深度学习入门之3--神经网络学习
目录
1相关术语
2损失函数
2.1定义
2.2均方误差
2.3交叉熵误差
2.4批处理数据
2.5为何需要损失函数
3数值微分
3.1导数
3.2偏导数
4梯度
5案例实现
5.1dataset
5.2common
5.2.1functions.py:
5.2.2gradient.py:
5.3ch04
5.3.1two_layer_net.py
5.3.2train_neuralnet.py
该文章是对《深度学习入门 基于Python的理论与实现》的总结,作者是[日]斋藤康毅
1相关术语
在神经网络中,数据是相当重要的,提取数据特征也是相当重要
“特征量”是指可以从输入数据(输入图像)中准确地提取本质数据(重要的数据)的转换器。
神经网络与机器学习等的比较如下图:
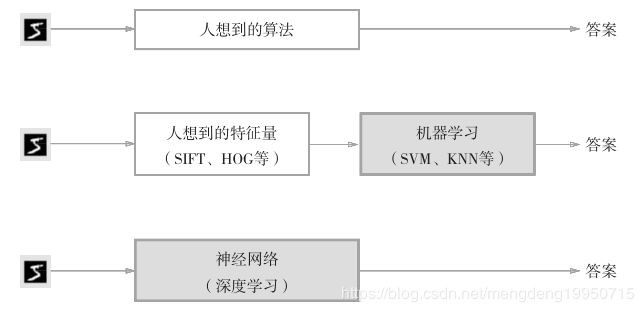
机器学习中,一般将数据分为训练数据和测试数据两部分来进行学习和实验等
泛化能力是指处理未被观察过的数据(不包含在训练数据中的数据)的能力。获得泛化能力是机器学习的最终目标。
只对某个数据集过度拟合的状态称为过拟合(over fitting)
2损失函数
2.1定义
损失函数是表示神经网络性能的“恶劣程度”的指标,即当前的神经网络对监督数据在多大程度上不拟合,在多大程度上不一致。以“性能的恶劣程度”为指标可能会使人感到不太自然,但是如果给损失函数乘上一个负值,就可以解释为“在多大程度上不坏”,即“性能有多好”。
2.2均方误差
均方误差格式如下:
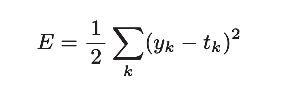
【注】:y k 是表示神经网络的输出,t k 表示监督数据,k表示数据的维数
代码实现如下:
import numpy as np
def mean_squared_error(y, t):
return 0.5*np.sum((y-t)**2)
if __name__ == "__main__":
# 使用数字识别来理解y为预测的数据(用概率表示),t为真实数据
# 设2为正确解
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
# 2的概率最高,且为0.6
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
# 7的概率最高为0.6
y1 = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]
# 均方误差
# r1 = mean_squared_error(np.array(y), np.array(t))
# r2 = mean_squared_error(np.array(y1), np.array(t))
# print(r1) # 0.09750000000000003
# print(r2) # 0.5975
# 我们发现第一个例子的损失函数的值更小,和监督数据之间的
# 误差较小。也就是说,均方误差显示第一个例子的输出结果与监督数据更加吻合。
2.3交叉熵误差
交叉熵误差损失函数格式如下: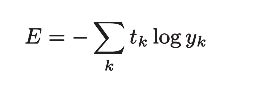
【注】:log表示以e为底数的自然对数(log e )。y k 是神经网络的输出,t k 是正确解标签。
代码实现如下:
import numpy as np
#加上了一个微小值 delta 。这是因为,当出现 np.log(0) 时, np.log(0) 会变为负无限大的-inf
#这样一来就会导致后续计算无法进行。作为保护性对策,添加一个微小值可以防止负无限大的发生。
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta))
if __name__ == "__main__":
# 设2为正确解
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
# 2的概率最高,且为0.6
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
# 7的概率最高为0.6
y1 = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]
# 交叉熵误差
r1 = cross_entropy_error(np.array(y), np.array(t))
r2 = cross_entropy_error(np.array(y1), np.array(t))
print(r1) # 0.510825457099338
print(r2) # 2.302584092994546
2.4批处理数据
前面介绍的损失函数的例子中考虑的都是针对单个数据的损失函数。如果要求所有训练数据的损失函数的总和,以交叉熵误差为例,可以写成下面的式子:
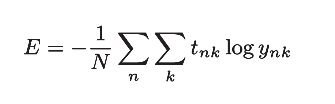
【注】:假设数据有N个,t nk 表示第n个数据的第k个元素的值(y nk 是神经网络的输出,t nk 是监督数据)。
批处理数据,那么如何随机的一次读取多条数据呢?可以使用NumPy的 np.random.choice() ,比如,np.random.choice(60000, 10) 会从0到59999之间随机选择10个数字。
例如:
import sys,os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
# print(x_train.shape) # (60000, 784)
# print(t_train.shape) # (60000, 10)
# 随机抽取10笔数据
train_size = x_train.shape[0] # 60000
