YOLOV3训练数据
//////////
出处:https://www.cnblogs.com/laozhanghahaha/p/10527474.html
1. 在ubuntu18.04下安装yolov3
安装darknet
按ctrl+atl+t 打开终端, 并在终端下依次输入以下命令
git clone https://github.com/pjreddie/darknet.git
cd darknet
make 如果成功的话你会看到以下信息
| 1 2 3 4 5 6 |
|
编译完成后键入以下命令运行darknet
./darknet| 1 |
|
你将会看到以下输出结果
使用GPU编译(可选)
如果想让yolo运行的更快的话, 可以使用GPU 加速。你的电脑中应该有Nvidia GPU 并安装cuda。 在安装完cuda后,在本目录下修改 Makefile第一行
GPU=1如果使用Opencv的话,则将makefile里,将OPENCV=0改为
OPENCV=1然后执行
make
下载pre-trained model
可以在这里下载预训练模型, 或者在终端输入以下命令
wget https://pjreddie.com/media/files/yolov3.weights然后训练你的detector
./darknet detect cfg/yolov3.cfg yolov3.weights data/eagle.jpg正常情况下你会看到如下输出


然后在终端键入
这样就可以使用cuda啦, darknet在默认情况下会使用你系统里第零个块显卡 (如果你成功安装了cuda, 在终端输入nvidia-smi可以看到自己的显卡情况)。 如果你想修改darknet可以使用的显卡,你可以给他一个可选的命令 -i
| 1 |
|
这样darknet就会使用你的第一块显卡。
下载pre-trained model
可以在这里下载预训练模型, 或者在终端输入以下命令
| 1 |
|
然后训练你的detector
| 1 |
|
正常情况下你会看到如下输出
darknet会把他的检测的结果, 以及confidence输出出来,因为我没有在darknet下编译opencv所以检测结果不会直接显示出来, 他会把这个结果保存在你的darknet目录下。
///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
1.出处:https://blog.csdn.net/weixin_43981221/article/details/88714617
关于VOC的培训YOLO
如果您想要使用不同的训练方案,超参数或数据集,您可以从头开始训练YOLO。以下是如何使其在Pascal VOC数据集上运行。
获取Pascal VOC数据
要训练YOLO,您将需要2007年至2012年的所有VOC数据。您可以在此处找到数据的链接。要获取所有数据,在darknet下新建一个文件夹VOCdevkit,并从该目录运行:
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar
为VOC生成标签
现在我们需要生成Darknet使用的标签文件。Darknet希望.txt每个图像都有一个文件,图像中的每个地面实况对象都有一行,如下所示
其中x,y,width,和height相对于图像的宽度和高度。要生成这些文件,需要执行如下操作。
wget https://pjreddie.com/media/files/voc_label.py
python voc_label.py
ls////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
其中,voc_label.py的使用注释如下(出处:https://www.cnblogs.com/pprp/p/9525508.html):
训练Pascal VOC格式的数据
- 生成Labels,因为darknet不需要xml文件,需要.txt文件(格式: )
用voc_label.py(位于./scripts)cat voc_label.py 共修改四处
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')] #替换为自己的数据集
classes = ["head", "eye", "nose"] #修改为自己的类别
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id)) #将数据集放于当前目录下
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2007_train.txt 2007_val.txt > train.txt") #修改为自己的数据集用作训练/////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////

cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt将2007和2012所有训练文件放在一个一起。
修改Pascal数据的Cfg
现在转到Darknet目录。我们必须更改cfg/voc.data配置文件以指向您的数据:
classes= 20
train = /train.txt
valid = 2007_test.txt
names = data/voc.names
backup = backup 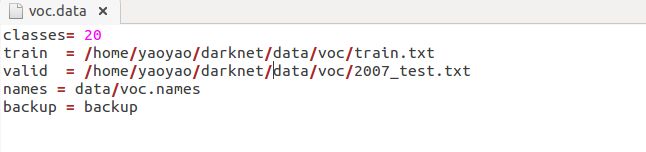
下载预训练卷积权重
对于训练,我们使用在Imagenet上预训练的卷积权重。我们使用darknet53模型中的权重。您可以在此处下载卷积图层的权重(76 MB)。
wget https://pjreddie.com/media/files/darknet53.conv.74训练模型
现在我们可以训练!运行命令:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
/////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
出处:https://blog.csdn.net/dcrmg/article/details/81296520
4. 修改配置文件
1) 修改data/voc.names 文件
把 voc.names文件内容改成自己的分类,例如有3个分类class_1,class_2,class_3,则voc.names内容改为:
class_1
class_2
class_3
2) 修改cfg/voc.data文件
根据自己的实际情况做以下修改:
classes = N #(N为自己的分类数量,如有10类不同的对象,N = 10)
train = /home/XXX/darknet/trainImagePath.txt # 训练集完整路径列表
