使用Opencv的车牌识别
使用openCV识别车牌
流程框架
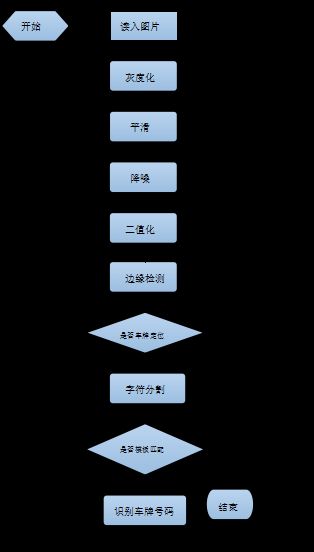
图像的预处理
车牌定位的第一步为图像预处理。为了方便计算,系统通常将获取的图片灰度化。将彩色图像转化成为灰度图像的过程就称为图像的灰度化处理。彩色图像中R、G、B三个分量的值决定了具体的像素点。一个像素点可以有上千万种颜色。而灰度图像是一种彩色图像,但是它的特点在于R、G、B三个分量具体的值是一致的。灰度图中每个像素点的变化区间是0到255,由于方便计算,所以在实际工程处理中会先将各种格式的图像转变成灰度图像。在保留图像轮廓和特征的基础上,灰度图仍然能够反映整幅图像轮廓和纹理。在Opencv里面有实现图像灰度化的接口。调用OpenCV中的cvSmooth函数进行中值滤波处理,以去除细小毛刺。

图像二值化
局部自适应二值化是针对灰度图像中的每一个像素逐点进行阈值计算,它的阈值是由像素周围点局部灰度特性和像素灰度值来确定的。局部阈值法是逐个计算图像的每个像素灰度级,保存了图像的细节信息,非均匀光照条件等情况虽然影响整个图像的灰度分布缺不影响局部的图像性质,但也存在缺点和问题,相比全局阈值法来说,它的计算时间较长,但适用于多变的环境。
设图像在像素点(x,y)处的灰度值为f(x,y),考虑以像素点(x,y)为中心的(2w+1)*(2w+1)窗口(w为窗口宽度),则局部自适应二值化算法可以描述如下:
a.计算图像中各点(x,y)的阈值w(x,y)
W(x,y)=0.5*(max f(x+m,y+n)+min f(x+m,y+n))
b.如果f(x,y)>w(x,y),则二值化结果为1,代表字符区域的目标点;否则二值化结果为0,代表背景区域的目标点。
灰度化和二值化的区别
灰度化:现在大部分的彩色图像都是采用RGB颜色模式,处理图像的时候,要分别对RGB三种分量进行处理,实际上RGB并不能反映图像的形态特征,只是从光学的原理上进行颜色的调配。
在RGB模型中,如果R=G=B时,则彩色表示一种灰度颜色,其中R=G=B的值叫灰度值,因此,灰度图像每个像素只需一个字节存放灰度值(又称强度值、亮度值),灰度范围为0-255。一般常用的是加权平均法来获取每个像素点的灰度值。
图像的预处理,加载图像、并灰度化、高斯滤波
void CMyDialog::OnLoadimage()
{
// TODO: Add your control notification handler code here
src = NULL ;
CString filePath;
CFileDialog dlg(TRUE, _T("*.bmp"),"",OFN_FILEMUSTEXIST|OFN_PATHMUSTEXIST|OFN_HIDEREADONLY,"image files (*.bmp; *.jpg) |*.bmp;*.jpg|All Files (*.*)|*.*||",NULL);
char title[]= {"Open Image"};
dlg.m_ofn.lpstrTitle= title;
if (dlg.DoModal() == IDOK) {
filePath= dlg.GetPathName();
src=cvLoadImage(filePath);
DrawPicToHDC(src,IDC_IMAGESRC);
}
pImgCanny=cvCreateImage(cvSize(src->width,src->height),IPL_DEPTH_8U,1);
cvCvtColor(src,pImgCanny,CV_RGB2GRAY);
cvSmooth(pImgCanny,pImgCanny,CV_GAUSSIAN,3,0,0); //平滑高斯滤波 滤波后的图片保存在 pImgCanny
}二值化:就是将图像上的像素点的灰度值设置为0或255,也就是将整个图像呈现出明显的只有黑和白的视觉效果。
一幅图像包括目标物体、背景还有噪声,要想从多值的数字图像中直接提取出目标物体,常用的方法就是设定一个阈值T,用T将图像的数据分成两部分:大于T的像素群和小于T的像素群。
二值化图像
void CMyDialog::Threshold(IplImage *Image, IplImage *Image_O)
{
