CFS任务的负载均衡(框架篇)
强烈推荐下之前的雄文《为什么Linux CFS调度器没有带来惊艳的碾压效果?》
我们描述负载均衡的系列文章一共三篇,第一篇是框架部分,即本文,主要描述了负载均衡相关的原理、场景和框架。后面的两篇是对均衡代码的情景分析,通过对load balance、task placement和active upmigration几个典型的负载均衡来呈现其实现细节,稍后发布,敬请期待。
本文出现的内核代码来自Linux5.4.28,如果有兴趣,读者可以配合代码阅读本文。
一、什么是负载均衡
1、什么是CPU负载(load)
CPU负载是一个很容易和CPU利用率(utility)混淆的概念。CPU利用率是CPU忙闲的比例,例如在一个周期为1000ms的窗口中观察CPU的情况,如果500ms的时间在执行任务,500ms的时间处于idle状态,那么在这个窗口中CPU的利用率是50%。
在CPU利用率没有达到100%的时候,利用率基本上等于负载,一旦当CPU利用率达到了100%的时候,利用率其实是无法给出CPU负载的状况,因为大家的利用率都是100%,利用率相等,但是并不意味着CPUs的负载也是相等的,因为这时候不同CPU上runqueue中等待执行的任务数目不同,直觉上runque上挂着10任务的CPU承压比挂着5个任务的CPU的负载要更重一些。因此,早期的CPU负载是使用runqueue深度来描述的。
显然,仅仅使用runqueue深度来表示CPU负载是一个很粗略的概念,我们可以举一个简单的例子:当前CPU A和CPU B上都挂了1个任务,但是A上挂的任务是一个重载任务,而B上挂的是一个经常sleep的轻载任务,那么仅仅从runqueue深度来描述CPU负载就有失偏颇了。因此,现代调度器往往使用CPU runqueue上task load之和来表示CPU load。这样,对CPU负载的跟踪就变成了对任务负载的跟踪。
3.8版本的linux内核引入了PELT算法来跟踪每一个sched entity的负载,把负载跟踪的算法从per-CPU进化到per-entity。PELT算法不但能知道CPU的负载,而且知道负载来自哪一个调度实体,从而可以更精准的进行负载均衡。
2、什么是均衡
对于负载均衡而言,并不是把整个系统的负载平均的分配到系统中的各个CPU上。实际上,我们还是必须要考虑系统中各个CPU的算力,让CPU获得和其算力匹配的负载。例如在一个6个小核+2个大核的系统中,整个系统如果有800的负载,那么每个CPU上分配100的负载其实是不均衡的,因为大核CPU可以提供更强的算力。
什么是CPU算力(capacity),所谓算力就是描述CPU的能够提供的计算能力。在同样的频率下,一个微架构是A77的CPU显然算力要大于A57的CPU。如果CPU的微架构都是一样的,那么一个最大频率是2.2GHz的CPU算力肯定是大于最大频率是1.1GHz的CPU。因此,确定了微架构和最大频率,一个CPU的算力就基本确定了。Cpufreq系统会根据当前的CPU util来调节CPU当前的运行频率,但这并不能改变CPU算力。只有当CPU最大运行频率发生变化的时候(例如触发温控,限制了该CPU的最大频率),CPU的算力才会随之变化。
此外,本文主要描述CFS任务的均衡(RT的均衡不考虑负载,是在另外的维度),因此在考虑CPU算力的时候,需要把CPU用于执行rt和irq的算力去掉,使用该CPU可用于CFS的算力。因此,CFS任务均衡中使用的CPU算力其实一个不断变化的值,需要经常更新。为了让CPU算力和任务负载可以对比,实际上我们采用了归一化的方式,即系统中处理能力最强的CPU运行在最高频率的算力是1024,其他的CPU算力根据微架构和运行频率响应的调整其算力。
有了任务负载就可以得到CPU负载,配合系统中各个CPU的算力,看起来我们就可以完成负载均衡的工作,然而事情没有那么简单,当负载不均衡的时候,任务需要在CPU之间迁移,不同形态的迁移会有不同的开销。例如一个任务在小核cluster上的CPU之间的迁移所带来的性能开销一定是小于任务从小核cluster的CPU迁移到大核cluster的开销。因此,为了更好的执行负载均衡,我们需要构建和CPU拓扑相关的数据结构,也就是调度域和调度组的概念。
3、调度域(sched domain)和调度组(sched group)
负载均衡的复杂性主要和复杂的系统拓扑有关。由于当前CPU很忙,我们把之前运行在该CPU上的一个任务迁移到新的CPU上的时候,如果迁移到新的CPU是和原来的CPU在不同的cluster中,性能会受影响(因为会cache flush)。
但是对于超线程架构,cpu共享cache,这时候超线程之间的任务迁移将不会有特别明显的性能影响。NUMA上任务迁移的影响又不同,我们应该尽量避免不同NUMA node之间的任务迁移,除非NUMA node之间的均衡达到非常严重的程度。
总之,一个好的负载均衡算法必须适配各种cpu拓扑结构。为了解决这些问题,linux内核引入了sched_domain的概念。
内核中struct sched_domain来描述调度域,其主要的成员如下:

