python--爬虫(2)bs4模块
1. BS4简介
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个
工具箱,通过解析文档为tiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。
你不需要考虑编码方式,除非文档没有指定一个编一下原始编码方式就可以了。
2. BS4的4种对象
2-1. BeautifulSoup对象
2-2. Tag对象
Tag就是html中的一个标签,用BeautifulSoup就能解析出来Tag的具体内容,
具体的格式为soup.name,其中name是html下的标签。
2-3.NavigableString
2-4.评论
参考文章:https://blog.csdn.net/qq_42543301/article/details/81253184
import re
from bs4 import BeautifulSoup
html = """
story12345
The Dormouse's story
Once upon a time there were three little sisters; and their names were
westos,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html, 'html.parser')
# print(soup.prettify())
# 1. 根据标签获取内容;
******************标签的常用属性************************
# 根据格式化, 如果title只有一个, 根据标签可以获取
print(soup.title)
print(type(soup.title))
print(soup.title.name) # 标签的名称
# 获取标签里面的属性信息
print(soup.a.attrs)
print(soup.a.attrs['href'])
# *******************标签常用的方法*************************
#get方法用于得到标签下的属性值,注意这是一个重要的方法,在许多场合都能用到,比如你要得到 标签下的图像url,那么就可以用soup.img.get(‘src’)
print(soup.a.get('href'))
print(soup.a.get('class'))
# string得到标签下的文本内容,只有在此标签下没有子标签,或者只有一个子标签的情况下才能返回其中的内容,否则返回的是None;
# get_text()可以获得一个标签中的所有文本内容,包括子孙节点的内容,这是最常用的方法
print(soup.a.string) # 标签里面的内容
print(soup.a.get_text())
# *******************对获取的属性信息进行修改***********************
print(soup.a.get('href'))
soup.a['href'] = 'http://www.baidu.com'
print(soup.a.get('href'))
print(soup.a)
# 2. 面向对象的匹配
# 查找符合条件的所有标签;
aTagObj = soup.find_all('a')
print(aTagObj)
for item in aTagObj:
print(item)
需求: 获取所有的a标签, 并且类名为"sister"
aTagObj = soup.find_all('a', class_="sister")
print(aTagObj)
# 3. 根据内容进行匹配
print(soup.find_all(text="story"))
print(soup.find_all(text=re.compile('story\d+')))
标签下的图像url,那么就可以用soup.img.get(‘src’)
print(soup.a.get('href'))
print(soup.a.get('class'))
# string得到标签下的文本内容,只有在此标签下没有子标签,或者只有一个子标签的情况下才能返回其中的内容,否则返回的是None;
# get_text()可以获得一个标签中的所有文本内容,包括子孙节点的内容,这是最常用的方法
print(soup.a.string) # 标签里面的内容
print(soup.a.get_text())
# *******************对获取的属性信息进行修改***********************
print(soup.a.get('href'))
soup.a['href'] = 'http://www.baidu.com'
print(soup.a.get('href'))
print(soup.a)
# 2. 面向对象的匹配
# 查找符合条件的所有标签;
aTagObj = soup.find_all('a')
print(aTagObj)
for item in aTagObj:
print(item)
需求: 获取所有的a标签, 并且类名为"sister"
aTagObj = soup.find_all('a', class_="sister")
print(aTagObj)
# 3. 根据内容进行匹配
print(soup.find_all(text="story"))
print(soup.find_all(text=re.compile('story\d+')))
爬取个人博客,去掉广告的导航栏
import requests
from bs4 import BeautifulSoup
def get_content(url):
try:
user_agent = "Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0"
response = requests.get(url,headers={'User-Agent':user_agent})
response.raise_for_status() #如果返回的状态码不是200.则抛出异常
response.encoding = response.apparent_encoding
# 判断网页的编码格式 便于response.text知道如何解码
except Exception as e :
print('爬取错误')
else:
# print(response.text)
print(response.url)
print('爬取成功!')
return response.text
def parser_content(htmlContent):
# 实例化soup对象 便于处理
soup = BeautifulSoup(htmlContent,'html.parser')
# 提取页面头部信息,解决乱码问题
headObj = soup.head
# 提取需要的内容
divObj = soup.find_all('div',class_='blog-content-box')[0]
with open('csdn.html','w') as f:
f.write(str(headObj))
f.write(str(divObj))
print('下载成功.....')