int thresMax=0,thresMin=255,i=0,j=0,t=0;
//循环得到图片的最大灰度值和最小灰度值
for(j=0;jheight;j++)
for(i=0;iwidth;i++)
{
if(CV_IMAGE_ELEM(Image,uchar,j,i)>thresMax)
thresMax=CV_IMAGE_ELEM(Image,uchar,j,i);
else if(CV_IMAGE_ELEM(Image,uchar,j,i)uchar,j,i);
}
//小阈值用来控制边缘连接 大阈值用来控制强边缘的初始化分割
cvCanny(Image,Image_O,AdaptiveThreshold((thresMax+thresMin)*0.5,Image),thresMax*0.7,3);
} 我们来看一下图片二值化和灰度化后的区别
灰度化的图片

二值化的图片

利用carry算子实现车牌的边缘检测
Canny边缘检测是从不同视觉对象中提取有用的结构信息并大大减少要处理的数据量的一种技术,目前已广泛应用于各种计算机视觉系统。Canny发现,在不同视觉系统上对边缘检测的要求较为类似,因此,可以实现一种具有广泛应用意义的边缘检测技术。边缘检测的一般标准包括:
- 尽可能准确的捕获图像中尽可能多的边缘。
- 检测到的边缘应精确定位在真实边缘的中心。
- 图像中给定的边缘应只被标记一次,并且在可能的情况下,图像的噪声不应产生假的边缘。
Canny边缘检测算法可以分为以下5个步骤:
(1)使用高斯滤波器,以平滑图像,滤除噪声。
- 为了尽可能减少噪声对边缘检测结果的影响,所以必须滤除噪声以防止由噪声引起的错误检测。为了平滑图像,使用高斯滤波器与图像进行卷积,该步骤将平滑图像,以减少边缘检测器上明显的噪声影响。大小为(2k+1)x(2k+1)的高斯滤波器核的生成方程式由下式给出:
 大小为下面是一个sigma = 1.4,尺寸为3x3的高斯卷积核的例子(需要注意归一化):
大小为下面是一个sigma = 1.4,尺寸为3x3的高斯卷积核的例子(需要注意归一化):

若图像中一个3x3的窗口为A,要滤波的像素点为e,则经过高斯滤波之后,像素点e的亮度值为:
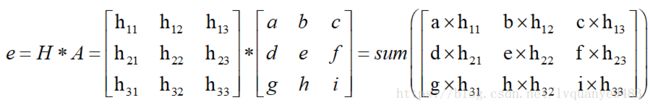 其中*为卷积符号,sum表示矩阵中所有元素相加求和。重要的是需要理解,高斯卷积核大小的选择将影响Canny检测器的性能。尺寸越大,检测器对噪声的敏感度越低,但是边缘检测的定位误差也将略有增加。一般5x5是一个比较不错的trade off。
其中*为卷积符号,sum表示矩阵中所有元素相加求和。重要的是需要理解,高斯卷积核大小的选择将影响Canny检测器的性能。尺寸越大,检测器对噪声的敏感度越低,但是边缘检测的定位误差也将略有增加。一般5x5是一个比较不错的trade off。
(2)计算图像中每个像素点的梯度强度和方向。
- 图像中的边缘可以指向各个方向,因此Canny算法使用四个算子来检测图像中的水平、垂直和对角边缘。边缘检测的算子(如Roberts,Prewitt,Sobel等)返回水平Gx和垂直Gy方向的一阶导数值,由此便可以确定像素点的梯度G和方向theta 。

其中G为梯度强度, theta表示梯度方向,arctan为反正切函数。下面以Sobel算子为例讲述如何计算梯度强度和方向。
x和y方向的Sobel算子分别为:
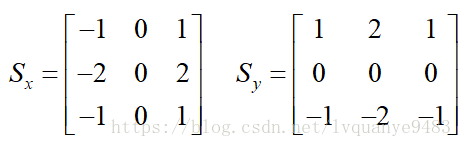
其中Sx表示x方向的Sobel算子,用于检测y方向的边缘; Sy表示y方向的Sobel算子,用于检测x方向的边缘(边缘方向和梯度方向垂直)。在直角坐标系中,Sobel算子的方向如下图所示。
若图像中一个3x3的窗口为A,要计算梯度的像素点为e,则和Sobel算子进行卷积之后,像素点e在x和y方向的梯度值分别为:

其中*为卷积符号,sum表示矩阵中所有元素相加求和。根据公式(3-2)便可以计算出像素点e的梯度和方向。
(3) 应用非极大值(Non-Maximum Suppression)抑制,以消除边缘检测带来的杂散响应。
非极大值抑制是一种边缘稀疏技术,非极大值抑制的作用在于“瘦”边。对图像进行梯度计算后,仅仅基于梯度值提取的边缘仍然很模糊。对于标准3,对边缘有且应当只有一个准确的响应。而非极大值抑制则可以帮助将局部最大值之外的所有梯度值抑制为0