batch_size = 10
# 从0到59999之间随机选择10个数字
batch_mask = np.random.choice(train_size, batch_size) # 从指定的数字中随机选择想要的数字
# print(batch_mask) # [40011 45133 49757 27590 11182 32214 23597 45193 56422 33356]
x_batch = x_train[batch_mask] # (10, 784)
t_batch = t_train[batch_mask] # (10, 10)
下面实现一个可以同时处理单个数据和批量数据(数据作为batch集中输入)两种情况的函数。
代码实现mini_batch交叉熵误差:
def batch_cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(t * np.log(y + 1e-7))/batch_size【注】: y 是神经网络的输出, t 是监督数据。 y 的维度为1时,即求单个数据的交叉熵误差时,需要改变数据的形状。并且,当输入为mini-batch时,要用batch的个数进行正规化,计算单个数据的平均交叉熵误差。
当监督数据是标签形式(非one-hot表示,而是像“2”“7”这样的标签)时,交叉熵误差可通过如下代码实现。
def batch_cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7))/batch_size【注】:对于 np.log( y[np.arange(batch_size), t] ) 。 np.arange(batch_size) 会生成一个从0到 batch_size-1 的数组。比如当 batch_size 为5时, np.arange(batch_size) 会生成一个NumPy 数组 [0, 1, 2, 3, 4] 。因为t 中标签是以 [2, 7, 0, 9, 4] 的形式存储的,所以 y[np.arange(batch_size),t] 能抽出各个数据的正确解标签对应的神经网络的输出(在这个例子中,y[np.arange(batch_size), t] 会生成 NumPy数组 [y[0,2], y[1,7], y[2,0],y[3,9], y[4,4]] )。
2.5为何需要损失函数
1、在神经网络的学习中,寻找最优参数(权重和偏置)时,要寻找使损失函数的值尽可能小的参数。为了找到使损失函数的值尽可能小的地方,需要计算参数的导数(确切地讲是梯度),然后以这个导数为指引,逐步更新参数的值。
2、如果导数的值为负,通过使该权重参数向正方向改变,可以减小损失函数的值;反过来,如果导数的值为正,则通过使该权重参数向负方向改变,可以减小损失函数的值。不过,当导数的值为0时,无论权重参数向哪个方向变化,损失函数的值都不会改变,此时该权重参数的更新会停在此处。
3数值微分
3.1导数
导数就是表示某个瞬间的变化量,(增量比值的极限)其格式如下:
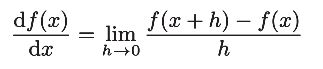
【注】:等号左侧表示的是函数值的导数,右侧表示函数值f(x)相对于自变量x变化的程度(用极限来进行表示)
舍入误差:是指因省略小数的精细部分的数值(比如,小数点第8位以后的数值)而造成最终的计算结果上的误差。
例如:
print(np.float32(1e-50)) # 10^-50 = 0.0【注】:上述的h的值需要设置的较为合理,否则会带来很大的误差,可以将1e-50改为1e-4
除了修改h的值之外,第二个需要改进的地方与函数 f 的差分有关。虽然上述实现中计算了函数 f 在 x+h 和 x 之间的差分,但是必须注意到,这个计算从一开始就有误差。真的导数”对应函数在x处的斜率(称为切线),但上述实现中计算的导数对应的是(x + h)和x之间的斜率。
为了减小这个误差,我们可以计算函数f在(x + h)和(x − h)之间的差分。因为这种计算方法以x为中心,计算它左右两边的差分,所以也称为中心差分(而(x + h)和x之间的差分称为前向差分)。
导数代码实现如下:
import numpy as np
# 不好的实现示例--前向差分
def forward_numerical_diff(f, x):
h = 10e-50
# h = 1e-4 # 0.0001
return (f(x+h) - f(x))/h
# 中心差分
def center_numerical_diff(f, x):
h = 1e-4 # 0.0001
return (f(x+h) - f(x-h))/(2*h)
def fun(x):
return 0.01*x**2 + 0.1*x
def fun2(x):
# return x[0]**2 + x[1]**2
return np.sum(x**2)
if __name__ == "__main__":
# x=5处的导数的近似值
z = center_numerical_diff(fun, 5) # 0.1999999999990898
# x=10处的导数的近似值
z1 = center_numerical_diff(fun, 10) # 0.2999999999986347
3.2偏导数
当一个函数中存在多个参数时,则求的是函数的偏导数。
例如:
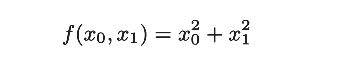
当需要求x0的偏导数的时候是,将x1看作是常数。求x1时也要将x0看作是常数。
其它的则和前面求导数的方法一样。
4梯度
机器学习的主要任务是在学习时寻找最优参数,同样地,神经网络也必须在学习时找到最优参数(权重和偏置)。这里所说的最优参数是指损失函数取最小值时的参数。梯度表示的是各点处的函数值减小最多的方向
