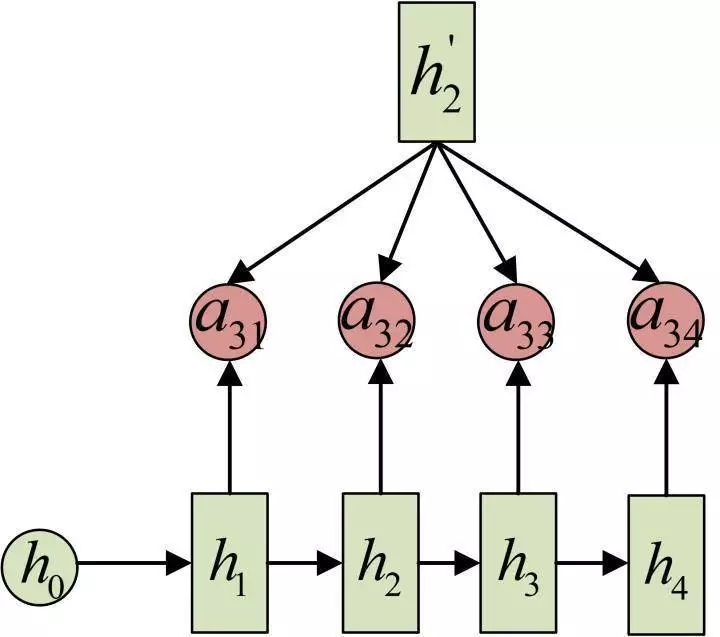
以上就是带有Attention的Encoder-Decoder模型计算的全过程。
7. 总结
本文主要讲了N vs N,N vs 1、1 vs N、N vs M四种经典的RNN模型,以及如何使用Attention结构。希望能对大家有所帮助。
可能有小伙伴发现没有LSTM的内容,其实是因为LSTM从外部看和RNN完全一样,因此上面的所有结构对LSTM都是通用的,想了解LSTM内部结构的可以参考这篇文章:Understanding LSTM Networks,写得非常好,推荐阅读。