对梯度图像中每个像素进行非极大值抑制的算法是:
(1)将当前像素的梯度强度与沿正负梯度方向上的两个像素进行比较。
(2)如果当前像素的梯度强度与另外两个像素相比最大,则该像素点保留为边缘点,否则该像素点将被抑制。
通常为了更加精确的计算,在跨越梯度方向的两个相邻像素之间使用线性插值来得到要比较的像素梯度,现举例如下:

如图所示,将梯度分为8个方向,分别为E、NE、N、NW、W、SW、S、SE,其中0代表00~45o,1代表450~90o,2代表-900~-45o,3代表-450~0o。像素点P的梯度方向为theta,则像素点P1和P2的梯度线性插值为:
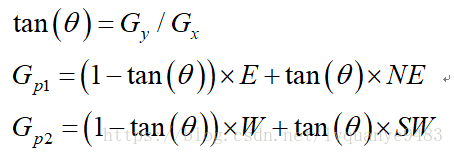
因此非极大值抑制的伪代码描写如下:
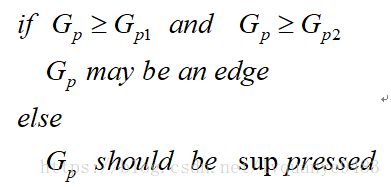
需要注意的是,如何标志方向并不重要,重要的是梯度方向的计算要和梯度算子的选取保持一致。
(4) 应用双阈值(Double-Threshold)检测来确定真实的和潜在的边缘。
- 在施加非极大值抑制之后,剩余的像素可以更准确地表示图像中的实际边缘。然而,仍然存在由于噪声和颜色变化引起的一些边缘像素。为了解决这些杂散响应,必须用弱梯度值过滤边缘像素,并保留具有高梯度值的边缘像素,可以通过选择高低阈值来实现。如果边缘像素的梯度值高于高阈值,则将其标记为强边缘像素;如果边缘像素的梯度值小于高阈值并且大于低阈值,则将其标记为弱边缘像素;如果边缘像素的梯度值小于低阈值,则会被抑制。阈值的选择取决于给定输入图像的内容。
双阈值检测的伪代码描写如下:
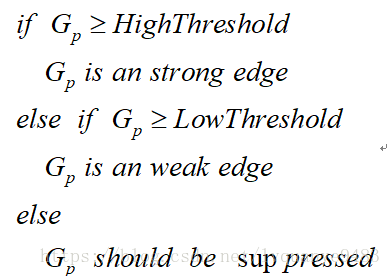
(5)通过抑制孤立的弱边缘最终完成边缘检测。
- 到目前为止,被划分为强边缘的像素点已经被确定为边缘,因为它们是从图像中的真实边缘中提取出来的。然而,对于弱边缘像素,将会有一些争论,因为这些像素可以从真实边缘提取也可以是因噪声或颜色变化引起的。为了获得准确的结果,应该抑制由后者引起的弱边缘。通常,由真实边缘引起的弱边缘像素将连接到强边缘像素,而噪声响应未连接。为了跟踪边缘连接,通过查看弱边缘像素及其8个邻域像素,只要其中一个为强边缘像素,则该弱边缘点就可以保留为真实的边缘。抑制孤立边缘点的伪代码描述如下:
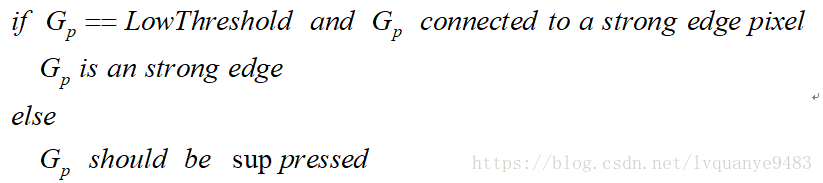
车牌位置的定位
车牌细定位的目的是为下一步字符的分割做,就是要进一步去掉车牌冗余的部分。在一幅经过适当二值化处理 含有车牌的图像中,车牌区域具有以下三个基本特征:
- 列在一个不大的区域内密集包含有多个字符;
- 车牌字符与车牌底色形成强烈对比;
- 车牌区域大小相对固定,区域长度和宽度成固定比例。
根据以上特征,车牌区域所在行相邻像素之间0 到1和1到0 的的变化会很频繁,变化总数会大于一个临界值,这可以作为寻找车牌区域的一个依据。 因此根据跳变次数与设定的阈值比较,就可以确定出车牌的水平区域。
由于车牌一般悬挂在车辆下部,所以采用从上到下,从左到右的方式对图像进行扫描。车牌的字符部分由7个字符数与两个竖直边框组成,则车牌区域内任一行的跳变次数至少为(7+2)*2=18次。从图像的底部开始向顶部进行扫描,则第一组连续数行且每行的跳变次数都大于跳变阈值,同时满足连续行数大于某个阈值。
在车牌的水平区域中,最高行与最低行的差值即为车牌在图像中的高度。我国车牌区域为矩形,宽高比约为3.14,取3.14*H作为车牌的宽度。在水平区域内选择任意一行,用L长的窗口由左至右移动,统计窗口中相邻像素0,1的跳变次数并存入数组中。若窗口移动到车牌的垂直区域时,窗口内的跳变次数应该最大。因此在数组中找到最大值,其对应的区域即为车牌的垂直区域。
车牌定位代码
int CMyDialog::PlateAreaSearch(IplImage *pImg_Image)
{
// 检测是否有值
if (pImg_Image==NULL)
{
return 0;
}
IplImage* imgTest =0;
int i=0, j=0,k=0,m=0;
bool flag=0;
int plate_n=0; //上边界
int plate_s=0; //下边界
