pyecharts快速入门和疫情数据可视化
pyecharts快速入门和疫情数据可视化
前言
pyecharts 是基于百度echarts的一个python库,能够很好的集成python相关的前端框架,显示出来的图表也十分漂亮。是否还在烦恼matplotlib 不够漂亮?这个库让你不再烦恼。
文章目录
- pyecharts快速入门和疫情数据可视化
- 前言
- pyecharts入门
- 疫情数据可视化
- 一、导入相关工具包
- 二、数据获取
- 三、数据可视化
- 四、全部代码
- 五、总结
pyecharts入门
这里我用官网的一个例子带着大家快速入门
这是一个画柱状图的例子:首先这是一个链式调用
from pyecharts.charts import Bar
from pyecharts import options as opts
from pyecharts.globals import ThemeType
bar = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))#初始化配置项
.add_xaxis(["衬衫", "羊毛衫", "雪纺衫", "裤子", "高跟鞋", "袜子"])
.add_yaxis("商家A", [5, 20, 36, 10, 75, 90])
.add_yaxis("商家B", [15, 6, 45, 20, 35, 66])
.set_global_opts(title_opts=opts.TitleOpts(title="主标题", subtitle="副标题"))
.set_series_opts(label_opts=opts.LabelOpts(font_size=18)))
bar.render()#生成html图标
正常调用
bar = Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
bar.add_xaxis(["衬衫", "羊毛衫", "雪纺衫", "裤子", "高跟鞋", "袜子"])
bar.add_yaxis("商家A", [5, 20, 36, 10, 75, 90])
bar.add_yaxis("商家B", [15, 6, 45, 20, 35, 66])
bar.set_global_opts(title_opts=opts.TitleOpts(title="主标题", subtitle="副标题"))
bar.set_series_opts(label_opts=opts.LabelOpts(font_size=18))
bar.render()
咱们先看一下输出图片

是不是还挺好看,下面我给大家说如何通过官方api文档来进行学习!
- 官网API
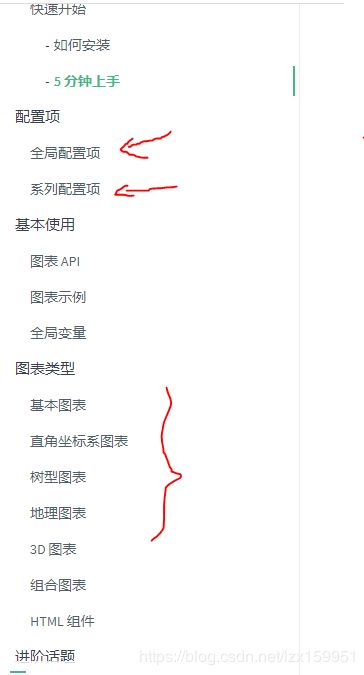
这是网页打开后最左侧的栏目。我们首先看到红箭头指向的配置项部分。
我们先打开全局配置项:

这些都是一些大体上的配置,比如图标的大小,工具栏显示等等
这些配置项的类,除了第二个初始化配置项需要写在图表初始化里的:
Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT)
就是这里。
剩下的全局配置项全部写在这里set_global_opts类里面,参数一般是x_opts = opts.XOpts():
set_global_opts(title_opts=opts.TitleOpts(title="主标题", subtitle="副标题"))
咱们再展开详细说一些,进入这个TitleOpts这个类中:

右侧的这些是这个类的一些值,如果你不去添加,很多都是默认值。就像咱们上面写的 title=‘主标题’
如果我们给这个title赋值,他就会使用这个类的默认值,从上图我们能够看到,默认值是None
接着我们看一下系列配置项:

这个配置项主要是针对文字样式、图标样式这些小一点的细节的改变
这些类方法需要写在这里set_series_opts()方法里:
set_series_opts(label_opts=opts.LabelOpts(font_size=18))
具体的学习方法和上面将的全局配置项一致,这里就不做多解释。
至于图表的具体方法学习,咱们可以通过查看这个图表类自带的一些方法,比如下图五角星处:

最后,推荐官方提供的一个pyecharts各种图表的显示,上面是代码,下面是结果,有助于我们快速使用
- Pyecharts 的项目演示
疫情数据可视化
一、导入相关工具包
from pyecharts.charts import Bar #pyecharts工具包
from pyecharts import options as opts#pyecharts操作包
import requests#获取数据
import json#编/解码json数据
import re#正则表达式匹配
import datetime#获取时间
二、数据获取
def getdata():
url='https://ncov.dxy.cn/ncovh5/view/pneumonia'
result = requests.get(url)#访问链接
today = datetime.date.today().strftime('%Y%m%d')#20200402
##result.content.decode() 更推荐使用这种方式 平常也可以使用result.text获取,但是可能会导致乱码
data = re.search(r'window.getAreaStat = (.*?)}]}catch',result.content.decode(),re.S)#非贪婪、多行匹配、对匹配大小写不敏感
data = data.group()#获取所有匹配的字符
data = data.replace('window.getAreaStat =','').replace('}catch','')#删除多余的字符
data = data.strip()#删除前后的空格
jsondata = json.loads(data)
with open('../data/'+today+'.json','w',encoding='utf-8') as f:
json.dump(jsondata,f) #注意 如果不加ensure_ascii=False 的话,汉字会转化为ascii码进行存储比如湖北省
大部分解释我都写在注释里了,这里挑一些比较重要事的进行强调
-
访问链接后,可以通过result.text 获取网页数据,但是容易出现汉字乱码的情况,这里我们一般使用result.content.decode()它会根据获取的网页内容进行自动解码。
-
re.search()是从字符串中查找,一般常用于正则表达式匹配。r‘正则表达式’ 这个r的作用就是 后面的字符串是原生字符。什么意思呢,因为在正则表达式匹配中,’\ ‘作为转义字符,如果你想要使用‘\’的话,需要写成l两个\连用。这时候,你加上r就不需要处理这种转义字符了。
-
re.S 表示 匹配所有。因为html网页中,每一行的末尾都有一个回车‘\n’符号。而进行正则表达式匹配时,默认遇到’\n’就停止匹配,所以需要我们加上re.S 把这个回车符号包含进去。当然还有其他修饰符,这里我只列出常用的:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.M | 多行匹配,影响^和$ |
| re.S | 使.匹配包含换行符在内的所有字符 |
| re.U | 根据Unicode字符解析字符 |
这里解释一下re.M,举个例子:
import re
line = "Counter12345\nICounter556"
result = re.findall( r'\d+$', line)
result1 = re.findall( r'\d+$', line,re.M)
print("不加修饰符",result)
print("加修饰符",result1)
输出:
不加修饰符 ['556']
加修饰符 ['12345', '556']
不加re.M这个修饰符,表示以这个字符串为整体,来定位开始和结束
加上re.M这个修饰符,表示以每一行作为字符串的开始和结束。
-
json.dump()将json写入到文件中,这里面有个参数 ensure_ascii。若这个参数为False,表示json中的汉字不会被编码成ascii码。默认值为True
-
部分数据
[{"provinceName": "湖北省", "provinceShortName": "湖北", "currentConfirmedCount": 1283, "confirmedCount": 67802, "suspectedCount": 0, "curedCount": 63326, "deadCount": 3193, "comment": "", "locationId": 420000, "statisticsData": "https://file1.dxycdn.com/2020/0223/618/3398299751673487511-135.json"
三、数据可视化
这里我们使用pyecharts的地图图表作为显示。
def datashow():
#数据处理
today = datetime.date.today().strftime('%Y%m%d')
with open('../data/'+today+'.json','r',encoding='utf8')as f:
jsondata = json.load(f)
listprovince = []
listcount = []
for data in jsondata:
listprovince.append(data['provinceShortName'])
listcount.append(data['confirmedCount'])
pieces = [
{'min': 10000, 'color': '#540d0d'},
{'max': 9999, 'min': 1000, 'color': '#9c1414'},
{'max': 999, 'min': 500, 'color': '#d92727'},
{'max': 499, 'min': 100, 'color': '#ed3232'},
{'max': 99, 'min': 10, 'color': '#f27777'},
{'max': 9, 'min': 1, 'color': '#f7adad'},
{'max': 0, 'color': '#f7e4e4'},
]
map = Map()
map.add('疫情数据可视化',[list(z) for z in zip(listprovince,listcount)],'china')
map.set_global_opts(visualmap_opts=opts.VisualMapOpts(pieces=pieces,is_piecewise=True,is_show=True),
legend_opts=opts.LegendOpts(is_show=False))
map.render()
输出结果:
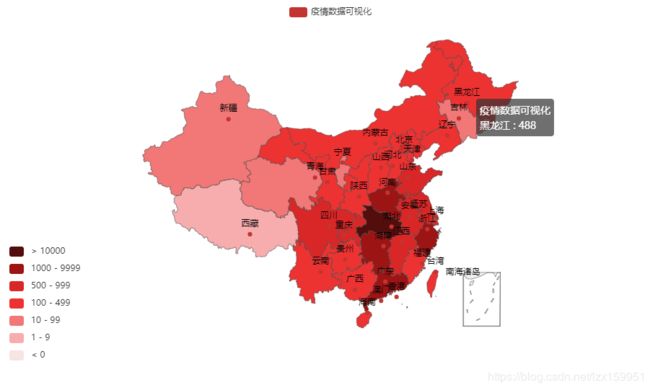
下面就针对代码的一些重点进行一下讲解:
-
获取前面保存的json文件,要记得声明编码格式
-
通过遍历,将每个省份的名字和确诊数字分别存入数组中。注意,这里要使用简称,比如河北省,我们不能使用全程,要使用河北,要不然pyecharts不识别,无法映射
-
实例化map对象,通过add方法添加label和数据。注意数据的格式 应该是
[('湖北',22334),('河北','234')]zip这个函数是将列表存储成上述这样的格式,举个例子
a = ['a','b','c'] b = ['d','e','f'] for data in zip(a,b): print(data)输出结果:
('a', 'd') ('b', 'e') ('c', 'f') -
add()方法的第三个参数是显示什么地图,若填入’china‘显示中国地图,填入’广东’则显示广东省地图。
-
接着就是设置一些全局配置项
-
render()是将map 渲染成html保存下来,默认路径是path=render.html
-
可以渲染成图片,不过需要安装snapshot_selenium和下载chrome驱动
from snapshot_selenium import snapshot from pyecharts.render import make_snapshot from selenium import webdriver option = webdriver.ChromeOptions()#设置无头模式 option.add_argument('headless') webdriver.Chrome(options=option) make_snapshot(snapshot, map.render(), "map.png")- 可以通过 pip install snapshot_selenium 安装snapshot_selenium
- 下载chrome驱动,配置环境变量 参考:pyecharts渲染图片
四、全部代码
from pyecharts.render import make_snapshot
from snapshot_selenium import snapshot
from selenium import webdriver
from pyecharts.charts import Map
from pyecharts import options as opts
import requests
import json
import re
import datetime
def getdata():
url='https://ncov.dxy.cn/ncovh5/view/pneumonia'
result = requests.get(url)
today = datetime.date.today().strftime('%Y%m%d')
##result.content.decode() 更推荐使用这种方式 平常也可以使用result.text获取,但是可能会导致乱码
data = re.search(r'window.getAreaStat = (.*?)}]}catch',result.content.decode(),re.S)#非贪婪、多行匹配、对匹配大小写不敏感
data = data.group()#获取所有匹配的字符
data = data.replace('window.getAreaStat =','').replace('}catch','')#删除多余的字符
data = data.strip()#删除前后的空格
print(data)
jsondata = json.loads(data)
with open('../data/'+today+'.json','w',encoding='utf8') as f:
json.dump(jsondata,f,ensure_ascii=False) #注意 如果不加ensure_ascii=False 的话,汉字会转化为ascii码进行存储比如湖北省
def datashow():
option = webdriver.ChromeOptions()
option.add_argument('headless')
webdriver.Chrome(options=option)
#数据处理
today = datetime.date.today().strftime('%Y%m%d')
with open('../data/'+today+'.json','r',encoding='utf8')as f:
jsondata = json.load(f)
listprovince = []
listcount = []
print(jsondata)
for data in jsondata:
listprovince.append(data['provinceShortName'])
listcount.append(data['confirmedCount'])
print(listprovince)
print(listcount)
pieces = [
{'min': 10000, 'color': '#540d0d'},
{'max': 9999, 'min': 1000, 'color': '#9c1414'},
{'max': 999, 'min': 500, 'color': '#d92727'},
{'max': 499, 'min': 100, 'color': '#ed3232'},
{'max': 99, 'min': 10, 'color': '#f27777'},
{'max': 9, 'min': 1, 'color': '#f7adad'},
{'max': 0, 'color': '#f7e4e4'},
]
map = Map()
map.add('疫情数据可视化',[list(z) for z in zip(listprovince,listcount)],'china')
map.set_global_opts(visualmap_opts=opts.VisualMapOpts(pieces=pieces,is_piecewise=True,is_show=True),
legend_opts=opts.LegendOpts(is_show=False))
make_snapshot(snapshot,map.render(),"D:\\python\\Future_data\\data\\map.png")
if __name__ == '__main__':
getdata()
datashow()
五、总结
通过这个项目的实战,我们学到了pyecharts的基本用法以及json处理相关操作。希望大家能够在次基础上多去练习。走的时候留个