推荐系统实践:基于物品的协同过滤算法原理及实现(含改进算法)
基于物品的协同过滤算法(ItemCF)给用户推荐那些和他们之前喜欢的物品相似的物品。比如:该算法会因为你购买过《数据挖掘导论》而给你推荐《机器学习》。不过ItemCF算法不利用物品的内容属性计算物品之间的相似度,它主要通过分析用户的行为记录计算物品之间的相似度。该算法认为,物品A和物品B具有很大相似度的原因是因为喜欢物品A的用户大都也喜欢物品B。
基于物品的协同过滤算法主要分为两步。
1. 计算物品的相似度
1.1遍历训练数据,统计喜欢每个物品的用户数,存入movie_popular列表中,如movie_popular[i]表示喜欢电影i的用户数。
1.2建立物品相似度矩阵
如下图所示,左图为训练数据格式,右图为矩阵C,遍历训练数据,计算出喜欢两两物品用户数,填入矩阵C中,如同时喜欢物品a和物品b的用户有1人,则C[a][b] = 1。

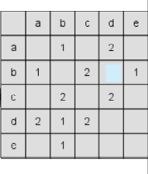
得到矩阵C后,利用如下公式计算物品之间的相似度。![]() 表示物品i和物品j的相似度,N(i)表示喜欢物品i的用户数,分子表示同时喜欢物品i和j的用户数。因此,该公式可以理解为喜欢物品i的用户中有多少比例的用户也喜欢物品j。
表示物品i和物品j的相似度,N(i)表示喜欢物品i的用户数,分子表示同时喜欢物品i和j的用户数。因此,该公式可以理解为喜欢物品i的用户中有多少比例的用户也喜欢物品j。

物品相似度计算公式的改进:上述公式存在一个问题,如果物品j很热门,很多人都喜欢,那么![]() 就会很大,接近于1。因此上述公式会造成任何物品都会和热门的物品有很大的相似度,这对于致力于挖掘长尾信息的推荐系统来说显然不是一个好的特性。为了避免推荐出热门的物品,可以用下面的公式:
就会很大,接近于1。因此上述公式会造成任何物品都会和热门的物品有很大的相似度,这对于致力于挖掘长尾信息的推荐系统来说显然不是一个好的特性。为了避免推荐出热门的物品,可以用下面的公式:
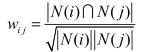
这个公式惩罚了物品j的权重,因此减轻了热门物品会和很多物品相似的可能性。
进一步改进物品相似度计算公式:惩罚活跃用户。假如有这么一个用户,他是开书店的,并且买了当当网上80%的书准备自己来卖,那么他的购物车里包含当当网80%的书。从前面的讨论来看,这意味着有很多很多书两两之间就产生了相似度,并且内存中将诞生一个非常大的稠密矩阵。
因此提出IUF(Inverse User Frequence),即用户活跃度对数的倒数的参数,来修正物品相似度的计算公式,其中u表示同时喜欢物品i和j的用户,N(u)表示用户u喜欢的物品数:
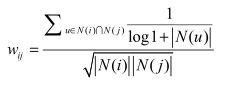
使用上述公式,利用矩阵C及movie_popular,计算得到两两物品的相似度,构建出物品相似度矩阵。
2. 针对目标用户u,找到和用户历史上感兴趣的物品最相似的物品集合。
K表示找到相似的物品数。N表示为用户推荐的物品数。
利用如下的公式计算用户u对物品 j 的感兴趣程度p(u, j):
其中,S( j, K)是和物品 j 最相似的K个物品的集合,N(u)是用户u喜欢的物品集合,![]() 是物品j和物品i的相似度,
是物品j和物品i的相似度,
![]() 表示用户u对物品i的兴趣。
表示用户u对物品i的兴趣。
该公式的意义在于:和用户历史上感兴趣的物品越相似的物品,越有可能在用户的推荐列表中获得比较高的排名。
![]()
然后根据感兴趣程度由高到低确定N个推荐给用户u的物品。
评测指标
将用户行为数据按照均匀分布随机划分为M份(如取M=8),挑选一份作为测试集,将剩下的M-1份作为训练集。为防止评测指标不是过拟合的结果,共进行M次实验,每次都使用不同的测试集。然后将M次实验测出的评测指标的平均值作为最终的评测指标。
3.1 召回率
对用户u推荐N个物品(记为R(u)),令用户u在测试集上喜欢的物品集合为T(u)
召回率描述有多少比例的用户-物品评分记录包含在最终的推荐列表中。
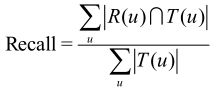
3.2 准确率
准确率描述最终的推荐列表中有多少比例是发生过的用户-物品评分记录
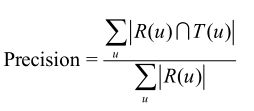
3.3 覆盖率
覆盖率反映了推荐算法发掘长尾的能力,覆盖率越高,说明推荐算法越能够将长尾中的物品推荐给用户。
分子部分表示实验中所有被推荐给用户的物品数目(集合去重),分母表示数据集中所有物品的数目
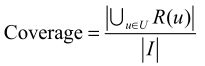
4. 实验部分
采用GroupLens提供的MovieLens数据集,http://www.grouplens.org/node/73 。本章使用中等大小的数据集,包含6000多用户对4000多部电影的100万条评分。该数据集是一个评分数据集,用户可以给电影评1-5分5个不同的等级。本文着重研究隐反馈数据集中TopN推荐问题,因此忽略了数据集中的评分记录。