valid = /home/XXX/darknet/validateImagePath.txt # 测试集完整路径列表
names = data/voc.names # 类别文件
backup = backup #(训练结果保存在darknet/backup/目录下)
3) 修改cfg/yolov3-voc.cfg 文件
1. classes = N (N为自己的分类数)
2. 修改每一个[yolo]层(一共有3处)之前的filters为 3*(classes+1+4),如有3个分类,则修改 filters = 24
3. (可选) 修改训练的最大迭代次数, max_batches = N
5. YOLOv3训练
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
训练完成后结果文件 ‘yolov3-voc_final.weights’ 保存在 backup文件中。
6. 自训练模型测试
./darknet detector test cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_final.weights 01.jpg
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
出处:https://www.cnblogs.com/pprp/p/9525508.html
测试Yolo模型
测试单张图片:
- 测试单张图片,需要编译时有OpenCV支持:
batch和subdivisions两项必须为1。- 测试时还可以用
-thresh和-hier选项指定对应参数。
./darknet detector test cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_20000.weights Eminem.jpg批量测试图片
-
yolov3-voc.cfg(cfg文件夹下)文件中batch和subdivisions两项必须为1。 -
在detector.c中增加头文件:
#include/* Many POSIX functions (but not all, by a large margin) */ #include /* open(), creat() - and fcntl() */
在前面添加GetFilename(char p)函数
#include "darknet.h"
#include //需增加的头文件
#include
#include
#include //需增加的头文件
static int coco_ids[] = {1,2,3,4,5,6,7,8,9,10,11,13,14,15,16,17,18,19,20,21,22,23,24,25,27,28,31,32,33,34,35,36,37,38,39,40,41,42,43,44,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,67,70,72,73,74,75,76,77,78,79,80,81,82,84,85,86,87,88,89,90};
char *GetFilename(char *p)
{
static char name[30]={""};
char *q = strrchr(p,'/') + 1;
strncpy(name,q,20);
return name;
}
-
用下面代码替换detector.c文件(example文件夹下)的void test_detector函数(注意有3处要改成自己的路径)
void test_detector(char *datacfg, char *cfgfile, char *weightfile, char *filename, float thresh, float hier_thresh, char *outfile, int fullscreen)
{
list *options = read_data_cfg(datacfg);
char *name_list = option_find_str(options, "names", "data/names.list");
char **names = get_labels(name_list);
image **alphabet = load_alphabet();
network *net = load_network(cfgfile, weightfile, 0);
set_batch_network(net, 1);
srand(2222222);
double time;
char buff[256];
char *input = buff;
float nms=.45;
int i=0;
while(1){
if(filename){
strncpy(input, filename, 256);
image im = load_image_color(input,0,0);
image sized = letterbox_image(im, net->w, net->h);
//image sized = resize_image(im, net->w, net->h);
//image sized2 = resize_max(im, net->w);
//image sized = crop_image(sized2, -((net->w - sized2.w)/2), -((net->h - sized2.h)/2), net->w, net->h);
//resize_network(net, sized.w, sized.h);
layer l = net->layers[net->n-1];
float *X = sized.data;
time=what_time_is_it_now();
network_predict(net, X);
printf("%s: Predicted in %f seconds.\n", input, what_time_is_it_now()-time);
int nboxes = 0;
detection *dets = get_network_boxes(net, im.w, im.h, thresh, hier_thresh, 0, 1, &nboxes);
//printf("%d\n", nboxes);
//if (nms) do_nms_obj(boxes, probs, l.w*l.h*l.n, l.classes, nms);
if (nms) do_nms_sort(dets, nboxes, l.classes, nms);
draw_detections(im, dets, nboxes, thresh, names, alphabet, l.classes);
