设置PDI7.1连接到Cloudera集群
在你开始之前
在开始之前,你需要做一些事情。
验证支持
检查组件引用,以验证您的PunaHo版本支持CDH集群的版本。
建立CDH集群
配置CDH集群。如果需要帮助,请参阅Cloudera的文档。
安装任何必需的服务和服务客户端工具。
测试群集。
获取连接信息
获取您将从Hadoop管理员、Cloudera管理器或其他群集管理工具使用的群集和服务的连接信息。一旦完成,您还需要向用户提供一些信息。
Add a YARN User to the Superuser Group
Add the YARN user on the cluster to the group defined by dfs.permissions.superusergroup property. The dfs.permissions.superusergroup property can be found in hdfs-site.xml file on your cluster or in the Cloudera Manager.
将YARN 用户添加到超级用户组将集群上, YARN 用户添加到由 dfs.permissions.superusergroup 属性定义的组中。 dfs.permissions.superusergroup 属性可以在您的集群上或在Cloudera管理器中的hdfs-site.xml 文件中找到。
检测到英语 中文
复习特定版本的注释部分
阅读特定版本的注释部分,查看CDH版本的特殊配置说明。
如果您连接到一个安全的CDH集群,还有一些额外的事情需要做。
用Kerberos保护Cloudera集群
TunaHo支持Kerberos身份验证。你将需要:
在集群上配置Kerberos安全性,包括Kerberos域、Kerberos KDC和Kerberos管理服务器。
配置名称、数据、辅助名称、作业跟踪器和任务跟踪器节点以接受远程连接请求。
如果已经使用企业级程序部署了CDH,则为名称、数据、辅助名称、作业跟踪器和任务跟踪器节点设置Kerberos。
为需要访问Hadoop集群的每一个PANDAHO用户添加Kerberos数据库的用户帐户凭据。此外,请确保Hadoop集群中的每个节点上有一个操作系统用户帐户,用于要添加到Kerberos数据库的每个用户。如有必要,添加操作系统用户帐户。注意,用户帐户UID应该大于最小用户ID值(min .U.I.ID)。通常,最小用户ID值设置为1000
在你的五音计算机上设置Kerberos
如何在您的PUNAHO计算机上设置Kerberos的文章中出现了如何执行此操作的说明。
在群集上编辑配置文件
PANHAHO对配置文件的特定编辑是在本节中引用的群集。
奥齐
默认情况下,OoZee作业由OoZUI用户运行。但是,如果使用PDI启动Oozie作业,则必须将PDI用户添加到集群上的oozie-site.xml文件中,以便PDI用户可以代理执行程序。如果您打算使用OZUI服务完成这些指令:
在群集上打开OZIE-SIT.xml文件。
Add the following lines of the code to the oozie-site.xml file on cluster, substituting
将下面的代码行添加到集群上的oozie-site.xml文件中,用PDI用户名(如jdoe)替换<._pdi_user_name>。
Save and close the file
Pentaho的垫片配置组件
你必须在以下五人组每个组件中配置垫片,在每台计算机上,五人组将被用来连接到集群:
You must configure the shim in each of the following Pentaho components, on each computer from which Pentaho will be used to connect to the cluster:
- Spoon (PDI Client)
- Pentaho Server, including Analyzer and Pentaho Interactive Reporting.
- Pentaho Report Designer (PRD)
- Pentaho Metadata Editor (PME)
As a best practice, configure the shim in Spoon first. Spoon has features that will help you test your configuration. Then copy the tested Spoon configuration files to other components, making changes if necessary.
You can also opt to go through these instructions for each Pentaho component, and not copy the shim files from Spoon. If you do not plan to connect to the cluster from Spoon, you can configure the shim in another component first instead.
勺子(PDI客户端)
PUNAHO服务器,包括分析器和PATAHO交互式报告。
PATHAO报表设计器(PRD)
PATAHO元数据编辑器(PME)
作为最佳实践,首先在调羹中配置垫片。勺子具有帮助您测试配置的功能。然后将测试的勺子配置文件复制到其他组件,必要时进行更改。
您还可以选择通过每个PunaHO组件的这些指令,而不是从勺子复制垫片文件。如果不打算从勺子连接到群集,则可以先在另一个组件中配置垫片。
Step 1: Locate the Pentaho Big Data Plugin and Shim Directories
Shims and other parts of the Pentaho Adaptive Big Data Layer are in the Pentaho Big Data Plugin directory. The path to this directory differs by component. You need to know the locations of this directory, in each component, to complete shim configuration and testing tasks.
