Python爬取百度文库付费文档(PDF)
Python爬取百度文库付费文档(PDF)@TOC
PS:本文为本人学习python的一个小分享,仅供学习和参考使用,不可做商业利益的盗取!
工具准备
Python3.x;
Python库:selenium、requests;
爬取页面及爬取分析
https://wenku.baidu.com/view/9a5a21cf964bcf84b9d57bea?pn=50
打开网址,鼠标置于第一页上,右键打开元素,可以看到图片来自于一个链接。
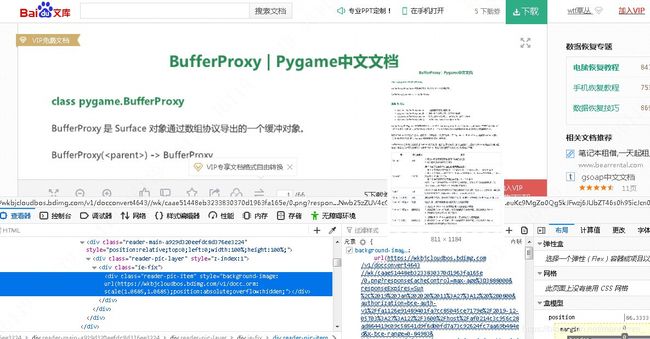 我们打开这个链接。
我们打开这个链接。
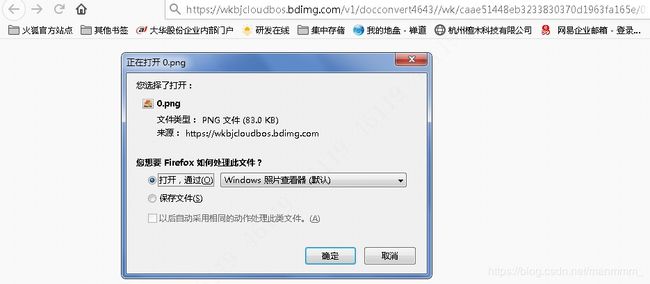 可以很清楚的看到,这是一个图片的下载链接。所以我们需要爬取这个文档,有一个很清晰的思路就是把每一页的图片链接截取下来,然后再通过requests打开该链接来保存图片,最后将所有图片合成PDF即可。
可以很清楚的看到,这是一个图片的下载链接。所以我们需要爬取这个文档,有一个很清晰的思路就是把每一页的图片链接截取下来,然后再通过requests打开该链接来保存图片,最后将所有图片合成PDF即可。
功能模块代码的实现
实现图片链接的获取
首先,先介绍下selenium库,Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。所以,你在人工操作浏览器时可以看到的东西,在selenium也可以看到。这里,我们就使用selenium来获取这个页面的源代码。
from selenium import webdriver
driver = webdriver.Firefox() #selenium支持火狐、谷歌等浏览器
driver.get('https://wenku.baidu.com/view/9a5a21cf964bcf84b9d57bea?pn=50')
print(driver.page_source)
我们先打印下源码看看。由于源码太长,我只贴出跟我们需要爬取内容相关的部分。
"bd" id="pageNo-1" data-page-no="1" data-mate-width="892.83" data-mate-height="1263" style="height:1011.4411478109px;" data-scale="0.70691211401425" data-render="1">"reader-parent-a929d320eefdc8d376ee3224 reader-parent " style="position:relative;top:0;left:0;-moz-transform:scale(0.99);-moz-transform-origin:left top;">"reader-wrapa929d320eefdc8d376ee3224" style="position:absolute;top:0;left:0;width:100%;height:100%;">"reader-main-a929d320eefdc8d376ee3224" style="position:relative;top:0;left:0;width:100%;height:100%;">"reader-pic-layer" style="z-index:1">"ie-fix">"reader-pic-item" style="background-image: url(https://wkbjcloudbos.bdimg.com/v1/docconvert4643//wk/caae51448eb3233830370d1963fa165e/0.png?responseCacheControl=max-age%3D3888000&responseExpires=Sun%2C%2019%20Jan%202020%2014%3A13%3A06%20%2B0800&authorization=bce-auth-v1%2Ffa1126e91489401fa7cc85045ce7179e%2F2019-12-05T06%3A13%3A06Z%2F3600%2Fhost%2Fc895ec975bc2d19dc54d3f80ffe35c865e469fdabcd3501ae7ad5af14af5896a&x-bce-range=0-84983&token=eyJ0eXAiOiJKSVQiLCJ2ZXIiOiIxLjAiLCJhbGciOiJIUzI1NiIsImV4cCI6MTU3NTUyOTk4NiwidXJpIjp0cnVlLCJwYXJhbXMiOlsicmVzcG9uc2VDYWNoZUNvbnRyb2wiLCJyZXNwb25zZUV4cGlyZXMiLCJ4LWJjZS1yYW5nZSJdfQ%3D%3D.15JLNbl07gJ1bGi0wBW6Jqm%2BPpuUyz7gJlsdIgf%2FdLc%3D.1575529986);background-position:0px 0px;width:812px;height:1179px;z-index:1360;left:73.7565px;top:86.32625000000002px;opacity:1;-moz-transform: scale(1.0685,1.0685);position:absolute;overflow:hidden;">