一旦形成了调度域,那么负载均衡就被限制在了该调度域内,在该调度域内进行均衡的时候不考虑系统中其他调度域的CPU负载情况,只考虑该调度域内的sched group之间的负载是否均衡。对于base domain,其所属的sched group中只有一个cpu,对于更高level的sched domain,其所属的sched group中可能会有多个cpu core。内核中struct sched_group来描述调度组,其主要的成员如下:

上面的描述过于枯燥,我们后面会使用一个具体的例子来描述负载如何在各个level的sched domain上进行均衡的,不过在此之前,我们先看看负载均衡的整体软件架构。
二、负载均衡的软件架构
负载均衡的整体软件结构图如下:

负载均衡模块主要分两个软件层次:核心负载均衡模块和class-specific均衡模块。内核对不同的类型的任务有不同的均衡策略,普通的CFS(complete fair schedule)任务和RT、Deadline任务处理方式是不同的,由于篇幅原因,本文主要讨论CFS任务的负载均衡。
为了更好的进行CFS任务的均衡,系统需要跟踪任务负载和CPU负载。跟踪任务负载是主要有两个原因:
(1)判断该任务是否适合当前CPU算力。
(2)如果判定需要均衡,那么需要在CPU之间迁移多少的任务才能达到平衡?有了任务负载跟踪模块,这个问题就比较好回答了。
对CPU负载的跟踪不仅要考虑每一个CPU的负载,还要汇聚cluster上所有负载,方便计算cluster之间负载的不均衡状况。
为了更好的进行高效的均衡,我们还需要构建调度域的层级结构(sched domain hierarchy),图中显示的是二级结构。手机场景多半是二级结构,支持NUMA的服务器场景可能会形成更复杂的结构。通过DTS和CPU topo子系统,我们可以构建sched domain层级结构,用于具体的均衡算法。
有了上面描述的基础设施,那么什么时候进行负载均衡呢?这主要和调度事件相关,当发生任务唤醒、任务创建、tick到来等调度事件的时候,我们可以检查当前系统的不均衡情况,并酌情进行任务迁移,以便让系统负载处于平衡状态。
三、如何做负载均衡
1、一个CPU拓扑示例
我们以一个4小核+4大核的处理器来描述CPU的domain和group:

在上面的结构中,sched domain是分成两个level,base domain称为MC domain(multi core domain),顶层的domain称为DIE domain。顶层的DIE domain覆盖了系统中所有的CPU,小核cluster的MC domain包括所有小核cluster中的cpu,同理,大核cluster的MC domain包括所有大核cluster中的cpu。
对于小核MC domain而言,其所属的sched group有四个,cpu0、1、2、3分别形成一个sched group,形成了MC domain的sched group环形链表。
不同CPU的MC domain的环形链表首元素(即sched domain中的groups成员指向的那个sched group)是不同的,对于cpu0的MC domain,其groups环形链表的顺序是0-1-2-3,对于cpu1的MC domain,其groups环形链表的顺序是1-2-3-0,以此类推。大核MC domain也是类似,这里不再赘述。
对于非base domain而言,其sched group有多个cpu,覆盖其child domain的所有cpu。例如上面图例中的DIE domain,它有两个child domain,分别是大核domain和小核domian,因此,DIE domain的groups环形链表有两个元素,分别是小核group和大核group。
不同CPU的DIE domain的环形链表首元素(即链表头)是不同的,对于cpu0的DIE domain,其groups环形链表的顺序是(0,1,2,3)--(4,5,6,7),对于cpu6的MC domain,其groups环形链表的顺序是(4,5,6,7)--(0,1,2,3),以此类推。
为了减少锁的竞争,每一个cpu都有自己的MC domain、DIE domain以及sched group,并且形成了sched domain之间的层级结构,sched group的环形链表结构。
2、负载均衡的基本过程
负载均衡不是一个全局CPU之间的均衡,实际上那样做也不现实,当系统的CPU数量较大的时候,很难一次性的完成所有CPU之间的均衡,这也是提出sched domain的原因之一。
当一个CPU上进行负载均衡的时候,我们总是从base domain开始(对于上面的例子,base domain就是MC domain),检查其所属sched group之间(即各个cpu之间)的负载均衡情况,如果有不均衡情况,那么会在该cpu所属cluster之间进行迁移,以便维护cluster内各个cpu core的任务负载均衡。有了各个CPU上的负载统计以及CPU的算力信息,我们很容易知道MC domain上的不均衡情况。
为了让算法更加简单,Linux内核的负载均衡算法只允许CPU拉任务,这样,MC domain的均衡大致需要下面几个步骤:
(1)找到MC domain中最繁忙的sched group;
(2)找到最繁忙sched group中最繁忙的CPU(对于MC domain而言,这一步不存在,毕竟其sched group只有一个cpu);
(3)从选中的那个繁忙的cpu上拉取任务,具体拉取多少的任务到本CPU runqueue上是和不均衡的程度相关,越是不均衡,拉取的任务越多。
完成MC domain均衡之后,继续沿着sched domain层级结构向上检查,进入DIE domain,在这个level的domain上,我们仍然检查其所属sched group之间(即各个cluster之间)的负载均衡情况,如果有不均衡的情况,那么会进行inter-cluster的任务迁移。基本方法和MC domain类似,只不过在计算均衡的时候,DIE domain不再考虑单个CPU的负载和算力,它考虑的是:
(1)该sched group的负载,即sched group中所有CPU负载之和;
(2)该sched group的算力,即sched group中所有CPU算力之和;
2、其他需要考虑的事项
之所以要进行负载均衡主要是为了系统整体的throughput,避免出现一核有难,七核围观的状况。然而,进行负载均衡本身需要额外的算力开销,为了降低开销,我们为不同level的sched domain定义了时间间隔,不能太密集的进行负载均衡。之外,我们还定义了不均衡的门限值,也就是说domain的group之间如果有较小的不均衡,我们也是可以允许的,超过了门限值才发起负载均衡的操作。很显然,越高level的sched domain其不均衡的threashhold越高,越高level的均衡会带来更大的性能开销。
在引入异构计算系统之后,任务在placement的时候可以有所选择。如果负载比较轻,或者该任务对延迟要求不高,我们可以放置在小核CPU执行,如果负载比较重或者该该任务和用户体验相关,那么我们倾向于让它在算力更高的CPU上执行。为了应对这种状况,内核引入了misfit task的概念。一旦任务被标记了misfit task,那么负载均衡算法要考虑及时的将该任务进行upmigration,从而让重载任务尽快完成,或者提升该任务的执行速度,从而提升用户体验。
除了性能,负载均衡也会带来功耗的收益。例如系统有4个CPU,共计8个进入执行态的任务。这些任务在4个CPU上的排布有两种选择:
(1)全部放到一个CPU上;
(2)每个CPU runqueue挂2个任务。
负载均衡算法会让任务均布,从而带来功耗的收益。虽然方案一中有三个CPU是处于idle状态的,但是那个繁忙CPU运行在更高的频率上。而方案二中,由于任务均布,CPU处于较低的频率运行,功耗会比方案一更低。
四、负载均衡场景分析
1、整体的场景描述
在linux内核中,为了让任务均衡的分布在系统的所有CPU上,我们主要考虑下面三个场景:
(1)负载均衡(load balance)。通过搬移cpu runqueue上的任务,让各个CPU上的负载匹配CPU算力。
(2)任务放置(task placement)。当阻塞的任务被唤醒的时候,确定该任务应该放置在那个CPU上执行。
(3)主动均衡(active upmigration)。当一个低算力CPU的runqueue中出现misfit task的时候,如果该任务持续执行,那么负载均衡无能为力,因为它只负责迁移runnable状态的任务。这种场景下,active upmigration可以把当前正在运行的misfit task向上迁移到算力更高的CPU上去。
2、Task placement
任务放置主要发生在:
(1)唤醒一个新fork的线程;
(2)Exec一个线程的时候;
(3)唤醒一个阻塞的进程。
在上面的三个场景中都会调用select_task_rq来为task选择一个适合的CPU core。
3、Load balance
Load balance主要有三种:
(1)在tick中触发load balance。我们称之tick load balance或者periodic load balance。具体的代码执行路径是:

(2)调度器在pick next的时候,当前cfs runque中没有runnable,只能执行idle线程,让CPU进入idle状态。我们称之new idle load balance。具体的代码执行路径是:
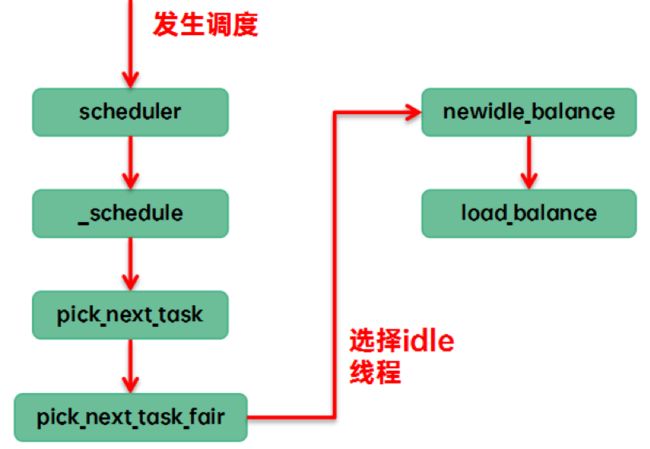
(3)其他的cpu已经进入idle,本CPU任务太重,需要通过ipi将其idle的cpu唤醒来进行负载均衡。我们称之idle load banlance,具体的代码执行路径是:

如果没有dynamic tick特性,那么其实不需要进行idle load balance,因为tick会唤醒处于idle的cpu,从而周期性tick就可以覆盖这个场景。
4、Active upmigration
主动迁移是Load balance的一种特殊场景。在负载均衡中,只要运用适当的同步机制(持有一个或者多个rq lock),runnable的任务可以在各个CPU runqueue之间移动,然而running的任务是例外,它不挂在CPU runqueue中,load balance无法覆盖。为了能够迁移running状态的任务,内核提供了Active upmigration的方法(利用stop machine调度类)。
参考文献
1. 内核源代码
2. linux-5.4.28\Documentation\scheduler\*

添加极客助手微信,加入技术交流群


长按,扫码,关注公众号