步骤1:大日期定位垫片和the Pentaho的插件目录
与其他部分shims of the Pentaho的自适应层是大日大日期在Pentaho的插件目录。differs by the path to this目录组件。你知道the need to each of this目录位置,和垫片组件,完整的测试任务的配置。
<目录> Pentaho的Pentaho的where is the is installed。
| Components | Location of Pentaho Big Data Plugin Directory |
|---|---|
| Spoon | |
| Pentaho Server | |
| Pentaho Report Designer | |
| Pentaho Metadata Editor |
Shims are located in the pentaho-big-data-plugin/hadoop-configurations directory. Shim directory names consist of a three or four letter Hadoop Distribution abbreviation followed by the Hadoop Distribution's version number. The version number does not contain a decimal point. For example, the shim directory named cdh54 is the shim for the CDH (Cloudera Distribution for Hadoop), version 5.4. Here is a list of the shim directory abbreviations.
垫片位于PATAHO大数据插件/Hadoop配置目录中。Shim目录名由三个或四个字母Hadoop Distribution缩写组成,后面跟着Hadoop Distribution的版本号。版本号不包含小数点。例如,名为CDH54的垫片目录是CDH(Hadoop的Cloudera发行版)的版本,版本5.4。这是一个SIMM目录缩写列表。
| Abbreviation | Shim |
|---|---|
| cdh | Cloudera's Distribution of Apache Hadoop |
| emr | Amazon Elastic Map Reduce |
| hdi | Microsoft Azure HDInsight |
| hdp | Hortonworks Data Platform |
| mapr | MapR |
Step 2: Select the Correct Shim
Although Pentaho often supports one or more versions of a Hadoop distribution, the download of the Pentaho suite only contains the latest, supported, Pentaho-certified version of the shim. The other supported versions of shims can be downloaded from the Pentaho Customer Support Portal.
Before you begin, verify that the shim you want is supported by your version of Pentaho shown in the Components Reference.
- Navigate to the pentaho-big-data-plugin/hadoop-configurations directory to view the shim directories. If the shim you want to use is already there, you can go to Step 3: Copy the Configuration Files from Cluster to Shim.
- On the Customer Portal home page, sign in using the Pentaho support user name and password provided to you in your Pentaho Welcome Packet.
- In the search box, enter the name of the shim you want. Select the shim from the search results. Optionally, you can browse the shims by version on the Downloads page.
- Read all prerequisites, warnings, and instructions. On the bottom of the page in the Box widget, click the shim zip file to download it.
- Unzip the downloaded shim package to the pentaho-big-data-plugin/hadoop-configurations directory.
步骤2:选择Correct Shim
虽然Pentaho经常支持Hadoop发行版的一个或多个版本,但Pentaho套件的下载只包含最新的、支持的、经Pentaho认证的shim版本。其他支持版本的垫片可以从PANTAHO客户支持门户下载。
在开始之前,请验证所需的垫片是否由组件引用中所示的PunaHo版本支持。
导航到PATAHO大数据插件/Hadoop配置目录,查看SIMM目录。如果要使用的垫片已经存在,可以转到步骤3:将配置文件从群集复制到Shim。在客户门户主页上,使用Pentaho Welcome Packet中提供的Pentaho支持用户名和密码登录。
在“搜索”框中,输入所需垫片的名称。从搜索结果中选择垫片。可选地,可以在下载页面上按版本浏览SHIMS。
阅读所有的先决条件、警告和指令。在方块底部的页面底部,单击Sim-zip文件下载。
将下载的垫片包解压缩到PunaHo大数据插件/Hadoop配置目录。
Step 3: Copy the Configuration Files from Cluster to Shim
Copying configuration files from the cluster to the shim helps keep key configuration settings in sync with the cluster and reduces configuration errors.