梯度法的格式如下 :
学习率需要事先确定为某个值,比如0.01或0.001。上式是表示更新一次的式子,这个步骤会反复执行。也就是说,每一步都按上式更新变量的值,通过反复执行此步骤,逐渐减小函数值。
【注】:η表示更新量,在神经网络的学习中,称为学习率(learningrate)。
求梯度的代码实现如下:
import numpy as np
# 定义一个函数
def fun2(x):
return x[0]**2 + x[1]**2
# 求偏导数
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x) # 生成和x相同的数组
for idx in range(x.size):
tmp_val = x[idx]
# f(x+h)的计算
x[idx] = tmp_val + h
fxh1 = f(x) # 进行计算的时候,x != [3, 4] ,而是[3+h, 4]
# f(x-h)的计算
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2)/(2*h)
x[idx] = tmp_val # 还原值
return grad
# 梯度下降法实现
# f:进行优化的函数,init_x:初始值,lr:学习率,step_num:梯度法的重复次数
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x) # 求函数的梯度
x -= lr * grad
return x
if __name__ == "__main__":
x, y = numerical_gradient(fun2, np.array([3.0, 4.0]))
# print(x) # 6.00000000000378
# print(y) # 7.999999999999119
# 设定初值
init_x = np.array([-3.0, 4.0])
# m, n = gradient_descent(fun2, init_x=init_x, lr=0.1, step_num=100)
# print(m) # -6.111107928998789e-10
# print(n) # 8.148143905314271e-10
# 学习率过大
# m, n = gradient_descent(fun2, init_x=init_x, lr=10, step_num=100)
# print(m) # -25898374737328.363
# print(n) # -1295248616896.5398
# 学习率过小
m, n = gradient_descent(fun2, init_x=init_x, lr=1e-4, step_num=100)
print(m) # -2.9405901379497053
print(n) # 3.920786850599603
'''
学习率过大的话,会发散成一个很大的值;反过来,学习率过小的话,基本上没怎么更新就结束了。
'''
5案例实现
实现该案例所需文件:
5.1dataset
可在上一章查找
5.2common
5.2.1functions.py:
该文件起着激活函数、损失函数的作用
# coding: utf-8
import numpy as np
def identity_function(x):
return x
def step_function(x):
return np.array(x > 0, dtype=np.int)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_grad(x):
return (1.0 - sigmoid(x)) * sigmoid(x)
def relu(x):
return np.maximum(0, x)
def relu_grad(x):
grad = np.zeros(x)
grad[x>=0] = 1
return grad
def softmax(x):
if x.ndim == 2:
x = x.T
# axis:默认为列向(也即 axis=0),axis = 1 时为行方向的最值;防止溢出
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) #
return np.exp(x) / np.sum(np.exp(x))
def sum_squared_error(y, t):
return 0.5 * np.sum((y-t)**2)
def cross_entropy_error(y, t):
# 求单个数据的交叉熵误差时,需要改变数据的形状,返回数组的维度,例如:一维,二维
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
if t.size == y.size:
# argmax返回的是最大数的索引.argmax有一个参数axis,默认是0,表示第几维的最大值
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
def softmax_loss(X, t):
y = softmax(X)
return cross_entropy_error(y, t)
5.2.2gradient.py:
该文件起着求导数,梯度
# coding: utf-8
import numpy as np
# 求一维偏导数
def _numerical_gradient_1d(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
for idx in range(x.size):
tmp_val = x[idx]
x[idx] = float(tmp_val) + h
