mahout推荐介绍-3
转载自:http://hi.baidu.com/liujiekkk123/blog/item/8334240938ed04386b60fbb3.html
基于 Apache Mahout 实现高效的协同过滤推荐
Apache Mahout 是 Apache Software Foundation (ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序,并且,在 Mahout 的最近版本中还加入了对 Apache Hadoop 的支持,使这些算法可以更高效的运行在云计算环境中。
关于 Apache Mahout 的安装和配置请参考《基于 Apache Mahout 构建社会化推荐引擎》,它是笔者 09 年发表的一篇关于基于 Mahout 实现推荐引擎的 developerWorks 文章,其中详细介绍了 Mahout 的安装步骤,并给出一个简单的电影推荐引擎的例子。
Apache Mahout 中提供的一个协同过滤算法的高效实现,它是一个基于 Java 实现的可扩展的,高效的推荐引擎。图 4 给出了 Apache Mahout 中协同过滤推荐实现的组件图,下面我们逐步深入介绍各个部分。
图 4.组件图
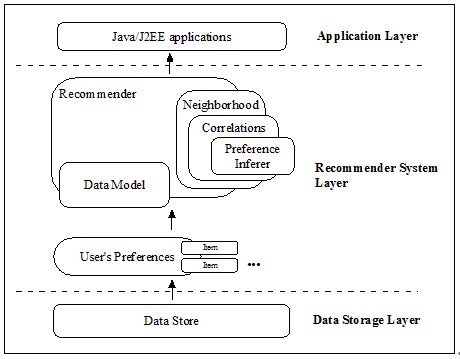
数据表示:Data Model
Preference
基于协同过滤的推荐引擎的输入是用户的历史偏好信息,在 Mahout 里它被建模为 Preference(接口),一个 Preference 就是一个简单的三元组 < 用户 ID, 物品 ID, 用户偏好 >,它的实现类是 GenericPreference,可以通过以下语句创建一个 GenericPreference。
GenericPreference preference = new GenericPreference(123, 456, 3.0f);
这其中, 123 是用户 ID,long 型;456 是物品 ID,long 型;3.0f 是用户偏好,float 型。从这个例子我们可以看出,单单一个 GenericPreference 的数据就占用 20 bytes,所以你会发现如果只简单实用数组 Array 加载用户偏好数据,必然占用大量的内存,Mahout 在这方面做了一些优化,它创建了 PreferenceArray(接口)保存一组用户偏好数据,为了优化性能,Mahout 给出了两个实现类,GenericUserPreferenceArray 和 GenericItemPreferenceArray,分别按照用户和物品本身对用户偏好进行组装,这样就可以压缩用户 ID 或者物品 ID 的空间。下面清单 1 的代码以 GenericUserPreferenceArray 为例,展示了如何创建和使用一个 PreferenceArray。
清单 1. 创建和使用 PreferenceArray
PreferenceArray userPref = new GenericUserPreferenceArray(2); //size = 2 userPref.setUserID(0, 1L); userPref.setItemID(0, 101L); //<1L, 101L, 2.0f> userPref.setValue(0, 2.0f); userPref.setItemID(1, 102L); //<1L, 102L, 4.0f> userPref.setValue(1, 4.0f); Preference pref = userPref.get(1); //<1L, 102L, 4.0f> |
为了提高性能 Mahout 还构建了自己的 HashMap 和 Set:FastByIDMap 和 FastIDSet,有兴趣的朋友可以参考 Mahout 官方说明。
DataModel
Mahout 的推荐引擎实际接受的输入是 DataModel,它是对用户偏好数据的压缩表示,通过创建内存版 DataModel 的语句我们可以看出:
DataModel model = new GenericDataModel(FastByIDMap
他保存在一个按照用户 ID 或者物品 ID 进行散列的 PreferenceArray,而 PreferenceArray 中对应保存着这个用户 ID 或者物品 ID 的所有用户偏好信息。
DataModel 是用户喜好信息的抽象接口,它的具体实现支持从任意类型的数据源抽取用户喜好信息,具体实现包括内存版的 GenericDataModel,支持文件读取的 FileDataModel 和支持数据库读取的 JDBCDataModel,下面我们看看如何创建各种 DataModel。
清单 2. 创建各种 DataModel
//In-memory DataModel - GenericDataModel FastByIDMap |
支持文件读取的 FileDataModel,Mahout 没有对文件的格式做过多的要求,只要文件的内容满足以下格式:
- 每一行包括用户 ID, 物品 ID, 用户偏好
- 逗号隔开或者 Tab 隔开
- *.zip 和 *.gz 文件会自动解压缩(Mahout 建议在数据量过大时采用压缩的数据存储)
支持数据库读取的 JDBCDataModel,Mahout 提供一个默认的 MySQL 的支持,它对用户偏好数据的存放有以下简单的要求:
- 用户 ID 列需要是 BIGINT 而且非空
- 物品 ID 列需要是 BIGINT 而且非空
- 用户偏好列需要是 FLOAT
建议在用户 ID 和物品 ID 上建索引。
实现推荐:Recommender
介绍完数据表示模型,下面介绍 Mahout 提供的协同过滤的推荐策略,这里我们选择其中最经典的三种,User CF, Item CF 和 Slope One。
User CF
前面已经详细介绍了 User CF 的原理,这里我们着重看怎么基于 Mahout 实现 User CF 的推荐策略,我们还是从一个例子入手:
清单 3. 基于 Mahout 实现 User CF
DataModel model = new FileDataModel(new File("preferences.dat"));
UserSimilarity similarity = new PearsonCorrelationSimilarity(model);