- Back up the CDH shim files in the pentaho-big-data-plugin/hadoop-configurations/cdhxx directory.
- Copy the following configuration files from the cluster to the Pentaho shim directory. You should overwrite the existing Pentaho shim files.
- core-site.xml
- hbase-site.xml
- hdfs-site.xml
- hive-site.xml
- mapred-site.xml
- yarn-site.xml
Step 4: Edit the Shim Configuration Files
You need to verify or change settings in authentication, Oozie, Hive, MapReduce, and YARN in these shim configuration files:
- core-site.xml
- config.properties
- hive-site.xml
- mapred-site.xml
- yarn-site.xml
Edit config.properties (Unsecured Cluster)
If you are connecting to an unsecure cluster, verify that these values are properly set. Set the Oozie proxy user if needed.
- Navigate to the pentaho-big-data-plugin/hadoop-configurations/cdhxx directory and open the config.properties file.
- Add the following values:
| Parameter | Values |
|---|---|
| authentication.superuser.provider | NO_AUTH |
| pentaho.oozie.proxy.user | Add a proxy user's name to access the Oozie service through a proxy, otherwise, leave it set to oozie. |
- Save and close the file.
Edit config.properties (Secured Clusters)
If you are connecting to a secure cluster, add Kerberos information to the config.properties file. If you plan to use secure impersonation to access your cluster, see Use Secure Impersonation to Access a Cloudera Cluster before editing the config.properties file.
Perform the following steps to add Kerberos information to the config.properties file:
- Navigate to the pentaho-big-data-plugin/hadoop-configurations/cdhxx directory and open the config.properties file.
- Add these values:
| Parameter | Values |
|---|---|
| authentication.superuser.provider | cdh-kerberos (This should be the same as the authentication.kerberos.id.) |
| authentication.kerberos.principal | Set the Kerberos principal. |
| authentication.kerberos.password | Set the Kerberos password. You only need to set the password or the keytab, not both. |
| authentication.kerberos.keytabLocation | set the Kerberos keytab. You only need to set the password or the keytab, not both. |
| pentaho.oozie.proxy.user | Add the proxy user's name if you plan to access the Oozie service through a proxy. Otherwise, leave it set to oozie. |
- Save and close the file.
Edit hive-site.xml
Follow these instructions to set the location of the hive metastore in the hive-site.xml file:
- Navigate to the pentaho-big-data-plugin/hadoop-configurations/cdhxx directory and open the hive-site.xml file.
- Add these values:
| Parameter | Value |
|---|---|
| hive.metastore.uris | Set this to the location of your hive metastore if it differs from what is on the cluster. |
- Save and close the file.
Edit mapred-site.xml
Edit the mapred-site.xml file to indicate where the job history logs are stored and to allow MapReduce jobs to run across platforms.
- Navigate to the pentaho-big-data-plugin/hadoop-configurations/cdhxx directory and open the mapred-site.xml file.
- Verify the mapreduce.jobhistory.address and mapreduce.app-submission.cross-platform properties are in the mapred-site.xml file. If they are not in the file, add them as follows.
| Parameter | Value | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| mapreduce.jobhistory.address | Set this to the place where job history logs are stored. | ||||||||
| mapreduce.app-submission.cross-platform | Add this property to allow MapReduce jobs to run on either Windows client or Linux server platforms.
|
- Save and close the file.
Edit yarn-site.xml
Make changes to these YARN parameters:
- Navigate to the pentaho-big-data-plugin/hadoop-configurations/cdhxx directory and open the yarn-site.xml file.
- Add the following values:
| Parameter | Values |
|---|---|
| yarn.application.classpath | Add the classpaths you need to run YARN applications. Use commas to separate multiple paths. |
| yarn.resourcemanager.hostname | Change to the hostname of the resource manager in your environment. |
| yarn.resourcemanager.address | Change to the hostname and port for your environment. |
| yarn.resourcemanager.admin.address | Change to the hostname and port for your environment. |
- Save and close the file.
Create a Connection to the CDH Cluster
Creating a connection to the cluster involves setting an active shim, then configuring and testing the connection to the cluster. Making a shim active means it is used by default when you access a cluster. When you initially install Pentaho, no shim is active by default. You must choose a shim to make active before you can connect to a cluster. Only one shim can be active at a time. The way you make a shim active, as well as the way you configure and test the cluster connection differs by Pentaho component.