if __name__ == '__main__':
url ='https://blog.csdn.net/m0_37206112/article/details/86602296'
content = get_content(url)
parser_content(content)
个人博客整理
import requests
from bs4 import BeautifulSoup
def get_content(url):
try:
user_agent = "Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0"
response = requests.get(url,headers={'User-Agent':user_agent})
response.raise_for_status() #如果返回的状态码不是200.则抛出异常
response.encoding = response.apparent_encoding
# 判断网页的编码格式 便于response.text知道如何解码
except Exception as e :
print('爬取错误')
else:
# print(response.text)
print(response.url)
print('爬取成功!')
return response.text
def parser_content(htmlContent):
# 实例化soup对象,便于处理
soup = BeautifulSoup(htmlContent,'html.parser')
divObjs = soup.find_all('div',class_='article-item-box')
for divObj in divObjs[1:]:
title = divObj.h4.a.get_text().split()[1]
# blogText = re.sub(r'r/s+','',title)
blogUrl = divObj.h4.a.get('href')
global bloginfo
bloginfo.append((title,blogUrl))
# print(title,blogUrl)
# print("*************")
if __name__ == '__main__':
blogPage = 3
bloginfo =[]
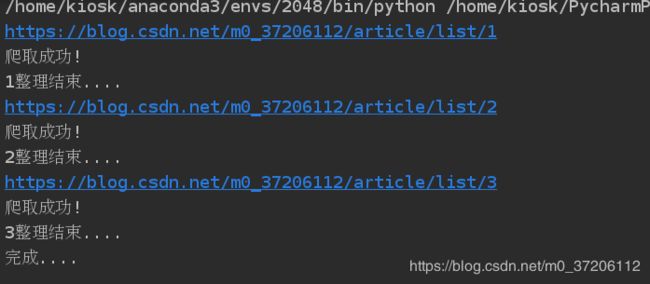
for page in range(1,blogPage+1):
url ='https://blog.csdn.net/m0_37206112/article/list/%s' %(page)
content = get_content(url)
parser_content(content)
print('%d整理结束....' %(page))
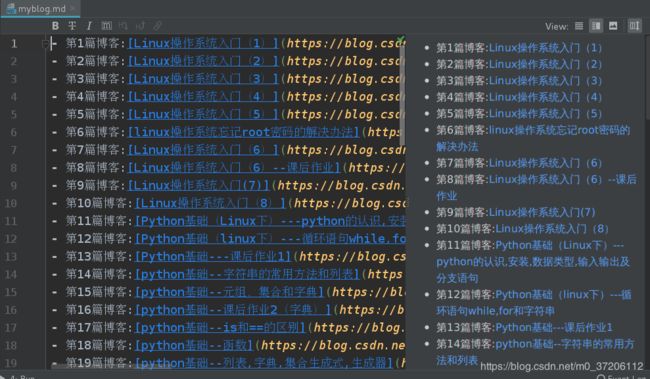
with open('myblog.md','a') as f:
for index,info in enumerate(bloginfo[::-1]):
f.write('- 第%d篇博客:[%s](%s)\n' %(index+1,info[0],info[1]))
print('完成....')
爬取豆瓣电影top250信息
爬取完成很并将其存入表格中
import re
import requests
from bs4 import BeautifulSoup
def get_content(url,):
try:
user_agent = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36"
response = requests.get(url, headers={'User-Agent': user_agent})
response.raise_for_status() # 如果返回的状态码不是200, 则抛出异常;
response.encoding = response.apparent_encoding # 判断网页的编码格式, 便于respons.text知道如何解码;
except Exception as e:
print("爬取错误")
else:
print(response.url)
print("爬取成功!")