int plate_e=0; //右边界
int plate_w=0; //左边界
int *num_h=new int[MAX(pImg_Image->width,pImg_Image->height)];
if ( num_h==NULL )
{
MessageBox("memory exhausted!");
return 0;
}
//初始化分配的空间
for(i=0;iwidth;i++)
{
num_h[i]=0;
}
imgTest = cvCreateImage(cvSize(pImg_Image->width,pImg_Image->height),IPL_DEPTH_8U,1);
cvCopy(pImg_Image, imgTest);
//--水平轮廓细化
for(j=0; jheight; j++)
{
for(i=0;iwidth-1;i++)
{
CV_IMAGE_ELEM(imgTest,uchar,j,i)=CV_IMAGE_ELEM(imgTest,uchar,j,i+1)-CV_IMAGE_ELEM(imgTest,uchar,j,i);
//记录每一行的像素值
num_h[j]+=CV_IMAGE_ELEM(imgTest,uchar,j,i)/250;
}
}
int temp_1 = 0; //统计20行中最大的每行数据量
int temp_max = 0; //20行最大的数据量
int temp_i = 0; //最大数据量的行
for(j=0; jheight-20; j++)
{
temp_1=0;
for(i=0;i<20;i++)
temp_1 += num_h[i+j];
if(temp_1>=temp_max)
{
temp_max=temp_1;
temp_i = j;
}
}
//找出上行边界行
k=temp_i;
while ( ((num_h[k +1]>POINT_X )||(num_h[k +2]>POINT_X )||(num_h[k]>POINT_X )) && k ) k--;
plate_n=k+1;
//找出下边界行
k=temp_i+10;
while (((num_h[k -1]>POINT_X )||(num_h[k-2]>POINT_X )||(num_h[k]>POINT_X ))&&(kheight)) k++;
plate_s=k;
//没找到水平分割线,设置为默认值
if ( !(plate_n && plate_s
&& (plate_nwidth*(1-WITH_X))))
{
MessageBox("水平分割失败!");
return 0;
}
//找到水平线
else
{
int max_count = 0;
int plate_length = (imgTest->width-(plate_s-plate_n)*HIGH_WITH_CAR);
plate_w=imgTest->width*WITH_X-1;//车牌宽度 默认
//--垂直方向 轮廓细化
for(i=0;iwidth;i++)
for(j=0;jheight-1;j++)
{
CV_IMAGE_ELEM(imgTest,uchar,j,i)=CV_IMAGE_ELEM(imgTest,uchar,j+1,i)-CV_IMAGE_ELEM(imgTest,uchar,j,i);
}
for(k=0;kfor(i=0; i<(int)((plate_s-plate_n)*HIGH_WITH_CAR); i++)
for (j=plate_n;j//两水平线之间
{
num_h[k] =num_h[k]+ CV_IMAGE_ELEM(imgTest,uchar,j,(i+k))/250;
}
if (num_h[k]>max_count)
{
max_count = num_h[k];
plate_w = k;
}
}
CvRect ROI_rect; //获得图片感兴趣区域
ROI_rect.x=plate_w;
ROI_rect.y=plate_n;
ROI_rect.width=(plate_s-plate_n)*HIGH_WITH_CAR;
ROI_rect.height=plate_s-plate_n;
if ((ROI_rect.width+ROI_rect.x)> pImg_Image->width)