free_detections(dets, nboxes);
if(outfile)
{
save_image(im, outfile);
}
else{
save_image(im, "predictions");
#ifdef OPENCV
cvNamedWindow("predictions", CV_WINDOW_NORMAL);
if(fullscreen){
cvSetWindowProperty("predictions", CV_WND_PROP_FULLSCREEN, CV_WINDOW_FULLSCREEN);
}
show_image(im, "predictions",0);
cvWaitKey(0);
cvDestroyAllWindows();
#endif
}
free_image(im);
free_image(sized);
if (filename) break;
}
else {
printf("Enter Image Path: ");
fflush(stdout);
input = fgets(input, 256, stdin);
if(!input) return;
strtok(input, "\n");
list *plist = get_paths(input);
char **paths = (char **)list_to_array(plist);
printf("Start Testing!\n");
int m = plist->size;
if(access("/home/learner/darknet/data/outv3tiny_dpj",0)==-1)//"/home/learner/darknet/data"修改成自己的路径
{
if (mkdir("/home/learner/darknet/data/outv3tiny_dpj",0777))//"/home/learner/darknet/data"修改成自己的路径
{
printf("creat file bag failed!!!");
}
}
for(i = 0; i < m; ++i){
char *path = paths[i];
image im = load_image_color(path,0,0);
image sized = letterbox_image(im, net->w, net->h);
//image sized = resize_image(im, net->w, net->h);
//image sized2 = resize_max(im, net->w);
//image sized = crop_image(sized2, -((net->w - sized2.w)/2), -((net->h - sized2.h)/2), net->w, net->h);
//resize_network(net, sized.w, sized.h);
layer l = net->layers[net->n-1];
float *X = sized.data;
time=what_time_is_it_now();
network_predict(net, X);
printf("Try Very Hard:");
printf("%s: Predicted in %f seconds.\n", path, what_time_is_it_now()-time);
int nboxes = 0;
detection *dets = get_network_boxes(net, im.w, im.h, thresh, hier_thresh, 0, 1, &nboxes);
//printf("%d\n", nboxes);
//if (nms) do_nms_obj(boxes, probs, l.w*l.h*l.n, l.classes, nms);
if (nms) do_nms_sort(dets, nboxes, l.classes, nms);
draw_detections(im, dets, nboxes, thresh, names, alphabet, l.classes);
free_detections(dets, nboxes);
if(outfile){
save_image(im, outfile);
}
else{
char b[2048];
sprintf(b,"/home/learner/darknet/data/outv3tiny_dpj/%s",GetFilename(path));//"/home/leaner/darknet/data"修改成自己的路径
save_image(im, b);
printf("save %s successfully!\n",GetFilename(path));
/*
#ifdef OPENCV
//cvNamedWindow("predictions", CV_WINDOW_NORMAL);
if(fullscreen){
cvSetWindowProperty("predictions", CV_WND_PROP_FULLSCREEN, CV_WINDOW_FULLSCREEN);
}
//show_image(im, "predictions");
//cvWaitKey(0);
//cvDestroyAllWindows();
#endif*/
}
free_image(im);
free_image(sized);
if (filename) break;
}
}
}
}- 重新进行编译
make clean
make
- 开始批量测试
./darknet detector test cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_20000.weights- 输入Image Path(所有的测试文件的路径,可以复制voc.data中valid后边的路径):
/home/learner/darknet/data/voc/2007_test.txt # 完整路径- 结果都保存在
./data/out文件夹下 -
生成预测结果
生成预测结果
./darknet detector valid- yolov3-voc.cfg(cfg文件夹下)
文件中batch和subdivisions两项必须为1。 - 结果生成在
results指定的目录下以results,那么默认为/results - 执行语句如下:在终端只返回用时,在./results/comp4_det_test_[类名].txt里保存测试结果
-
./darknet detector valid cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_20000.weights
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////