fxh1 = f(x) # f(x+h)
x[idx] = tmp_val - h
fxh2 = f(x) # f(x-h)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 还原
return grad
# 求二维偏导数
def numerical_gradient_2d(f, X):
if X.ndim == 1:
return _numerical_gradient_1d(f, X)
else:
grad = np.zeros_like(X)
for idx, x in enumerate(X):
grad[idx] = _numerical_gradient_1d(f, x)
return grad
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
# flags:使用外部循环,multi-index:每次迭代可以跟踪一种索引类型
# nditer 对象有另一个可选参数 op_flags。 默认情况下,nditer 将视待迭代遍历的数组为只读对象(read-only),
# 为了在遍历数组的同时,实现对数组元素值得修改,必须指定 read-write 或者 write-only 的模式。
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite']) # 迭代
while not it.finished:
idx = it.multi_index
tmp_val = x[idx]
x[idx] = tmp_val + h
fxh1 = f(x) # f(x+h)
x[idx] = tmp_val - h
fxh2 = f(x) # f(x-h)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 还原
it.iternext()
return grad
5.3ch04
5.3.1two_layer_net.py
该文件创建一个两层网路
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 加载路径
from common.functions import *
from common.gradient import numerical_gradient
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
# 网路初始化
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
def predict(self, x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
return y
# x:预测值,t:真实值
def loss(self, x, t):
y = self.predict(x)
return cross_entropy_error(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
grads = {}
batch_num = x.shape[0]
# forward
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
# backward
dy = (y - t) / batch_num
grads['W2'] = np.dot(z1.T, dy)
grads['b2'] = np.sum(dy, axis=0)
dz1 = np.dot(dy, W2.T)
da1 = sigmoid_grad(a1) * dz1
grads['W1'] = np.dot(x.T, da1)
grads['b1'] = np.sum(da1, axis=0)
return grads
5.3.2train_neuralnet.py
使用神经网络进行训练
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 加载路径
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from ch04.two_layer_net import TwoLayerNet
# 读取数据集
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
iters_num = 10000 # 迭代次数10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 梯度计算
# grad = network.numerical_gradient(x_batch, t_batch)
grad = network.gradient(x_batch, t_batch)
# 参数更新
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))
# 绘图
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, label='train acc')
plt.plot(x, test_acc_list, label='test acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
5.4得到最终结果
运行结果如下:
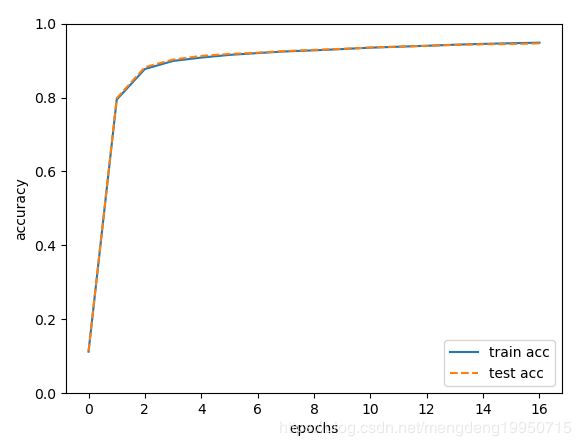
精度结果如图:
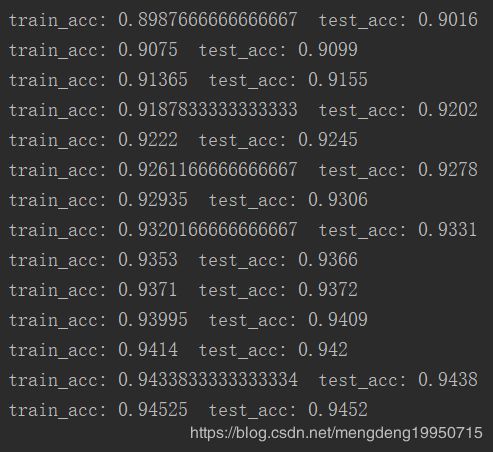
由上图可知,通过前向传播训练集的精度为0.94525, 测试集的精度为0.9452.