Create and Test a Connection to the Cluster in Spoon
Creating and testing a connection to the CDH cluster from Spoon involves two tasks:
- Setting the active shim in Spoon
- Configuring and testing the cluster connection
Set the Active Shim in Spoon
You must set an active shim when you want to connect to a Hadoop cluster the first time, or when you want to switch clusters. To set a shim as active, complete the following steps:
- Start Spoon.
- Select Hadoop Distribution... from the Tools menu.
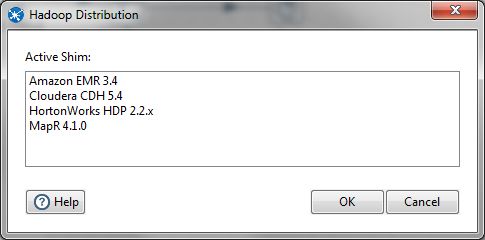
- In the Hadoop Distribution window, select the Hadoop distribution you want.
- Click OK.
- Stop, then restart Spoon.
Configure and Test the Cluster Connection
You must provide connection details for the cluster and services you will use, such as the hostname for HDFS or the URL for Oozie. Then, you can use a built-in tool to test your configuration to find and troubleshoot common configuration issues, such as wrong hostnames and user permission errors.
Connection settings are set in the Hadoop cluster window. You can get to the settings from several places, but in these instructions, you will get the Hadoop cluster window from the View tab in a transformation or job. Complete the following steps to configure and test a connection:
- In the PDI client, create a new job or transformation or open an existing one.
- Click the View tab.
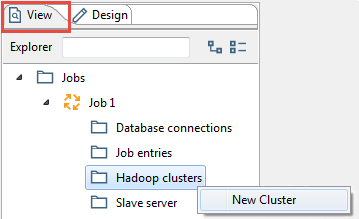
- Right-click the Hadoop clusters folder, then click New. The Hadoop cluster window appears.
- Enter the information from the following table in the Hadoop cluster window. You can get this information from your Hadoop Administrator.
As a best practice, use Kettle variables for each connection parameter value to mitigate risks associated with running jobs and transformations in environments that are disconnected from the repository.
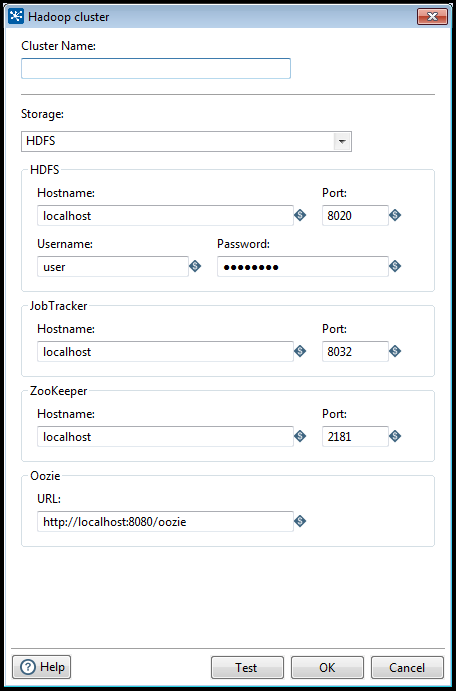
| Option | Definition |
|---|---|
| Cluster Name | Name that you assign the cluster connection. |
| Storage | Specifies the type of storage you want to use for this connection. Use the drop-down box to select one of the following:
|
| Hostname (in selected storage section) | Hostname for the HDFS or WASB node in your Hadoop cluster. |
| Port (in selected storage section) | Port for the HDFS or WASB node in your Hadoop cluster. If your cluster has been enabled for high availability (HA), then you do not need a port number. Clear the port number. |
| Username (in selected storage section) | Username for the HDFS or WASB node. |
| Password (in selected storage section) | Password for the HDFS or WASB node. |
| Hostname (in JobTracker section) | Hostname for the JobTracker node in your Hadoop cluster. If you have a separate job tracker node, type in the hostname here. |
| Port (in JobTracker section) | Port for the JobTracker in your Hadoop cluster. |
| Hostname (in ZooKeeper section) | Hostname for the ZooKeeper node in your Hadoop cluster. Supply this only if you want to connect to a ZooKeeper service. |
| Port (in Zookeeper section) | Port for the ZooKeeper node in your Hadoop cluster. Supply this only if you want to connect to a ZooKeeper service. |
| URL (in Oozie section) | Oozie client address. Supply this only if you want to connect to the Oozie service. |
- Click the Test button. Test results appear in the Hadoop Cluster Test window. If there are no errors, the connection is properly configured. If you have errors, see the Troubleshoot Cluster and Service Configuration Issues section below to resolve the issues, then test again.