{
ROI_rect.width=pImg_Image->width-ROI_rect.x;
MessageBox("垂直方向分割失败!");
return 0;
}
else
{
IplImage *pImg8uROI=NULL; //感兴趣的图片
pImg8uROI=cvCreateImage(cvSize(ROI_rect.width,ROI_rect.height), src->depth,src->nChannels);
IplImage *pImg8u11=NULL; //车牌区域灰度图
pImg8u11=cvCreateImage(cvSize(40*HIGH_WITH_CAR,40),pImg8uROI->depth,pImg8uROI->nChannels);
cvSetImageROI(src,ROI_rect);
cvCopy(src,pImg8uROI,NULL);
cvResetImageROI(src);
pImgResize=cvCreateImage(cvSize(40*HIGH_WITH_CAR,40),IPL_DEPTH_8U,1);
cvResize(pImg8uROI,pImg8u11,CV_INTER_LINEAR); //线性插值
cvCvtColor(pImg8u11,pImgResize,CV_RGB2GRAY);
Threshold(pImgResize,pImgResize);
cvReleaseImage(&pImg8uROI);
cvReleaseImage(&pImg8u11);
cvReleaseImage(&imgTest);
}
}
// 释放内存
delete []num_h;
num_h=NULL;
return 1;
} 车牌字符的识别
车牌字符识别是字符识别的重要组成部分。车牌字符识别的最终目的就是将图像中的车牌字符转化成文本字符,车牌字符的识别属于印刷体识别范畴。
字符识别的基本思想是匹配判别。抽取待识别字符特征按照字符识别的原理和预先存储在计算机中的标准字符模式表达形式的集合逐一进行匹配,找出最接近输入字符模式的表达形式,该表达形式对应的字就是识别结果。字符识别的原理如下:
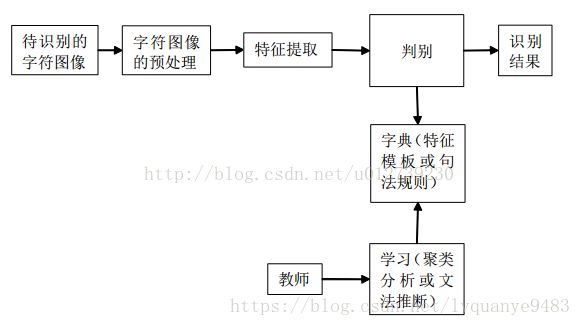
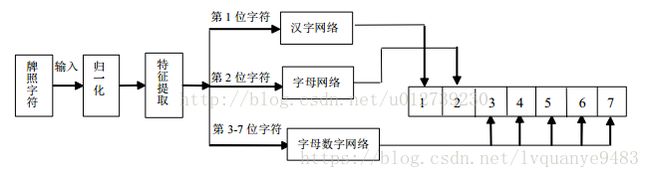
根据我国的车牌牌照标准,车牌第一位字符一般为汉字,车牌第二位英文大写字母,第三位至第七位为英文大写字母或数字。考虑到神经网络对小类别字符集有较高的识别率,因此在车牌字符识别系统中,分别设计三个神经网络:汉字网络、字母网络、字母数字网络 实现对字符的分类识别。
以字母0为例,提取字符特征的步骤为:将分割好的图片再分割成8*4的特征向量,形成一个32维的向量。最终字符特征提取的结果如下:

最终效果:

字符切割代码
int CMyDialog::SegmentPlate()
{
// 没有切割成功,直接弹出
if (pImgResize==NULL)
{
return 0;
}
int *num_h=new int[MAX(pImgResize->width,pImgResize->height)];
if ( num_h==NULL )
{
MessageBox("字符分割memory exhausted");
return 0;
}
int i=0,j=0,k=0;//循环变量 12
int letter[14]={0,20,23,43,55,75,78,98,101,121,124,127,147,167}; // 默认分割
bool flag1=0;
// 垂直投影
for(i=0;i<40*HIGH_WITH_CAR;i++)
{
num_h[i]=0; // 初始化指针
for(j=0;j<17;j++) // 0-16
{
num_h[i]+=CV_IMAGE_ELEM(pImgResize,uchar,j,i)/45;
}
for(j=24;j<40;j++) // 24-39
{
num_h[i]+=CV_IMAGE_ELEM(pImgResize,uchar,j,i)/45;
}
}
// 初定位,定位点 第二个字符末端,
int max_count=0;
int flag=0;