return response.content
def parser_content(htmlContent):
# 实例化soup对象, 便于处理;
soup = BeautifulSoup(htmlContent, 'html.parser')
# 1). 电影信息存储在ol标签里面的li标签:
#
olObj = soup.find_all('ol', class_='grid_view')[0]
# 2). 获取每个电影的详细信息, 存储在li标签;
details = olObj.find_all('li')
for detail in details:
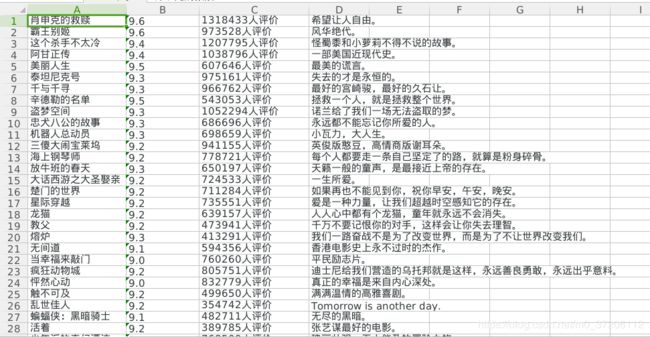
# # 3). 获取电影名称;
movieName = detail.find('span', class_='title').get_text()
# 4). 电影评分:
movieScore = detail.find('span', class_='rating_num').get_text()
# 5). 评价人数***************
# 必须要转换类型为字符串
movieCommentNum = str(detail.find(text=re.compile('\d+人评价')))
# 6). 电影短评
movieCommentObj = detail.find('span', class_='inq')
if movieCommentObj:
movieComment = movieCommentObj.get_text()
else:
movieComment = "无短评"
movieInfo.append((movieName, movieScore, movieCommentNum, movieComment))
import openpyxl
def create_to_excel(wbname, data, sheetname='Sheet1', ):
"""
将制定的信息保存到新建的excel表格中;
:param wbname:
:param data: 往excel中存储的数据;
:param sheetname:
:return:
"""
print("正在创建excel表格%s......" % (wbname))
# wb = openpyxl.load_workbook(wbname)
# 如果文件不存在, 自己实例化一个WorkBook的对象;
wb = openpyxl.Workbook()
# 获取当前活动工作表的对象
sheet = wb.active
# 修改工作表的名称
sheet.title = sheetname
# 将数据data写入excel表格中;
print("正在写入数据........")
for row, item in enumerate(data): # data发现有4行数据, item里面有三列数据;
print(item)
for column, cellValue in enumerate(item):
# cell = sheet.cell(row=row + 1, column=column + 1, value=cellValue)
cell = sheet.cell(row=row+1, column=column + 1)
cell.value = cellValue
wb.save(wbname)
print("保存工作薄%s成功......." % (wbname))
if __name__ == '__main__':
doubanTopPage = 2
perPage = 25
# [(), (), ()]
movieInfo = []
# 1, 2, 3 ,4, 5
for page in range(1, doubanTopPage+1):
# start的值= (当前页-1)*每页显示的数量(25)
url = "https://movie.douban.com/top250?start=%s" %((page-1)*perPage)
content = get_content(url)
parser_content(content)
create_to_excel('/tmp/hello.xlsx', movieInfo, sheetname="豆瓣电影信息")
进行测试只爬取两页 可自行对数据进行修改测试全部
bs4模块补充
import re
from bs4 import BeautifulSoup
html = """
story12345
The Dormouse's story
Once upon a time there were three little sisters; and their names were
westos,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
#
soup = BeautifulSoup(html, 'html.parser')
# 需要安装第三方模块lxml;
# soup = BeautifulSoup(html, 'lxml')
# 1. 返回符合条件的第一个标签内容
print(soup.title)
print(soup.p)
print(soup.find('p', class_=re.compile(r'^ti.*?')))
# 2. 返回符合条件的所有标签内容
print(soup.find_all('p'))
print(soup.find_all('p', class_='title', text=re.compile(r'.*?story.*?')))
# 3. 获取符合条件的p标签或者a标签
print(soup.find(['title', 'a']))
print(soup.find_all(['title', 'a']))
print(soup.find_all(['title', 'a'], class_=['title', 'sister']))
# 4. CSS匹配
# 标签选择器
print(soup.select("title"))
# 类选择器(.类名)
print(soup.select(".sister"))
# id选择器(#id名称)
print(soup.select("#link1"))
# 此处不支持正则表达式;
# print(soup.select(re.compile("#link\d+")))
# 属性选择器()
print(soup.select("input[type='password']"))
bs4模块的解析器
官方中文文档: https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
下表列出了主要的解析器,以及它们的优缺点:
解析器:使用方法:优势:劣势
Python标准库
BeautifulSoup(markup, "html.parser")
Python的内置标准库
执行速度适中
文档容错能力强
Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差
lxml
HTML 解析器 BeautifulSoup(markup, "lxml")
速度快
文档容错能力强
需要安装C语言库
lxml
XML 解析器
BeautifulSoup(markup, ["lxml-xml"])
BeautifulSoup(markup, "xml")
速度快
唯一支持XML的解析器
需要安装C语言库
html5lib
BeautifulSoup(markup, "html5lib")
最好的容错性
以浏览器的方式解析文档
生成HTML5格式的文档
速度慢
不依赖外部扩展