聚集索引和非聚集索引的根本区别
根本区别
聚集索引和非聚集索引的根本区别是表记录的排列顺序和与索引的排列顺序是否一致。
聚集索引
聚集索引表记录的排列顺序和索引的排列顺序一致,所以查询效率快,只要找到第一个索引值记录,其余就连续性的记录在物理也一样连续存放。聚集索引对应的缺点就是修改慢,因为为了保证表中记录的物理和索引顺序一致,在记录插入的时候,会对数据页重新排序。
非聚集索引
非聚集索引制定了表中记录的逻辑顺序,但是记录的物理和索引不一定一致,两种索引都采用B+树结构,非聚集索引的叶子层并不和实际数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针方式。非聚集索引层次多,不会造成数据重排。
例子对比两种索引
聚集索引就类似新华字典中的拼音排序索引,都是按顺序进行,例如找到字典中的“爱”,就里面顺序执行找到“癌”。而非聚集索引则类似于笔画排序,索引顺序和物理顺序并不是按顺序存放的。
索引创建Demo
create database IndexDemo
go
use IndexDemo
go
create table ABC
(
A int not null,
B char(10),
C varchar(10)
)
go
insert into ABC select 1,'B','C'
union select 5,'B','C'
union select 7,'B','C'
union select 9,'B','C'
go select * from abc
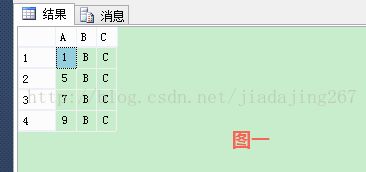
这个时候查看表记录,如图一显示
这个时候插入一条数据,
insert into abc values('6','B','C')
此时的查询记录为图二展示

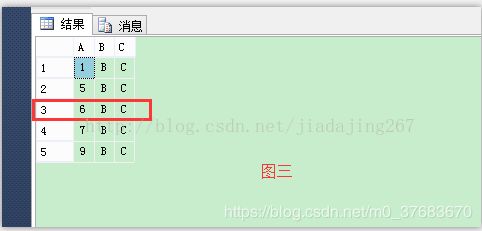
添加聚集索引,再查询数据显示为图三,此时发现表的顺序发生了变化,此时的排序按A字段的递增排序。
create clustered index CLU_ABC on abc(A)
删除聚集索引,会发现表的顺序不会发生改变。
drop index abc.CLU_ABC
添加非聚集索引,添加新的记录,查看表顺序,如图四,并没有影响表的顺序。
create nonclustered index NONCLU_ABC on abc(A)
insert into abc values('4','B','C')

原文:https://blog.csdn.net/jiadajing267/article/details/54581262