for(i=30;i<40*HIGH_WITH_CAR;i++)
{
if(num_h[i]if(max_count==11)
{
letter[3]=i-11;//第二字符的结束位置
while( (num_h[i]1]4]=i-1;//第三个字符的开始位置
break;
}
}
else
{
max_count=0;
}
}
// 精定位
for(i=0;i<40*HIGH_WITH_CAR;i++)
{
for(j=17;j<=24;j++)
{
num_h[i]+=CV_IMAGE_ELEM(pImgResize,uchar,j,i)/45;
}
}
for(j=letter[3];j>0;j--)//找第一个和第二个字符起始位置
{
if((num_h[j]1]2]=j; //第二个字符的开始位置
letter[1]=(j>=23)?j-3:letter[1]; //第一个字符的结束位置
letter[0]=(j>=23)?j-23:letter[0]; //第一个字符的起始位置
break;
}
}
j=2; flag=0;flag1=0;//两个标记
for(i=letter[4];i<40*HIGH_WITH_CAR;i++) //从第三个字符的开始位置算起
{
if((num_h[i]>POINT_Y)&&(num_h[i-1]>POINT_Y) && !flag )
{
flag=1;
flag1=0;
letter[2*j]=i-1; //这里 只记录字符的开始位置
if(j==6) //判断 最后一个字符的结束位置 是否越界 超出界限,如果没有,则letter[13]=letter[12]+20
{
letter[2*j+1]=((letter[2*j]+20)>40*HIGH_WITH_CAR-1)?40*HIGH_WITH_CAR-1:letter[2*j]+20;
break;
}
}
else if((num_h[i]1]//如果是 空白区域
{
flag=0;
flag1=1;
letter[2*j+1]=i-1;
j++;
}
}
// 删除角点
for(i=0;i<40*HIGH_WITH_CAR-1;i++)
{
for(j=0;j<39;j++)
{
if(CV_IMAGE_ELEM(pImgResize,uchar,j,i)&&CV_IMAGE_ELEM(pImgResize,uchar,j,i+1)&&CV_IMAGE_ELEM(pImgResize,uchar,j+1,i)) // 01
CV_IMAGE_ELEM(pImgResize,uchar,j,i)=0; // 1
if(CV_IMAGE_ELEM(pImgResize,uchar,j,i)&& CV_IMAGE_ELEM(pImgResize,uchar,j,i-1) &&CV_IMAGE_ELEM(pImgResize,uchar,j+1,i)) // 10
CV_IMAGE_ELEM(pImgResize,uchar,j,i)=0; // 1
if(CV_IMAGE_ELEM(pImgResize,uchar,j,i)&&CV_IMAGE_ELEM(pImgResize,uchar,j,i-1) &&CV_IMAGE_ELEM(pImgResize,uchar,j-1,i)) // 1
CV_IMAGE_ELEM(pImgResize,uchar,j,i)=0; // 10
if(CV_IMAGE_ELEM(pImgResize,uchar,j,i)&&CV_IMAGE_ELEM(pImgResize,uchar,j,i+1) &&CV_IMAGE_ELEM(pImgResize,uchar,j-1,i)) // 1
CV_IMAGE_ELEM(pImgResize,uchar,j,i)=0; // 01
}
}
// 分割出字符图片
pImgCharOne=cvCreateImage(cvSize(20,40),IPL_DEPTH_8U,1);
pImgCharTwo=cvCreateImage(cvSize(20,40),IPL_DEPTH_8U,1);
pImgCharThree=cvCreateImage(cvSize(20,40),IPL_DEPTH_8U,1);