我们可以看到,该图片元素ID为“pageNo-1”,图片链接在style="background-image:中。通常我们爬取源码都是利用BeautifulSoup库与lxml配合解析的。但这里利用这两个库解析都打印的源码存在丢失现象,可能的原因是该源码编码中存在gb2312编码。我也尝试了不同的解析库,都不行。于是,这里我们可以另辟蹊径,将所有的网页源码存于一个字符串中,然后对字符串进行一系列的处理,得到我们需要的url连接。
mystring = driver.page_source; #将源码赋值给一个字符串
page = 'pageNo-1'
idx1 = mystring.find('+ page) #找出= mystring[idx1:] #通过索引先将索引前面的所有字符串删除
idx1 = mystring.find("https") #我们可以发现URL的链接都是已https开头的
idx2 = mystring.find(");background-position") #URL的结尾后面都跟着“);background-position“
mystring = mystring[idx1:idx2] #然后再根据这两个索引,截取URL连接。这里需要注意的是python前后缩影截取为左闭右开的区间,及[idx1:idx2)
pringt(mystring)#输出处理后的字符串检查
打印结果为:https://wkbjcloudbos.bdimg.com/v1/docconvert4643//wk/caae51448eb3233830370d1963fa165e/0.png?responseCacheControl=max-age%3D3888000&responseExpires=Sun%2C%2019%20Jan%202020%2014%3A13%3A06%20%2B0800&authorization=bce-auth-v1%2Ffa1126e91489401fa7cc85045ce7179e%2F2019-12-05T06%3A13%3A06Z%2F3600%2Fhost%2Fc895ec975bc2d19dc54d3f80ffe35c865e469fdabcd3501ae7ad5af14af5896a&x-bce-range=0-84983&token=eyJ0eXAiOiJKSVQiLCJ2ZXIiOiIxLjAiLCJhbGciOiJIUzI1NiIsImV4cCI6MTU3NTUyOTk4NiwidXJpIjp0cnVlLCJwYXJhbXMiOlsicmVzcG9uc2VDYWNoZUNvbnRyb2wiLCJyZXNwb25zZUV4cGlyZXMiLCJ4LWJjZS1yYW5nZSJdfQ%3D%3D.15JLNbl07gJ1bGi0wBW6Jqm%2BPpuUyz7gJlsdIgf%2FdLc%3D.1575529986
我们打开这个链接,发现无法打开。回到我们手动打开的页面,复制一下正确的网址与之进行对比。
正确的URL:https://wkbjcloudbos.bdimg.com/v1/docconvert4643//wk/caae51448eb3233830370d1963fa165e/0.png?responseCacheControl=max-age%3D3888000&responseExpires=Sun%2C%2019%20Jan%202020%2011%3A27%3A12%20%2B0800&authorization=bce-auth-v1%2Ffa1126e91489401fa7cc85045ce7179e%2F2019-12-05T03%3A27%3A12Z%2F3600%2Fhost%2Faf0214c3c956c28ad864419c09c58541d9f6d00fd7a73c92624fc7aa69b484ed&x-bce-range=123043-197963&token=eyJ0eXAiOiJKSVQiLCJ2ZXIiOiIxLjAiLCJhbGciOiJIUzI1NiIsImV4cCI6MTU3NTUyMDAzMiwidXJpIjp0cnVlLCJwYXJhbXMiOlsicmVzcG9uc2VDYWNoZUNvbnRyb2wiLCJyZXNwb25zZUV4cGlyZXMiLCJ4LWJjZS1yYW5nZSJdfQ%3D%3D.uGj%2F8Z9kAT4ldgOX62nSX2By9c7pOhNhA1g90oRH%2Bxg%3D.1575520032
这里请忽略链接的不同,该图片链接本身就是动态链接,每次链接都不同,我们只需要关注格式。对比发现,我们打印的URL中多出了几个“amp;”
