【机器学习】最近邻算法KNN原理、流程框图、代码实现及优缺点
通过机器学习教学视频,初识KNN算法,对原理和算法流程通过小应用进行Python实现,有了自己的一些理解。因此在此整理一下,既是对自己学习的阶段性总结,也希望能和更多的朋友们共同交流学习相关算法,如有不完善的地方欢迎批评指正。
1、KNN算法原理
KNN,全称k-NearestNeighbor,即常说的k邻近算法。
该算法的核心思想:一个样本x与样本集中的k个最相邻的样本中的大多数属于某一个类别yLabel,那么该样本x也属于类别yLabel,并具有这个类别样本的特性。简而言之,一个样本与数据集中的k个最相邻样本中的大多数的类别相同。
由其思想可以看出,KNN是通过测量不同特征值之间的距离进行分类,而且在决策样本类别时,只参考样本周围k个“邻居”样本的所属类别。因此比较适合处理样本集存在较多重叠的场景,主要用于聚类分析、预测分析、文本分类、降维等,也常被认为是简单数据挖掘算法的分类技术之一。
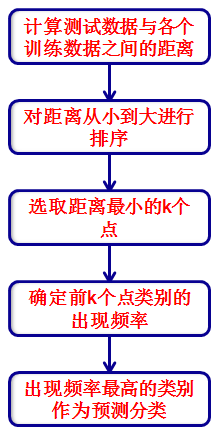
2、KNN流程框图
在建立训练集时,就要确定训练数据及其对应的类别标签;然后把待分类的测试数据与训练集数据依次进行特征比较;从训练集中挑选出最相近的k个数据,这k个数据中投票最多的分类,即为新样本的类别。
为了方便阅读算法流程,将其描述为如下流程框图:
3、KNN代码实现
参考《视觉机器学习 20讲》,整理KNN算法的伪代码如下:
Algorithm KNN(A[n], k)
{
Input: A[n]为N个训练样本的分类特征;
k为近邻个数;
Initialize:
选择A[1]至A[k]作为x的初始近邻;
计算初始近邻与测试样本x间的欧氏距离d(x, A[i]), i=1,2,...k;
按d(x, A[i])从小到大排序;
计算最远样本与x间的距离D,即max{d(x, A[j]) | j=1,2...k};
for(i=k+1; i参照麦子学院彭亮主讲机器学习课程中,KNN的Python代码,实现了KNN算法的分类功能。
import csv
import random
import math
import operator
#导入数据,并分为训练集和测试集
def loadDataset(filename, split, trainingSet = [], testSet = []):
with open(filename, 'rt') as csvfile:
lines = csv.reader(csvfile)
dataset = list(lines)
for x in range(len(dataset)-1):
for y in range(4):
dataset[x][y] = float(dataset[x][y])
if random.random() < split:
trainingSet.append(dataset[x])
else:
testSet.append(dataset[x])
#求欧拉距离
def euclideanDistance(instance1, instance2, length):
distance = 0
for x in range(length):
distance += pow((instance1[x]-instance2[x]), 2)
return math.sqrt(distance)
#计算最近邻(K个数据集),testInstance是实例
def getNeighbors(trainingSet, testInstance, k):
distances = []
length = len(testInstance)-1
for x in range(len(trainingSet)):
#testinstance
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x], dist))#distance是一个多个元组的list
#distances.append(dist)
distances.sort(key=operator.itemgetter(1))#按照dist排序
neighbors = []
for x in range(k):
neighbors.append(distances[x][0])#要的是数据集
return neighbors
#投票法找出最近邻的结果哪种最多
def getResponse(neighbors):
classVotes = {}#key--花名字 value--个数
for x in range(len(neighbors)):
response = neighbors[x][-1]
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True)
return sortedVotes[0][0]
#求出精确性
def getAccuracy(testSet, predictions):
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]:
correct += 1
return (correct/float(len(testSet)))*100.0
def main():
#prepare data
trainingSet = []
testSet = []
split = 1/3
loadDataset(r'E:\pycharmcode\irisdata.txt', split, trainingSet, testSet)
print('Train set: '+ repr(len(trainingSet)))
print('Test set: ' + repr(len(testSet)))
#generate predictions
predictions = []
k = 3
for x in range(len(testSet)):
# trainingsettrainingSet[x]
neighbors = getNeighbors(trainingSet, testSet[x], k)
result = getResponse(neighbors)
predictions.append(result)
print ('>predicted=' + repr(result) + ', actual=' + repr(testSet[x][-1]))
accuracy = getAccuracy(testSet, predictions)
print('Accuracy: ' + repr(accuracy) + '%')4、KNN算法优缺点
4.1、优点
(1)理论成熟简单,易于理解及算法实现;
(2) 可以用于多分类分类、回归等;
4.2、缺点
(1)需要计算待分类样本与所有已知样本的距离,计算量大;
(2)样本容量小或样本分布不均衡时,容易分类错误,后者可通过施加距离权重进行改善;
5、参考资料
1、《视觉机器学习 20讲》;
2、K-近邻(KNN)算法;
3、机器学习实战之kNN算法;
4、KNN(k-nearest neighbor的缩写)最近邻算法原理详解;
5、麦子学院在线课程;