1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
2.用logiftic回归来进行实践操作,数据不限。
答:
1.逻辑回归是通过正规化防止过拟合的。
在训练数据不够多时,常常会导致过拟合。正则化就是在代价函数后面再加上一个正则化项,过拟合的时候,拟合函数的系数往往非常大。所以正规化通过约束参数的范数使其不要太大,所以在一定程度内可以减少过拟合。
2.
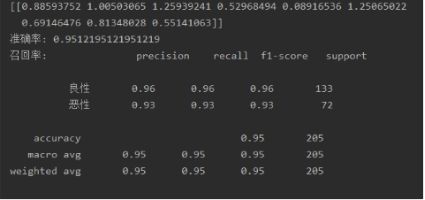
代码如下:
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
from sklearn.metrics import mean_squared_error
# 逻辑回归
def logistic():
column = ['数据编号', '属性1', '属性2', '属性3', '属性4', '属性5', '属性6', '属性7', '属性8', '属性9', '类别']
# 读取数据
data = pd.read_csv('C:\\Users\Administrator\Desktop\jiqixuexi\breast-cancer-wisconsin_6.csv', names=column)
# 缺失值处理
data = data.replace(to_replace='?', value=np.nan)
data = data.dropna()
# 数据分割
x_train, x_test, y_train, y_test = train_test_split(data[column[1:10]], data[column[10]], test_size=0.3)
# 特征值和目标值进行标准化处理(分别处理)
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 逻辑回归预测
lg = LogisticRegression()
lg.fit(x_train, y_train)
print(lg.coef_)
lg_predict = lg.predict(x_test)
print('准确率:', lg.score(x_test, y_test))
print('召回率:', classification_report(y_test, lg_predict, labels=[2, 4], target_names=['良性', '恶性']))
if __name__ == '__main__':
logistic()