https://wkbjcloudbos.bdimg.com/v1/docconvert4643//wk/caae51448eb3233830370d1963fa165e/0.png?responseCacheControl=max-age%3D3888000&responseExpires=Sun%2C%2019%20Jan%202020%2014%3A13%3A06%20%2B0800&==amp;==authorization=bce-auth-v1%2Ffa1126e91489401fa7cc85045ce7179e%2F2019-12-05T06%3A13%3A06Z%2F3600%2Fhost%2Fc895ec975bc2d19dc54d3f80ffe35c865e469fdabcd3501ae7ad5af14af5896a&x-bce-range=0-84983&token=eyJ0eXAiOiJKSVQiLCJ2ZXIiOiIxLjAiLCJhbGciOiJIUzI1NiIsImV4cCI6MTU3NTUyOTk4NiwidXJpIjp0cnVlLCJwYXJhbXMiOlsicmVzcG9uc2VDYWNoZUNvbnRyb2wiLCJyZXNwb25zZUV4cGlyZXMiLCJ4LWJjZS1yYW5nZSJdfQ%3D%3D.15JLNbl07gJ1bGi0wBW6Jqm%2BPpuUyz7gJlsdIgf%2FdLc%3D.1575529986
我们把“amp;”删除了试试。mystring = mystring.replace('amp;', '')
再次打印后打开链接就可以发现,可以正常下载了。到此,图片链接获取功能实现。
实现图片的下载
图片的下载我们可以使用requests.content来实现。
r = requests.get(mystring)
with open(page + '.png', 'wb') as png:
png.write(r.content)
png.close()
运行后就可以看到一个pageNo-1.png图片的生成。打开看看,果然就是我们刚刚看到的第一页。
实现浏览器下滑及按钮的点击
上面两个模块只是实现的第一页的图片的下载。百度文库中,第三页都免会有一个打开更多页的按钮,我们需要点击该按钮才可以获得更多的页面。我们先通过浏览器获得该按钮元素的ID或者class name。
"html-reader-go-more" class="banner-wrap more-btn-banner" style="height: auto;">
"banner-core-wrap super-vip">"doc-banner-text">下载文档到电脑,使用更方便 "doc-banner-value">"icon-ticket">5下载券"doc-banner-ticket-rights">(您持有0下载券,积分不足无法兑换)"doc-banner-btns super-vip"> "btn-pay-vip">VIP免费下载"doc-banner-tip super-vip">"doc-banner-rights-wrap">"icon-triangle" style="left: 221.5px;">"download-pro-doc">享VIP专享文档下载特权"download-share-doc">赠共享文档下载特权"yuedu-vip">赠百度阅读VIP精品版
"continue-to-read">
"banner-more-btn">
"moreBtn goBtn">
还剩63页未读,
"fc2e">继续阅读
"down-arrow goBtn">
"hengxian">
"wubai-wrap">
"wubai-title">
"wubai-icon">
很直观的就可以看到,该按钮class=“down-arrow goBtn”。通过xpath来定位该按钮,再进行click的动作即可实现点击按钮。
button = driver.find_element_by_xpath("//p[@class='down-arrow goBtn']")
button.click()
time.sleep(2) #请在头文件加入 import time,单位秒
这里我引入了time库的sleep函数,是考虑到网速问题,让浏览器缓冲一下。
按钮的点击实现了。我们还会发现一个问题,那就是有时候后面几页的图片无法加载,这里我的处理方式是,没爬取一个页面就讲滑条滑动到该页,同时缓冲2S保证图片的加载成功。很可惜selenium没有关于浏览器滑条的操作,这里需要配合JS进行滑条的操作。
target = driver.find_element_by_id(page)#page={pageNo-1,pageNo-2,....}是图片的ID,上文有提到
driver.execute_script("arguments[0].scrollIntoView();", target)#上一句是找到该元素,这一句是运用JS滑动滑条到该元素
