深度学习之机器学习
#深度学习
深度学习(英语:deep learning)是机器学习的分支,是一种以人工神经网络为架构,对数据进行表征学习的算法。表征学习的目标是寻求更好的表示方法并创建更好的模型来从大规模未标记数据中学习这些表示方法。深度学习的好处是用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征。【https://zh.wikipedia.org/wiki/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0】
#例- Cat vs. Dog
让我们举一个动物识别器的例子,我们的系统必须识别给定的图像是猫还是狗。
如果我们将此解决为典型的机器学习问题,我们将定义诸如动物是否有胡须,动物是否有耳朵以及是否有耳朵等特征,然后如果它们是尖头的。简而言之,我们将定义面部特征,并让系统识别哪些特征在对特定动物进行分类时更为重要。
现在,深度学习领先一步。深度学习会自动找出对分类很重要的功能,在机器学习中我们必须手动提供功能。深度学习的工作原理如下:
深度学习的工作原理如下:
它首先确定哪些边缘与找到猫或狗最相关
然后,它以层次结构为基础,找到我们可以找到的形状和边缘的组合。例如,是否存在胡须,或是否存在耳朵等。
在对复杂概念进行连续分层识别之后,它决定哪个特征负责找到答案。
#机器学习与深度学习的比较
1、数据依赖性
深度学习与传统机器学习之间最重要的区别在于其随着数据规模的增加而表现出来。当数据很小时,深度学习算法表现不佳。这是因为深度学习算法需要大量数据才能完美理解。另一方面,在这种情况下,传统的机器学习算法及其手工制作的规则占主导地位。下图总结了这一事实。
2、硬件依赖性
深度学习算法在很大程度上依赖于高端机器,这与传统的机器学习算法相反,后者可以在低端机器上运行。这是因为深度学习算法的要求包括GPU,它是其工作的一个组成部分。深度学习算法固有地执行大量矩阵乘法运算。可以使用GPU有效地优化这些操作,因为GPU是为此目的而构建的。
3、特征工程
特征工程是将领域知识放入特征提取器的创建过程中的过程,以降低数据的复杂性并使模式对于学习算法更加可见。就时间和专业知识而言,这个过程既困难又昂贵。
在机器学习中,大多数应用的功能需要由专家识别,然后根据域和数据类型进行手动编码。
例如,特征可以是像素值,形状,纹理,位置和方向。大多数机器学习算法的性能取决于识别和提取特征的准确程度。
深度学习算法尝试从数据中学习高级特征。这是深度学习的一个非常独特的部分,是传统机器学习的重要一步。因此,深度学习减少了为每个问题开发新特征提取器的任务。就像,Convolutional NN将尝试学习低层特征,例如早期层中的边缘和线条,然后是人脸的部分面部,然后是面部的高级表示。
4、问题解决方法
当使用传统的机器学习算法解决问题时,通常建议将问题分解为不同的部分,单独解决它们并将它们组合起来得到结果。相反,深度学习主张端到端地解决问题。
我们举一个例子来理解这一点。
假设您有多个对象检测任务。任务是确定对象是什么以及它在图像中的位置。
在典型的机器学习方法中,您可以将问题分为两个步骤:对象检测和对象识别。首先,您将使用像grabcut这样的边界框检测算法来浏览图像并查找所有可能的对象。然后,在所有已识别的对象中,您将使用对象识别算法(如带有HOG的SVM)来识别相关对象。
相反,在深度学习方法中,您将完成端到端的过程。例如,在YOLO网(这是一种深度学习算法)中,您将传入一个图像,它将给出该位置以及对象的名称。
5、执行时间
通常,深度学习算法需要很长时间才能进行训练。这是因为深度学习算法中有如此多的参数,训练它们需要比平时更长的时间。最先进的深度学习算法ResNet大约需要两周时间才能从头开始训练。虽然机器学习相对需要更少的时间进行训练,但从几秒到几小时不等。
这在测试时间完全颠倒了。在测试时,深度学习算法运行时间要少得多。然而,如果将其与k近邻(一种机器学习算法)进行比较,则测试时间会随着数据大小的增加而增加。虽然这不适用于所有机器学习算法,但其中一些算法的测试时间也很短。
6、可解释性
最后但并非最不重要的是,我们将可解释性作为比较机器学习和深度学习的一个因素。这个因素是深度学习在用于工业之前仍被认为10次的主要原因。
我们来举个例子吧。假设我们使用深度学习来为论文提供自动评分。它在得分方面的表现非常出色,接近人类表现。但这是一个问题。它没有揭示为什么它给出了这个分数。事实上,你可以通过数学方法找出深层神经网络的哪些节点被激活,但我们不知道神经元应该建模的是什么以及这些神经元层共同做了什么。所以我们无法解释结果。
另一方面,像决策树这样的机器学习算法为我们提供了清晰的规则,为什么它选择了它所选择的内容,因此特别容易理解其背后的推理。因此,决策树和线性/逻辑回归等算法主要用于工业中的可解释性。
---------------------
作者:代码帮
来源:CSDN
原文:https://blog.csdn.net/ITLearnHall/article/details/81911084
版权声明:本文为博主原创文章,转载请附上博文链接!