pImgCharFour=cvCreateImage(cvSize(20,40),IPL_DEPTH_8U,1);
pImgCharFive=cvCreateImage(cvSize(20,40),IPL_DEPTH_8U,1);
pImgCharSix=cvCreateImage(cvSize(20,40),IPL_DEPTH_8U,1);
pImgCharSeven=cvCreateImage(cvSize(20,40),IPL_DEPTH_8U,1);
CvRect ROI_rect1;
ROI_rect1.x=0.5*(letter[1]+letter[0])-10;
ROI_rect1.y=0;
ROI_rect1.width=20;
ROI_rect1.height=40;
cvSetImageROI(pImgResize,ROI_rect1);
cvCopy(pImgResize,pImgCharOne,NULL); //获取第1个字符
cvResetImageROI(pImgResize);
ROI_rect1.x=0.5*(letter[3]+letter[2])-10;
ROI_rect1.y=0;
ROI_rect1.width=20;
ROI_rect1.height=40;
cvSetImageROI(pImgResize,ROI_rect1);
cvCopy(pImgResize,pImgCharTwo,NULL); //获取第2个字符
cvResetImageROI(pImgResize);
ROI_rect1.x=0.5*(letter[5]+letter[4])-10;
ROI_rect1.y=0;
ROI_rect1.width=20;
ROI_rect1.height=40;
cvSetImageROI(pImgResize,ROI_rect1);
cvCopy(pImgResize,pImgCharThree,NULL); //获取第3个字符
cvResetImageROI(pImgResize);
ROI_rect1.x=0.5*(letter[7]+letter[6])-10;
ROI_rect1.y=0;
ROI_rect1.width=20;
ROI_rect1.height=40;
cvSetImageROI(pImgResize,ROI_rect1);
cvCopy(pImgResize,pImgCharFour,NULL); //获取第4个字符
cvResetImageROI(pImgResize);
ROI_rect1.x=0.5*(letter[9]+letter[8])-10;
ROI_rect1.y=0;
ROI_rect1.width=20;
ROI_rect1.height=40;
cvSetImageROI(pImgResize,ROI_rect1);
cvCopy(pImgResize,pImgCharFive,NULL); //获取第5个字符
cvResetImageROI(pImgResize);
ROI_rect1.x=0.5*(letter[11]+letter[10])-10;
ROI_rect1.y=0;
ROI_rect1.width=20;
ROI_rect1.height=40;
cvSetImageROI(pImgResize,ROI_rect1);
cvCopy(pImgResize,pImgCharSix,NULL); //获取第6个字符
cvResetImageROI(pImgResize);
ROI_rect1.x=0.5*(letter[13]+letter[12])-10;
ROI_rect1.y=0;
ROI_rect1.width=20;
ROI_rect1.height=40;
cvSetImageROI(pImgResize,ROI_rect1);
cvCopy(pImgResize,pImgCharSeven,NULL); //获取第7个字符
cvResetImageROI(pImgResize);
// 释放内存
delete []num_h;
num_h=NULL;
} 字符识别代码
int CMyDialog::CodeRecognize(IplImage *imgTest, int num, int char_num)
{
if (imgTest==NULL)
{