time.sleep(2)
代码的集合
上面那个章节将我们需要的功能都实现了(其实还有一个功能模块我没有弄,那就是图片合成PDF。但是我比较懒,而且现在WORD直接一键插入所有图片,然后输出成PDF比较方便,所以这里我就没弄,只是保存了所有的图片),最后我们只需要进行整合即可。
此处该文档共有两个链接。
1-50页链接为:https://wenku.baidu.com/view/9a5a21cf964bcf84b9d57bea?pn=50
50-66页链接为:https://wenku.baidu.com/view/9a5a21cf964bcf84b9d57bea?pn=51
所以爬取的时候记得更换链接。
代码集合如下:
from selenium import webdriver
import time
import requests
driver = webdriver.Firefox()
driver.get('https://wenku.baidu.com/view/9a5a21cf964bcf84b9d57bea?pn=50')
for i in range(50):
if i == 3:
target = driver.find_element_by_id('html-reader-go-more')
driver.execute_script("arguments[0].scrollIntoView();", target)
button = driver.find_element_by_xpath("//p[@class='down-arrow goBtn']")
button.click()
time.sleep(2)
page = 'pageNo-' + str(i+1)
print(page)
target = driver.find_element_by_id(page)
driver.execute_script("arguments[0].scrollIntoView();", target)
time.sleep(2)
mystring = driver.page_source;
idx1 = mystring.find('+ page)
print(idx1)
mystring = mystring[idx1:]
idx1 = mystring.find("https")
print(idx1)
idx2 = mystring.find(");background-position")
print(idx2)
mystring = mystring[idx1:idx2]
mystring = mystring.replace('amp;', '')
if mystring.startswith('http') :
r = requests.get(mystring)
with open(page + '.png', 'wb') as png:
png.write(r.content)
png.close()
else:
print(mystring)
driver.get('https://wenku.baidu.com/view/9a5a21cf964bcf84b9d57bea?pn=51')
for i in range(50,66):
page = 'pageNo-' + str(i + 1)
print(page)
target = driver.find_element_by_id(page)
driver.execute_script("arguments[0].scrollIntoView();", target)
time.sleep(2)
mystring = driver.page_source;
idx1 = mystring.find('+ page)
print(idx1)
mystring = mystring[idx1:]
idx1 = mystring.find("https")
print(idx1)
idx2 = mystring.find(");background-position")
print(idx2)
mystring = mystring[idx1:idx2]
mystring = mystring.replace('amp;', '')
if mystring.startswith('http'):
r = requests.get(mystring)
with open(page + '.png', 'wb') as png:
png.write(r.content)
png.close()
else:
print(mystring)
driver.quit()
总结
1.selenium确实好用,运用好了可以做很多事情;
2.BeautifulSoup与lxml无法解析网页时,多换种思路,也可以实现功能;
3.新学python,若有错误,请大神们轻喷,也请指正,谢谢;
4.本文仅供学习python的selenium库的学习参考,切勿用于商业利益,我们要尊重别人的知识产权。