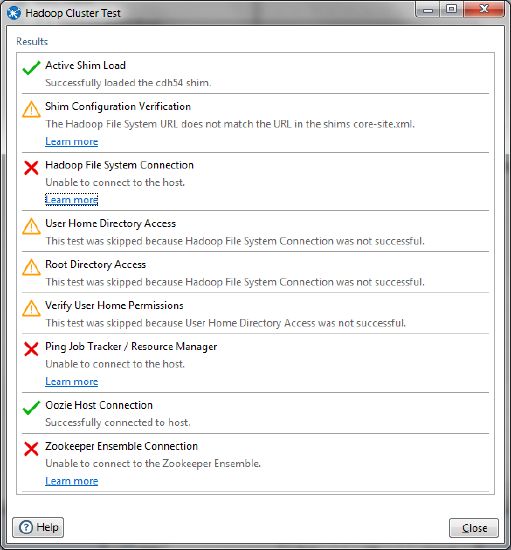
- Click Close on the Hadoop Cluster Test window, then click OK to close the Hadoop cluster window.
Copy Spoon Shim Files to Other Pentaho Components
Once your connection has been properly configured on Spoon, you can copy the configuration files to the shim directories in the other Pentaho components. Copy the following configuration files from the pentaho-big-data-plugin/hadoop-configurations/hadoop-configurations/cdhxx directory in Spoon to the pentaho-big-data-plugin/hadoop-configurations/cdhxx directory on the Pentaho Server, PRD, or PME:
- hbase-site.xml
- core-site.xml
- hdfs-site.xml
- hive-site.xml
- mapred-site.xml
- yarn-site.xml
Connect Other Pentaho Components to the Cloudera Cluster
These instructions explain how to create and test a connection to the cluster in the Pentaho Server, PRD, and PME. Creating and testing a connection to the cluster in Spoon involves two tasks:
- Set the active shim on PRD, PME, and the Pentaho Server
- Create and test the cluster connections
Set the Active Shim on PRD, PME, and the Pentaho Server
Modify the plugin.properties file to set the active shim for the Pentaho Server, PRD, and PME.
- Stop the component.
- Locate the pentaho-big-data-plugin directory for your component.
- Navigate to the hadoop-configurations directory.
- Navigate to the pentaho-big-data-plugin directory and open the plugin.properties file.
- Set the active.hadoop.configuration property to the directory name of the shim you want to make active. Here is an example:
1 |
active.hadoop.configuation=cdh54 |
- Save and close the plugin.properties file.
- Restart the component.
Create and Test Connections
Connection tests appear in the following table.
| Component | Test |
|---|---|
| Pentaho Server for DI | Create a transformation in Spoon and run it remotely. |
| Pentaho Server for BA | Create a connection to the cluster in the Data Source Wizard. |
| PME | Create a connection to the cluster in PME. |
| PRD | Create a connection to the cluster in PRD. |
Once you've connected to the cluster and its services properly, provide connection information to users who need access to the cluster and its services. Those users can only obtain access from computers that have been properly configured to connect to the cluster.
Here is what they need to connect:
- Hadoop distribution and version of the cluster
- HDFS, JobTracker, ZooKeeper, and Hive2/Impala Hostnames, IP addresses and port numbers
- Oozie URL (if used)
- Users also require the appropriate permissions to access the directories they need on HDFS. This typically includes their home directory and any other required directories.
They might also need more information depending on the job entries, transformation steps, and services they use. Here's a more detailed list of information that your users might need from you.
