【论文学习】:AlphaPose相关论文--RMPE:Regional Multi-Person Pose Estimation
本文为总结文:原文对论文的总结有些不准确,不易读懂,重新措词记录~1.http://www.cnblogs.com/taoshiqian/p/9593901.html
2.https://blog.csdn.net/qq_36165459/article/details/78330800
记录一个深度学习的官方文档!!!:http://deeplearning.net/tutorial/contents.html
引:主流的姿态识别通常2个思路:
(1)two-step framework,就是先进行行人检测,得到边界框,然后在每一个边界框中检测人体关键点,连接成一个人形,缺点就是受检测框的影响太大,漏检,误检,IOU大小等都会对结果有影响,代表方法就是RMPE。
(2)part-based framework,就是先对整个图片进行每个人体关键点部件的检测,再将检测到的部件拼接成一个人形,缺点就是会将不同人的不同部位按一个人进行拼接,代表方法就是openpose。
上海交通大学AlphaPose多人姿态估计论文
论文地址:https://arxiv.org/abs/1612.00137v5
项目主页:RMPE: Regional Multi-person Pose Estimation
RMPE:Regional Multi-Person Pose Estimation
该论文自顶向下方法,SSD-512检测人+stacked hourglass姿态估计。复杂环境中的多人姿态检测是非常具有挑战性的。现在最好的人体检测算法虽然已经得到了很好的效果,但是依然存在一些错误,这些错误会导致单人检测任务(SPPE)失败,尤其是那些十分依赖人体框检测结果的。这里应该是描述的自顶向下的检测技术,使用Faster-RCNN等算法进行目标检测(与之对应的有CPM等)。目前该算法得到了在MPII数据集上最高的mAP值。这个算法是由三部分组成的:
1 Symmetric Spatial Transformer Network – SSTN 对称空间变换网络:在不准确的bounding box中提取单人区域
2 Parametric Pose Non-Maximum-Suppression – NMS 参数化姿态非最大抑制:解决冗余
3 Pose-Guided Proposals Generator – PGPG 姿态引导区域框生成器:增强训练数据
该方法能够处理不准确的bounding box(边界框)和冗余检测,在MPII数据集上达到76.7mAP.
一、 介绍
多人姿态估计有两个主流方案:Two-step framework & Part-based framework。第一种方案是检测环境中的每一个人体检测框,然后独立地去检测每一个人体区域的姿态(自顶向下的方法)。第二种方案是首先检测出环境中的所有肢体节点,然后进行拼接得到多人的骨架(自底向上的方法)。第一种方案,姿态检测准确度高度依赖目标区域框检测的质量。第二种方案,是依赖两个部件之间的关系,所以失去了对全局的信息获取。如果两人离得十分近,容易出现模棱两可的情况。
论文采用自顶向下方法。我们的目标是检测出正确的人体姿态即使在第一步中检测到的是不精准的区域框。为了说明之前的算法存在这些问题,我们使用Faster-RCNN和SPPE Stacked Hourglass进行实验,主要的问题是位置识别错误和识别冗余,如图1和图2所示。事实上,SPPE对于区域框错误是非常脆弱的,即使是使用IoU>0.5的边界框认为是正确的,检测到的人体姿态依然可能是错误的。冗余的区域框会产生冗余的姿态。


冗余:两个bounding box框住同一个人,会检测两遍,形成两个骨架
因此,提出了RMPE(区域多人姿态检测)框架,提升SPPE-based性能。在SPPE结构上添加SSTN,能够在不精准的区域框中提取到高质量的人体区域。并行的SPPE分支(SSTN)来优化自身网络。使用parametric pose NMS来解决冗余检测问题,在该结构中,使用了自创的姿态距离度量方案比较姿态之间的相似度。用数据驱动的方法优化姿态距离参数。最后我们使用PGPG来强化训练数据,通过学习输出结果中不同姿态的描述信息,来模仿人体区域框的生成过程,进一步产生一个更大的训练集。
我们的RMPE框架是通用的,适用于不同的人体探测器和单人姿势估计器。将RMPE框架应用于MPII(多人)数据集[3],达到state-of-the-art效果76.7 mAP。我们还进行了切除研究,以验证我们框架中每个组件的有效性。
二、 相关工作
2.1 单人姿态估计
……单人姿态估计总是需要保证人被正确的定位。
2.2 多人姿态估计
Part-Base 先检测关键点,再连接;先检测肢体
Two-Step 目标检测+单人姿态估计
三、 RMPE(论文地址)
如图3所示。首先通过目标检测算法,得到人体的区域框。然后将该区域框输入到STN+SPPE模块中,自动检测人体姿态。再通过PP-NMS进行refine。在训练过程中,使用Parallel SPPE来避免局部最优并进一步提升SSTN的效果。设计PGPG结构来增强已有的训练集。