代码如下
# coding = utf-8
# 基于项目的协同过滤推荐算法实现
import random
import math
from operator import itemgetter
class ItemBasedCF():
# 初始化参数
def __init__(self):
# 找到相似的20部电影,为目标用户推荐10部电影
self.n_sim_movie = 20
self.n_rec_movie = 10
# 将数据集划分为训练集和测试集
self.trainSet = {}
self.testSet = {}
# 用户相似度矩阵
self.movie_sim_matrix = {}
self.movie_popular = {}
self.movie_count = 0
print('Similar movie number = %d' % self.n_sim_movie)
print('Recommneded movie number = %d' % self.n_rec_movie)
# 读文件得到“用户-电影”数据
def get_dataset(self, filename, pivot=0.875):
trainSet_len = 0
testSet_len = 0
for line in self.load_file(filename):
user, movie, rating, timestamp = line.split('::')
if(random.random() < pivot):
self.trainSet.setdefault(user, {}) #相当于trainSet.get(user),若该键不存在,则设trainSet[user] = {},典中典
#键中键:形如{'1': {'1287': '2.0', '1953': '4.0', '2105': '4.0'}, '2': {'10': '4.0', '62': '3.0'}}
#用户1看了id为1287的电影,打分2.0
self.trainSet[user][movie] = rating
trainSet_len += 1
else:
self.testSet.setdefault(user, {})
self.testSet[user][movie] = rating
testSet_len += 1
print('Split trainingSet and testSet success!')
print('TrainSet = %s' % trainSet_len)
print('TestSet = %s' % testSet_len)
# 读文件,返回文件的每一行
def load_file(self, filename):
with open(filename, 'r') as f:
for i, line in enumerate(f):
if i == 0: # 去掉文件第一行的title
continue
yield line.strip('\r\n')
print('Load %s success!' % filename)
# 计算电影之间的相似度
def calc_movie_sim(self):
for user, movies in self.trainSet.items(): #循环取出一个用户和他看过的电影
for movie in movies:
if movie not in self.movie_popular:
self.movie_popular[movie] = 0
self.movie_popular[movie] += 1 #统计每部电影共被看过的次数
self.movie_count = len(self.movie_popular) #得到电影总数
print("Total movie number = %d" % self.movie_count)
for user, movies in self.trainSet.items(): #得到矩阵C,C[i][j]表示同时喜欢电影i和j的用户数
for m1 in movies:
for m2 in movies:
if m1 == m2:
continue
self.movie_sim_matrix.setdefault(m1, {})
self.movie_sim_matrix[m1].setdefault(m2, 0)
# self.movie_sim_matrix[m1][m2] += 1 #同时喜欢电影m1和m2的用户+1 21.75 10.5 16.67
self.movie_sim_matrix[m1][m2] += 1 /math.log(1 + len(movies)) #ItemCF-IUF改进,惩罚了活跃用户 22.00 10.65 14.98
print("Build co-rated users matrix success!")