General Notes
Set Hive Database Connection Parameters (Secured Clusters Only)
To access Hive, you need to set several database connection parameters from within Spoon.
-
Verify the valid Kerberos principal values have been set to Hive.metastore.kerberos.principal and hive.server2.authentication.kerberos.principal in hive-site.xml.
-
Start Spoon.
-
In Spoon, open the Database Connection window.
-
Click Options.
-
Add the principal parameter and set it to the values that you noted in the hive-site.xml file. The principal typically looks like
hive/HiveServer2.pentaho.com@mydomain. -
Click OK to close the window.
Sqoop "Unsupported major.minor version" Error
If you are using Pentaho 6.0 and the Java version on your cluster is older than the Java version that Pentaho uses, you must change Pentaho's JDK so it is the same major version as the JDK on the cluster. The JDK that you install for Pentaho must meet the requirements in the Supported Components matrix. To learn how to download and install the JDK read this article.
Version-Specific Notes
The following are special topics for CDH.
CDH 5.4 Notes
The following notes address issues with CDH 5.4.
Simba Driver Support Note
If you are using Pentaho 6.0 or later, the CDH 5.4 shim supports the Cloudera JDBC Simba driver: Impala JDBC Connector 2.5.28 for Cloudera Enterprise. This replaces the Apache Hive JDBC that was supported previously in previous versions of the CDH 5.4 shim.
In the Database connection window, you will need to select the Cloudera Impala option. If Impala is secured on your cluster, you also need to supply KrbHostFQDN, KrbServiceName, and KrbRealm in the Options tab. For more information on how to set up a database connection see the database connection articles at help.pentaho.com.
You will need to install the driver in the shim directory for each Pentaho component (e.g., Spoon, Pentaho Server, PRD) you want to use.
- Download the Impala JDBC Connector 2.5.28 for Cloudera Enterprise driver.
- Copy the ImpalaJDBC41.jar to the pentaho-big-data-plugin/hadoop-configurations/cdhxx/lib directory.
- Stop and restart the component.
CDH 5.3 Notes
The following notes address issues with CDH 5.3.
Configuring High Availability for CDH 5.3
If you are configuring CDH 5.3 to be used in High Availability mode, we recommend that you use the Cloudera Manager "Download Client Configuration" feature. The Download Client Configuration feature provides a convenient way to get configuration files from the cluster for a service (such as HBase, HDFS, or YARN). Use this feature to download the unzip the configuration zip files to the pentaho-big-data-plugin/hadoop-configurations/cdh53 directory.
For more information on how to do this, see Cloudera documentation: http://www.cloudera.com/content/cloudera/en/documentation/core/v5-3-x/topics/cm_mc_client_config.html
Troubleshoot Cluster and Service Configuration Issues
The issues in this section explain how to resolve common configuration problems.
Shim and Configuration Issues
| Symptoms | Common Causes | Common Resolutions |
|---|---|---|
| No shim |
|
|
| Shim doesn't load |
|
|
| The file system's URL does not match the URL in the configuration file. | Configuration files (*-site.xml files) were not configured properly. | Verify that the configuration files were configured correctly. Verify that the core-site.xml file is configured correctly. See the instructions for your Hadoop distribution in the Set Up Pentaho to Connect to a Hadoop Cluster section of the Configuration article for details. |
Connection Problems
| Symptoms | Common Causes | Common Resolutions |
|---|---|---|
| Hostname incorrect or not resolving properly. |
|
|
| Port name is incorrect. |
|
|
| Can't connect. |
|
|
Directory Access or Permissions Issues
| Symptoms | Common Causes | Common Resolutions |
|---|---|---|
| Can't access directory. |
|
|
| Can't create, read, update, or delete files or directories |
Authorization and/or authentication issues. |
|
| Test file cannot be overwritten. | Pentaho test file is already in the directory. |
|
Oozie Issues
| Symptoms | Common Causes | Common Resolutions |
|---|---|---|
| Can't connect to Oozie. |
|
|
ZooKeeper Problems
| Symptoms | Common Causes | Common Resolutions |
|---|---|---|
| Can't connect to ZooKeeper. |
|
|
| ZooKeeper hostname or port not found or doesn't resolve properly. |
|
|