return 0;
}
int i=0,j=0,k=0,t=0;
int char_start=0,char_end=0;
int num_t[CHARACTER ]={0};
switch(num)//这里这样分 可以提高效率,并且提高了识别率
{
case 0: char_start =0; // 数字
char_end = 9;
break;
case 1: char_start =10; // 英文
char_end = 35;
break;
case 2: char_start =0; // 英文和数字
char_end = 35;
break;
case 3: char_start =36; // 中文
char_end = TEMPLETENUM-1;
break;
default: break;
}
// 提取前8个特征
for(k=0; k<8; k++)
{
for(j=int(k/2)*10; j<int(k/2+1)*10; j++)
{
for(i=(k%2)*10;i<(k%2+1)*10;i++)
{
num_t[k]+=CV_IMAGE_ELEM(imgTest,uchar,j,i)/255 ;
}
}
// 第9个特征 前8个特征的和作为第9个特征值
num_t[8]+= num_t[k];
}
for(i=0;i<20;i++)
num_t[9]+=CV_IMAGE_ELEM(imgTest,uchar,10,i)/255 ;
for(i=0;i<20;i++)
num_t[10]+=CV_IMAGE_ELEM(imgTest,uchar,20,i)/255 ;
for(i=0;i<20;i++)
num_t[11]+=CV_IMAGE_ELEM(imgTest,uchar,30,i)/255 ;
for(j=0;j<40;j++)
num_t[12]+=CV_IMAGE_ELEM(imgTest,uchar,j,7)/255;
for(j=0;j<40;j++)
num_t[13]+=CV_IMAGE_ELEM(imgTest,uchar,j,10)/255 ;
for(j=0;j<40;j++)
num_t[14]+=CV_IMAGE_ELEM(imgTest,uchar,j,13)/255 ;
int num_tt[CHARACTER]={0};
int matchnum=0; //可以说是 匹配度或 相似度
int matchnum_max=0;
int matchcode = 0; // 匹配号
j=0;
for(k=char_start;k<=char_end;k++)
{
matchnum=0;
for(i=0;i<8;i++) //区域的匹配
{
if (abs(num_t[i]-Num_Templete[k][i])<=2)//与模板里的相应值进行匹配
matchnum++;
}
if(Num_Templete[k][i]-abs(num_t[i])<=8)//对第9个特征进行匹配
matchnum+=2;
for(i=9;i// 横竖的匹配
{
if (Num_Templete[k][i]>=5) //特征值 大于5
{
if(abs(num_t[i]-Num_Templete[k][i])<=1)
matchnum+=2;
}
else if( num_t[i]==Num_Templete[k][i])
{
matchnum+=2;
}
}
if(matchnum>matchnum_max)
{
matchnum_max=matchnum; //保留最大的 匹配
matchcode= k; //记录 识别的字符的 索引
}
}
//识别输出 存放输出结果
G_PlateChar[char_num]=PlateCode[matchcode]; //保存下该字符
} 参考:
https://blog.csdn.net/xundh/article/details/75453695
https://blog.csdn.net/qq_25343557/article/details/78703065
https://www.cnblogs.com/techyan1990/p/7291771.html
https://www.cnblogs.com/techyan1990/p/7291771.html