图解:SSTN=STN+SDTN,STN处理区域框,SPPE单人姿态估计(Stacked Hourglass姿态检测),STDN产生姿态建议。并行SPPE作为训练阶段的额外正则化。p-PNMS去除冗余姿态。使用PGPG产生的增强图像来训练SSTN+SPPE模型。
整个过程分为3步:
第一步是用SSD检测人,获得human proposal CNN目标检测(三):SSD详解 R-SSD
第二步是将proposal输入到两个并行的分支里面,上面的分支是STN+SPPE+SDTN的结构,即Spatial Transformer Networks + Single Person Pose Estimation + Spatial de- Transformer Networks,STN接收的是human proposal,SDTN产生的是pose proposal。下面并行的分支充当额外的正则化矫正器。 Spatial Transformer Networks论文、阅读分析笔记
第三步是对pose proposal做Pose NMS(非最大值抑制),用来消除冗余的pose proposal。论文A convnet for non-maximum suppression、论文阅读、参考博客1、 参考博客2
还有个比较重要和新颖的:Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
小记一个可能有用的2D到3D的姿态估计、加速,tensorrt加速
3.1 Symmetric STN and Parallel SPPE
对称空间变换网络,并行单人姿态估计
目标检测算法得到的人体区域框不是非常适合SPPE,因为SPPE算法是专门针对单个人的图像进行训练的,并且对于定位错误十分敏感。通过微小变换、修剪的方法可以有效的提高SPPE的效果。SSTN+Parallel SPPE可以在不完美的人体区域检测结果下有效的增强SPPE的效果,结构如图4所示。

图解:表示了SSTN + Parallel SPPE模块的结构,SDTN结构接收一个由定位网络生成的参数θ,然后为反向转换计算参数γ。我们使用网格生成器和采样器去提取一个人的所在区域,在Parallel SPPE中,制定一个中心定位姿态标签。我们固定Parallel SPPE的所有层的所有权重来增强STN去提取一个单人姿态区域。
STN and SDTN(spatial de-transformer network,空间反变换网络)。STN能很好地自动选取ROI,使用STN去提取一个高质量的人体区域框。(ROI是Region of Interest的简写,指的是在“特征图上的框”; 1)在Fast RCNN中, RoI是指Selective Search完成后得到的“候选框”在特征图上的映; 2)在Faster RCNN中,候选框是经过RPN产生的,然后再把各个“候选框”映射到特征图上,得到RoIs。ROI pooling、roi align、特征图)数学形式如下,2D affine transformation:
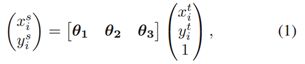
其中θ1,θ2和θ3都是二维空间的向量,{Xsi,Ysi}和{Xti,Yti}分别表示转换之前的坐标和转换之后的坐标。空间解变换网络(SDTN)将估计的人体姿态重新映射回原始图像坐标(这样子的话人体姿态线就会存在于原图尺寸的图像中)。SDTN中需要为反向转换和生成网格计算一个γ:

因为SDTN是STN结构的反向结构,所以可以得到以下关系:

为了在SDTN中进行反向传播,∂J(W,b)/∂θ可以分解为:

STN是通过V坐标学习得来θ后,式子(1)得到U坐标,将像素映射到V中;
SDTN是通过U坐标和γ得到V坐标,把V坐标的关节点映射打动U中。 (此时的输入图像为骨骼框架,目标为原始图像)
STN(论文阅读)可以被安装在任意CNN的任意一层中——这里有些同学有误解,以为上图中U到V是原来的卷积,并且在卷积的路径上加了一个分支,其实并不是,而是将原来的一层结果U,变换到了V,中间并没有卷积的操作。通过U到V的变换,相当于又生成了一个新数据,而这个数据变换不是定死的而是学习来的,即然是学习来的,那它就有让loss变小的作用,也就是说,通过对输入数据进行简单的空间变换,使得特征变得更容易分类(往loss更小的方向变化)。另外一方面,有了STN,网络就可以动态地做到旋转不变性,平移不变性等原本认为是Pooling层做的事情,同时可以选择图像中最终要的区域(有利于分类)并把它变换到一个最理想的姿态(比如把字放正)。在得到高质量的人体检测框后,可以使用现成的SPPE算法来继续高精度的人体姿态检测,在训练阶段中,SSTN和SPPE一起进行fine-tuned。
是这样的:不准确的检测框经过STN+SPPE+SDTN,STN对人体区域框中的姿态进行形态调整,输入SPPE做姿态估计后得到姿态线(人体骨骼框架),再用SDTN把姿态线映射到原始的人体区域框中,以此来调整原本的框,使框变成精准的。
Parallel SPPE。为了进一步帮助STN去提取更好的人体区域位置,在训练阶段添加了一个Parallel SPPE分支。这个Paralell SPPE和原来的SPPE用同一个STN模块,和SPPE并行处理时候,忽略SDTN模块。这个分支的人体姿态标签被指定为中心,更准确的说,SPPE网络的输出直接和人体真实姿态的标签进行对比。在训练过程中会关闭Parallel SPPE的所有层(????),我们固定这个分支的权重,其目的是将中心位置的位姿误差反向传播到STN模块。如果STN提取的姿态不是中心位置,那么Parallel SPPE会返回一个较大的误差。通过这种方式,我们可以帮助STN聚焦在正确的中心位置并提取出高质量的区域位置。Parallel SPPE只有在训练阶段才会产生作用。
Discussions。Parallel SPPE可以看作是训练阶段的正则化过程,有助于避免局部最优的情况(STN不能把姿态转换到提取到人体区域框的居中位置)。但是SDTN的反向修正可以减少网络的错误进而降低陷入局部最优的可能性。这些错误对于训练STN是很有影响的。通过Parallel SPPE,可以提高STN将人体姿态移动到检测框中间的能力。
感觉上似乎可以在SPPE的输出后添加一个中心定位姿态的回归损失函数来取代Parallel SPPE。然而,这种方法会降低我们整个系统的性能。尽管STN可以部分修改输入,但是不可能完美的将人定位在标签的位置。SPPE输入与标签坐标空间上的差异,将在很大程度上影响其学习姿态估计的能力,导致我们主分支SPPE的性能下降。因此,为了确保STN和SPPE同时发挥自己的作用,一个固定权重的Parallel SPPE是不可缺少的。Parallel SPPE在不影响主分支SPPE性能的情况下,会对非中心姿态产生较大的误差,从而推动STN产生中心位置的姿态。
3.2. Parametric Pose NMS 参数化姿态非最大抑制
人体定位不可避免的会产生冗余的检测框,同时也会产生冗余的姿态检测。所以,姿态非极大值抑制是十分有必要的,用来消除冗余。以前的方法要么效率不高,要么精确度不高。在论文中,提出了一种parametric pose NMS(参数化姿态非极大值抑制)方法。对于一个人的姿态Pi,有m 个关节点记做{(k1i,c1i),(k2i,c2i),...,(kmi,cmi)},kji 和 cji 分别表示第 j 个部位的坐标位置和置信度分数。
NMS schema。NMS体系。回顾一下NMS:首先选取最大置信度的姿态作为参考,并且根据消除标准将靠近该参考的区域框进行消除。这个过程多次重复直到冗余的识别框被消除并且每一个识别框都是唯一的出现(没有超过阈值的重叠)。
Elimination Criterion。消去法则。 我们需要定义姿态相似度来消除那些离得较近且比较相似的姿态。我们定义了一种姿态距离度量d(Pi,Pj|Λ)来衡量姿态之间的相似度,定义η作为消除标准的阈值,在这里的Λ表示函数d(⋅)的一个参数集合。我们的消除标准可以定义为下面的形式:
![]()
如果d(⋅)小于阈值η,那么f(⋅)的输出是1,表示姿态Pi应该被消除,因为对于参考的Pj来说Pi是冗余的。
Pose Distance。姿态距离。定义距离函数dpose(Pi,Pj)。假设姿态Pi的区域框是Bi。然后我们定义一个软匹配函数:

B(kni)表示部位i的区域位置,维度上大约是整体图像的1/10。Tanh可以滤掉低置信度的姿态,当两个姿态的置信度都比较高的时候,上述函数的输出接近1。这个距离表示了姿态之间不同部位的匹配数。空间距离可以定义为:

因此最终距离可以定义为:
![]()
其中λ是一个权重系数,来平衡这两种距离,Λ表示{σ1,σ2,λ},参考之前的pose NMS进行参数设置。
Optimization 。优化。给定检测到的冗余姿态,消除标准f(Pi,Pj|Λ, η)的这四个参数被优化以实现验证集的最大mAP。由于在4D空间中的穷举搜索是难以处理的,所以在迭代的过程中,固定两个参数变化另外两个参数进行搜索最优解。一旦收敛,这些参数将会固定,并用在测试阶段。
3.3. Pose-guided Proposals Generator 姿态引导的区域框生成器
Data Augmentation 数据增强
对于Two-Stage姿态识别(首先定位区域,然后进行姿态点定位),适当的数据增强有助于让SSTN+SPPE适应不完美的人体区域定位结果。否则,模型在测试阶段运行时可能不是很适应奇怪的人体定位结果。一种直观的方法是在训练阶段使用检测出来的区域框。然而,目标检测对于一个人而言只会产生一个定位区域。通过使用生成的人体定位,可以产生一定得效果。因为我们已经有了每一个人的真实位置和检测出来的定位框,我们可以通过与人体检测结果一致的样本生成一个大样本的训练集。通过这种技术,我们可以进一步提高系统的性能。
Insight
我们寻找对于不同姿态之间真实值和实际预测值的相对偏移量的分布。为了进一步明确过程,这里定义P(δB|P),δB表示检测到的人体位置的坐标和实际人体的标注坐标之间的偏移量,P是真实情况中一个人。我们可以根据目标检测得到的推荐位置生成一些训练集。
Implementation
直接学习P(δB|P)对于易变的人体姿态是比较困难的。因此我们使用P(δB|atom(P)),atom(P)表示P的原子姿势(P是一个姿态,包含多个关节点)。为了从人类姿态的注解中得到相应的原子结构,
1.首先对齐(列出)所有姿势,使躯干具有相同的长度。
2.然后使用K-means聚类算法对已经对齐的姿态进行聚类,计算出的聚类中心形成我们的原子姿态。
对于每一个共享atomic(a)的实例,计算该实例的真实值和检测边界框的偏移量。
通过该方向上的ground truth bounding box的相应边长来将偏移归一化处理。经过这些处理后,偏移量形成频率分布,我们将这些数据拟合成高斯混合分布(频率分布→高斯混合分布)。对于不同的原子姿态,我们会得到不同的高斯混合分布,如图

Proposals Generation
在SSTN+SPPE的训练阶段,对于训练样本中的每个带注释的姿势,我们首先查找相应的原子姿态a。然后,根据p(δB,a),通过密集采样产生额外的偏移量,从而产生增强的训练proposals(‘假’样本)。
大部分姿态检测的最后一步,是在feature map上对每个像素做概率预测,计算该像素是某个关节点的概率。
上图就是各个关节点的heat map,左边第一张为输入图像以及最终的预测关节点位置,第二张为对颈部节点的概率预测,红色和黄色代表着对应像素位置是颈部的概率很高,其他蓝色区域意味着这里几乎不会是颈部位置。

四、 实验
所提出的方法在具有大遮挡情况的两个标准多人数据集上进行定性和定量评估:MPII [3]和MSCOCO 2016关键点挑战数据集。
4.1评估数据集
MPII:多人,3844训练,1758测试,有遮挡和重叠,28000个单人姿态估计样本。使用单人数据集中所有训练数据和90%多人训练集来微调SPPE,留下10%用于验证。
MSCOCO关键点挑战。105698训练,80000测试,100W个关键点。
4.2测试实现细节
基于VGG的SSD-512作为人体检测器。检测到人体后,高度和宽度都延伸30%。使用stacked hourglass模型做单人姿态估计。对于STN网络,采用ResNet-18作为本地化网络,使用较小的4-stacked hourglass作为并行SPPE。考虑到存储效率,我们使用一个4-stack hourglass network作为并行SPPE。
为了标明框架的应用能力,人体检测器可替换为基于Faster-RCNN的ResNet152,姿态估计可以替换为PyraNet。
4.3结果
MPII。如表1所示,在手腕,肘部,踝关节和膝盖等困难关节时达到了
72 mAP 的平均准确度。