UserNeighborhood neighborhood = new NearestNUserNeighborhood(100, similarity, model);
Recommender recommender = new GenericUserBasedRecommender(model,
neighborhood, similarity);
|
- 从文件建立 DataModel,我们采用前面介绍的 FileDataModel,这里假设用户的喜好信息存放在 preferences.dat 文件中。
- 基于用户偏好数据计算用户的相似度,清单中采用的是 PearsonCorrelationSimilarity,前面章节曾详细介绍了各种计算相似度的方法,Mahout 中提供了基本的相似度的计算,它们都 UserSimilarity 这个接口,实现用户相似度的计算,包括下面这些常用的:
- PearsonCorrelationSimilarity:基于皮尔逊相关系数计算相似度
- EuclideanDistanceSimilarity:基于欧几里德距离计算相似度
- TanimotoCoefficientSimilarity:基于 Tanimoto 系数计算相似度
- UncerteredCosineSimilarity:计算 Cosine 相似度
ItemSimilarity 也是类似的:
- 根据建立的相似度计算方法,找到邻居用户。这里找邻居用户的方法根据前面我们介绍的,也包括两种:“固定数量的邻居”和“相似度门槛邻居”计算方法,Mahout 提供对应的实现:
- NearestNUserNeighborhood:对每个用户取固定数量 N 的最近邻居
- ThresholdUserNeighborhood:对每个用户基于一定的限制,取落在相似度门限内的所有用户为邻居。
- 基于 DataModel,UserNeighborhood 和 UserSimilarity 构建 GenericUserBasedRecommender,实现 User CF 推荐策略。
Item CF
了解了 User CF,Mahout Item CF 的实现与 User CF 类似,是基于 ItemSimilarity,下面我们看实现的代码例子,它比 User CF 更简单,因为 Item CF 中并不需要引入邻居的概念:
清单 4. 基于 Mahout 实现 Item CF
DataModel model = new FileDataModel(new File("preferences.dat"));
ItemSimilarity similarity = new PearsonCorrelationSimilarity(model);
Recommender recommender = new GenericItemBasedRecommender(model, similarity);
|
Slope One
如前面介绍的,User CF 和 Item CF 是最常用最容易理解的两种 CF 的推荐策略,但在大数据量时,它们的计算量会很大,从而导致推荐效率较差。因此 Mahout 还提供了一种更加轻量级的 CF 推荐策略:Slope One。
Slope One 是有 Daniel Lemire 和 Anna Maclachlan 在 2005 年提出的一种对基于评分的协同过滤推荐引擎的改进方法,下面简单介绍一下它的基本思想。
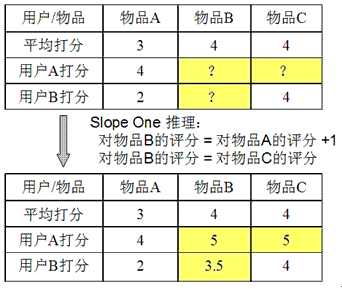
图 5 给出了例子,假设系统对于物品 A,物品 B 和物品 C 的平均评分分别是 3,4 和 4。基于 Slope One 的方法会得到以下规律:
- 用户对物品 B 的评分 = 用户对物品 A 的评分 + 1
- 用户对物品 B 的评分 = 用户对物品 C 的评分
基于以上的规律,我们可以对用户 A 和用户 B 的打分进行预测:
- 对用户 A,他给物品 A 打分 4,那么我们可以推测他对物品 B 的评分是 5,对物品 C 的打分也是 5。
- 对用户 B,他给物品 A 打分 2,给物品 C 打分 4,根据第一条规律,我们可以推断他对物品 B 的评分是 3;而根据第二条规律,推断出评分是 4。当出现冲突时,我们可以对各种规则得到的推断进行就平均,所以给出的推断是 3.5。
这就是 Slope One 推荐的基本原理,它将用户的评分之间的关系看作简单的线性关系:
Y = mX + b;
当 m = 1 时就是 Slope One,也就是我们刚刚展示的例子。
图 5.Slope One 推荐策略示例
Slope One 的核心优势是在大规模的数据上,它依然能保证良好的计算速度和推荐效果。Mahout 提供了 Slope One 推荐方法的基本实现,实现代码很简单,参考清单 5.
清单 5. 基于 Mahout 实现 Slope One
//In-Memory Recommender DiffStorage diffStorage = new MemoryDiffStorage(model, Weighting.UNWEIGHTED, false, Long.MAX_VALUE)); Recommender recommender = new SlopeOneRecommender(model, Weighting.UNWEIGHTED, Weighting.UNWEIGHTED, diffStorage); //Database-based Recommender AbstractJDBCDataModel model = new MySQLJDBCDataModel(); DiffStorage diffStorage = new MySQLJDBCDiffStorage(model); Recommender recommender = new SlopeOneRecommender(model, Weighting.WEIGHTED, Weighting.WEIGHTED, diffStorage); |
1. 根据 Data Model 创建数据之间线性关系的模型 DiffStorage。
2. 基于 Data Model 和 DiffStorage 创建 SlopeOneRecommender,实现 Slope One 推荐策略。