# 计算电影之间的相似性
print("Calculating movie similarity matrix ...")
for m1, related_movies in self.movie_sim_matrix.items(): #电影m1,及m1这行对应的电影们
for m2, count in related_movies.items(): #电影m2 及 同时看了m1和m2的用户数
# 注意0向量的处理,即某电影的用户数为0
if self.movie_popular[m1] == 0 or self.movie_popular[m2] == 0:
self.movie_sim_matrix[m1][m2] = 0
else:
#计算出电影m1和m2的相似度
self.movie_sim_matrix[m1][m2] = count / math.sqrt(self.movie_popular[m1] * self.movie_popular[m2])
print('Calculate movie similarity matrix success!')
#添加归一化 precisioin=0.2177 recall=0.1055 coverage=0.1497
maxDict = {}
max = 0
for m1, related_movies in self.movie_sim_matrix.items():
for m2, _ in related_movies.items():
if self.movie_sim_matrix[m1][m2] > max:
max = self.movie_sim_matrix[m1][m2]
for m1, related_movies in self.movie_sim_matrix.items(): #归一化
for m2, _ in related_movies.items():
# self.movie_sim_matrix[m1][m2] = self.movie_sim_matrix[m1][m2] / maxDict[m2]
self.movie_sim_matrix[m1][m2] = self.movie_sim_matrix[m1][m2] / max
# 针对目标用户U,找到K部相似的电影,并推荐其N部电影
def recommend(self, user):
K = self.n_sim_movie #找到相似的20部电影
N = self.n_rec_movie #为用户推荐10部
rank = {}
watched_movies = self.trainSet[user] #该用户看过的电影
for movie, rating in watched_movies.items(): #遍历用户看过的电影及对其评价
#找到与movie最相似的K部电影,遍历电影及与movie相似度
for related_movie, w in sorted(self.movie_sim_matrix[movie].items(), key=itemgetter(1), reverse=True)[:K]:
if related_movie in watched_movies: #如果用户已经看过了,不推荐了
continue
rank.setdefault(related_movie, 0)
rank[related_movie] += w * float(rating) #计算用户对该电影的兴趣
#返回用户最感兴趣的N部电影
return sorted(rank.items(), key=itemgetter(1), reverse=True)[:N]
# 产生推荐并通过准确率、召回率和覆盖率进行评估
def evaluate(self):
print('Evaluating start ...')
N = self.n_rec_movie #要推荐的电影数
# 准确率和召回率
hit = 0
rec_count = 0
test_count = 0
# 覆盖率
all_rec_movies = set()
for i, user in enumerate(self.trainSet):
test_moives = self.testSet.get(user, {}) #测试集中用户喜欢的电影
rec_movies = self.recommend(user) #得到推荐的电影及计算出的用户对它们的兴趣
for movie, w in rec_movies: #遍历给user推荐的电影
if movie in test_moives: #测试集中有该电影
hit += 1 #推荐命中+1
all_rec_movies.add(movie)
rec_count += N
test_count += len(test_moives)
precision = hit / (1.0 * rec_count)
recall = hit / (1.0 * test_count)
coverage = len(all_rec_movies) / (1.0 * self.movie_count)
print('precisioin=%.4f\trecall=%.4f\tcoverage=%.4f' % (precision, recall, coverage))
if __name__ == '__main__':
rating_file = 'ratings2.csv'
itemCF = ItemBasedCF()
itemCF.get_dataset(rating_file)
itemCF.calc_movie_sim()
itemCF.evaluate()# coding = utf-8运行结果:
precisioin=0.2185 recall=0.1056 coverage=0.1547