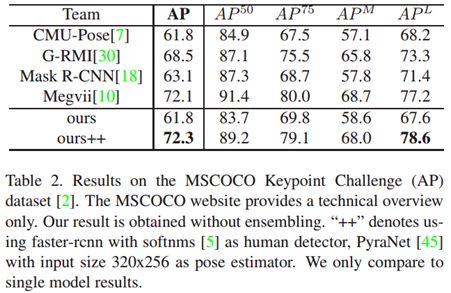
MSCOCO。利用MSCOCO keypoints的训练集和验证集,来fine-tune SPPE,并留下5000图像用于验证。表2为测试结果,优于其他方法。
4.4消除实验
为了验证这三个组件的有效性:SSTN,PGPG,PP-NMS。移除或者使用常规方法来替代。在MPII上实验,结果见表3.

Symmetric STN and Parallel SPPE
为了验证SSTN和parallel SPPE的重要性,进行了两个实验。在第一个实验中删除了SSTN和并行SPPE。在第二个实验中,我们只删除了并行SPPE并保持SSTN结构。这些结果均显示在表3(a)中。我们可以在去除平行SPPE时观察到性能下降,这意味着具有单人图像标签的并行SPPE能有效提升STN提取单个人区域的效果,以最小化总损失。
Pose-guided Proposals Generator
在表3(b)中,证明PGPG在系统中也起着重要作用。在本实验中,首先从训练阶段中删除数据增强。最终的mAP降至73.0 %。然后我们将数据增强技术与简单基线进行比较。通过抖动(jitter)人体检测器产生的边界框的位置和纵横比来形成基线,以产生大量附加的提议框。我们选择那些IoU > 0.5的ground-truth框。从我们在表3中的结果(b),我们可以看到我们的技术优于基线方法。根据分布生成培训建议可以看作是一种数据重新抽样,可以帮助模型更好地适应人类的建议。
Parametric Pose NMS
由于姿势NMS是一个独立的模块,我们可以直接从最终模型中删除它。实验结果如表3(c)所示。我们可以看到,如果删除了参数化姿势NMS,则mAP会显着下降。这是因为冗余姿势数量的增加最终会降低精确度。我们注意到之前的姿势NMS也可以在一定程度上消除冗余检测。最先进的姿势NMS算法[ 6,9]用于替换我们的PP-NMS,对结果于表3(C)。这些方案的效果不如我们的,因为缺少参数学习。在效率方面,在包含1300张图像的验证集上,[6]的姿势NMS需要62.2秒,而使用我们的算法只需1.8秒。
Upper Bound of Our Framework 上界
使用ground-truth的边界框作为人体提议框,如表3(e),84.2mAP ,(在MSCOCO keypoints 上63.3mAP),它验证了我们的系统已经接近两步框架的上限。表示使用更强的人体检测器,我们的框架可以有更好的性能,证明RMPE框架是通用的,适合不同的人体检测器。
五、 结论
在本文中,提出了一种新的区域多人姿态估计(RMPE)框架,其在准确性和效率方面明显优于最先进的多人人体姿态估计方法。当SPPE适用于人体检测器时,它验证了two-step框架的潜力,即人体检测器+ SPPE。我们的RMPE框架由三个新颖的组件组成:具有并行SPPE的对称STN,参数姿势NMS和姿态引导建议生成器(PGPG)。特别地,PGPG用于通过学习针对给定人体姿势的边界框提议的条件分布来极大地论证训练数据。由于使用对称STN和并行SPPE,SPPE变得善于处理人体本地化错误。最后,参数姿势NMS可用于减少冗余检测。
参考:
https://blog.csdn.net/TwT520Ly/article/details/79258594
https://arxiv.org/pdf/1612.00137.pdf
https://github.com/MVIG-SJTU/AlphaPose/tree/pytorch
http://www.mvig.org/research/alphapose.html