#机器学习
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.【据说计算机程序从经验E中学习关于某类任务T和性能测量P,如果其在T中的任务中的性能(由P测量)随经验E而改善。】
#机器学习分类
机器学习可以分成下面几种类别:
- 监督学习从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求是包括输入和输出,也可以说是特征和目标。训练集中的目标是由人标注的。常见的监督学习算法包括回归分析和统计分类。
监督学习和非监督学习的差别就是训练集目标是否人标注。他们都有训练集 且都有输入和输出
【https://zh.wikipedia.org/wiki/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0】
- 无监督学习与监督学习相比,训练集没有人为标注的结果。常见的无监督学习算法有生成对抗网络(GAN)、聚类。
- 半监督学习介于监督学习与无监督学习之间。
- 增强学习机器为了达成目标,随着环境的变动,而逐步调整其行为,并评估每一个行动之后所到的回馈是正向的或负向的。
#Supervised Learning(监督学习)
给出数据中每一个例子的“正确答案”。
【是机器学习的一种方法,可以由训练资料中学到或建立一个模式(函数 / learning model),并依此模式推测新的实例。训练资料是由输入物件(通常是向量)和预期输出所组成。函数的输出可以是一个连续的值(称为回归分析),或是预测一个分类标签(称作分类)。https://zh.wikipedia.org/wiki/%E7%9B%A3%E7%9D%A3%E5%BC%8F%E5%AD%B8%E7%BF%92】
#Regession Problem(回归问题)
预测一个具体数值的输出。
#Classification Problem(分类问题)
预测离散值输出。
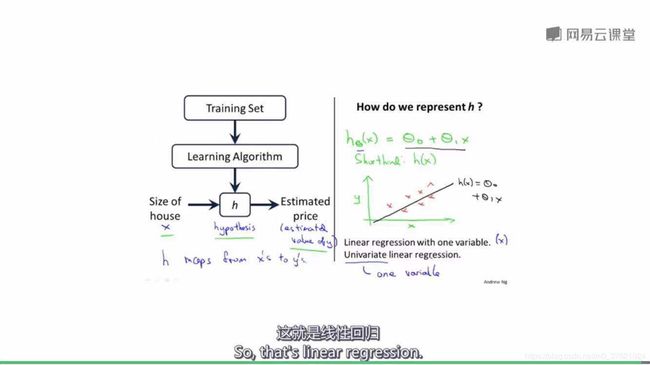
#hypothesis(假设函数)

#linear regression(线性回归)模型
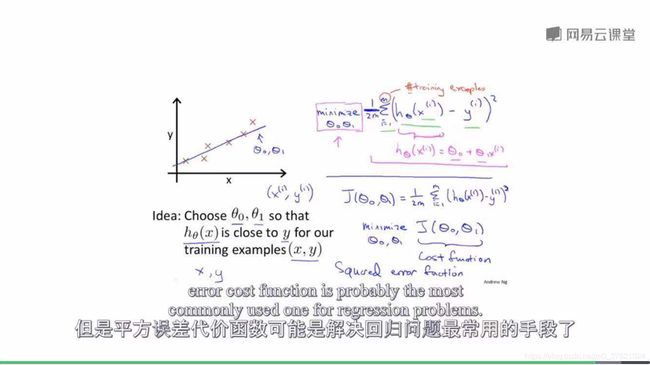
#Cost function(代价函数)
# contour plots(等高线图)
#Gradient descent(梯度下降法)

将任意函数最小化的算法。
- 赋值运算符:=
- learning rate(学习率α):控制梯度下降时迈出多大步伐,越大梯度下降越快。
- simultaneous update(同步更新)
详细内容下期分解~
PS.内容大部分为吴恩达老师机器学习的笔记【https://study.163.com/course/introduction/1004570029.htm】