NLP之NER
最近在研究nlp中的命名实体识别,针对读过的一些文章在此做个总结。
对于NER的方法,主要分为两大类:基于规则的方法和基于统计的方法。
(1)基于规则的方法更接近人的思维,例如,针对人名常见的规则:<姓氏>+<名字>、针对地名常见的规则:<地方部分>+<地方指示词>、针对组织名常见的规则:{[人名][地名][组织名][其他专有名词]}+[组织类型]+<组织名指示词>。基于规则的方法往往与知识密不可分,因此此类系统往往需要语言专家的参与,这也限制了基于规则的方法的发展。
(2)基于统计的方法利用原始或者人工标注的语料进行训练,而语料不需要特定领域的专家参与就可以完成标注。目前,常用到的基于统计的模型有:HMM(隐马尔科夫模型)、SVM(支持向量机)、CRF(条件随机场)、最大熵模型等等。
本篇文章主要介绍了BLSTM在命名实体识别中的应用。结构如下,第一节介绍传统的BLSTM,第二节结合NER介绍双向BLSTM。
一、传统的LSTM
开门见山,直接介绍LSTM,关于其前身RNN还请在百度上自行检索。
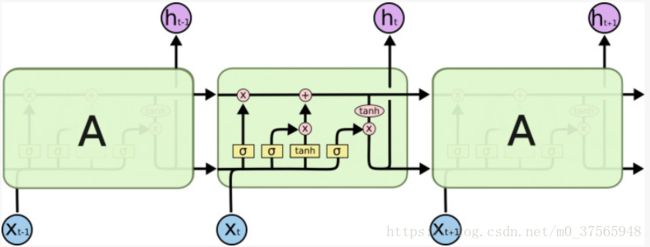
上图为LSTM的交互模块,其核心在于添加了cell状态,也就是图中最上面的一条线。cell就想传送带沿着整条链传送,记录历史的信息。LSTM通过三个名字为门的结构控制cell状态。
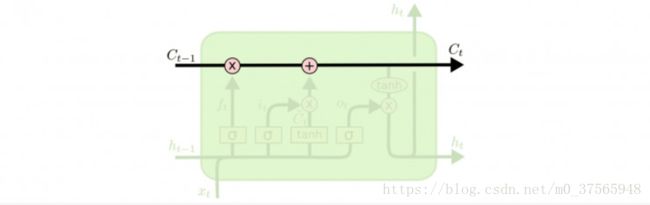
如上图所示,ft(遗忘门)、it(输入门)、ot (输出门)三个门来控制cell的状态。
(1)ft(遗忘门):这一步决定从cell中抛弃哪些信息,因为cell中不可能保存所有历史数据,这样不仅会造成运算数据量庞大,还会使传输的数据携带一些噪音,不利于最终结果的运算。
(2)it(输入门):这一步与输入相连,决定哪些输入信息会存储到cell中,即向cell中存储信息。
(3)ot (输出门):该步骤的输出分为两部分,一部分流入写一个计算单元,另一部分作为该xi的的特征表示输出。
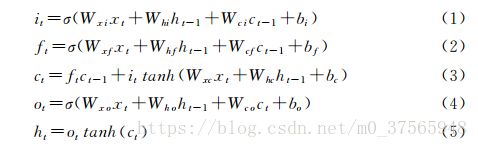
上图中的计算公式为LSTM隐藏层的输出表示h的具体计算过程。
W表示连接两层的权重矩阵(如Wxi表示输入层到隐藏层的输入门的权重矩阵);
b表示偏置向量(如bi表示隐藏层的输入门的偏置向量);
c表示记忆单元的状态;
sigmod和tanh表示两种不同的激活函数
i、o、f分别代表输入门、输出门、遗忘门
参考文章点击打开链接
二、结合NER的BLSTM
LSTM解决了RNN中长期依赖的问题,但是其只考虑了语料的上文信息,而命名实体识别不仅需要考虑上文信息,还需考虑下文信息,故BLSTM是一个非常好的选择。
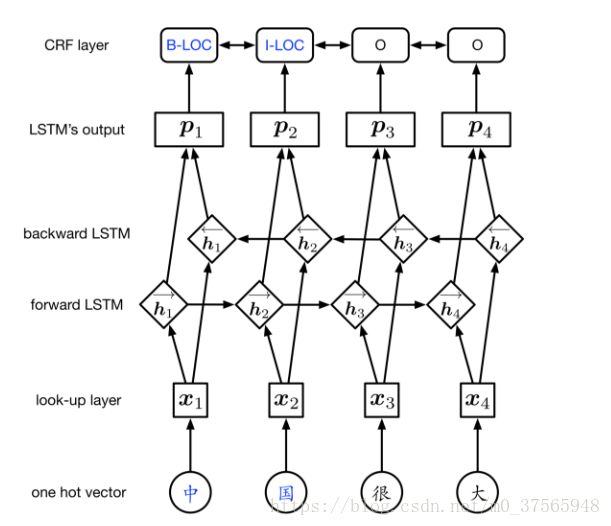
BLSTM的架构如上图所示,x1、x2等表示文本的向量输入,h→t为前向 LSTM 在t时刻的输出表 示,h←t 为 反 向 LSTM 在t时刻的输出表示。, 则BLSTM 在t时刻的输出表示定义为ht= [h→t:h←t],即直接拼接h→t与h←t. 这种表示同时包含了上文信息和下文信息,适用于标签种类较多的命名实体识别任务 。
命名实体识别任务的标签之间并不是独立的,而是具有较强的依赖关系,例如B-PER后面可能是I-PER或E-PER而不可能是I-LOC标签。因此做命名实体识别的时候,不仅要依据BLSTM的预测结果h,还应考虑标签间的约束关系。
即对于给定词语序列 Sx=A+P,A为标签间的约束关系,P为BLSTM得到的预测概率。
当需要将领域知识融入到NER的model中时,具体的做法是将小规模的领域实体字典融入到模型的代价函数中当输入词语为词典的命名实体时,正确的可能性得分Sx应当变大。借鉴其他人的一些做法将为Sx=A+P公式加入正则项,最终得到Sx=A+P+R。
本博客为自己的一些见解,欢迎大家留言指正错误。
关于LSTM的输入,详情参考如下链接的“隔壁小王”的回答。
下一篇:词向量发展史-共现矩阵-SVD-NNLM-Word2Vec-Glove-ELMo