决策树及MATLAB函数使用
基本流程
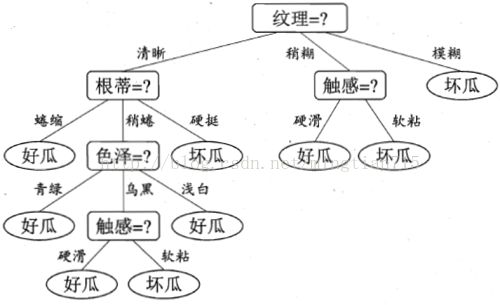
决策树是一种常见的机器学习方法,以二分任务为例,我们希望从给定训练数据集学得一个模型用以对新示例进行分类,顾名思义,这个分类的任务是基于树的结构来决策的,这恰是人类在面临决策问题时一种很自然的处理机制。例如下图为对西瓜分类好坏瓜的决策树。

一般一棵决策树包含一个根结点,若干内部结点和若干个叶结点,如下是决策树基本学习算法。

决策树的生成是一个递归的过程,在决策树算法中,有三种情况会导致递归返回:
(1)当前结点包含的样本全属于同一类别,无需划分。例如当前结点所有数据都是好瓜,自然不用再划分。
(2)当前属性集为空,或是所有样本在所有属性上取值相同,无法划分。例如当前样本有好瓜和坏瓜,但其颜色是相同的,自然无法在颜色属性进行划分。此时把颜色定为叶结点,类别设为包含样本数量多的类别。
(3)当前结点包含的样本集合为空,不能划分。例如对颜色(青绿、乌黑、浅白)划分,但是剩余样本中不含青绿色西瓜,因此在青绿色属性上不能继续划分。此时把青绿色定为叶结点,类别设为其父结点(颜色属性)中所含样本最多的类别。
划分选择
决策树的划分过程还是比较简单的,原则是随着划分过程不断进行,希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度”越来越高。
信息增益
采用信息熵来描述纯度,很显然信息熵越低(信息更加确定),纯度越高。

用“信息增益”来描述对某一属性进行划分所获得纯度提升的多少:

例如对于西瓜问题,计算出的各属性信息增益如下:
Gain(D,颜色)=0.109,Gain(D,根蒂)=0.143,Gain(D,敲声)=0.141
Gain(D,纹理)=0.381,Gain(D,脐部)=0.289,Gain(D,触感)=0.006。
因此首先对纹理进行划分,
然后,决策树算法将对每个分支结点做进一步划分,最终得到如下决策树。
基尼系数


基尼系数越小,说明纯度越高(pk均相等时,达到基尼系数最小值)。因此划分时选择基尼系数最小的属性。
剪枝处理
剪枝是决策树算法对付“过拟合”的主要手段,分支过多,对训练数据的拟合很完美,但对测试数据则不一定,且效率较低。因此可主动去掉一些分支来降低过拟合的风险。
剪枝处理包括预剪枝和后剪枝,分别对应着在决策树生成过程中/决策叔生成完毕后进行剪枝处理。
对某一结点是否进行剪枝处理的依据是划分前后验证集精度是否提高。
例如样本中4个好瓜,3个坏瓜,若不按某一属性(脐部)划分,则由于好瓜数量多,将此结点标记为好瓜,验证精度为4/7。若按脐部划分(凹陷:好瓜、稍凹:好瓜、平坦:坏瓜)后,求得验证精度提高(大于4/7),则认为此处划分合理,不需要剪枝条,反之则剪。
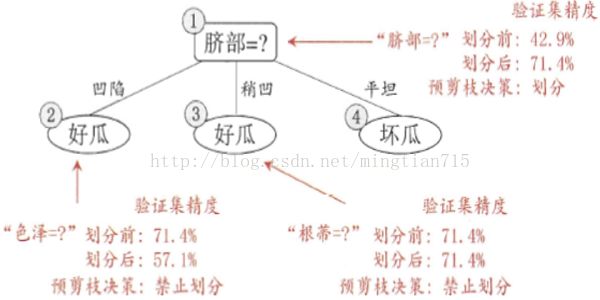
预剪枝使得决策树很多分枝都没有“展开”,不仅降低了过拟合风险,还显著减少了决策树训练时间和开销。但另一方面,有些分支当前划分虽不能提升泛化性能,甚至降低泛化性能,但在其基础上的后续划分可能导致性能显著提高,给决策树带来欠拟合风险。后剪枝通常比预剪枝保留更多分支,欠拟合风险小,泛化性能优于预剪枝决策树,但其时间开销要大得多。
连续值处理
连续值处理方法很简单,在已有属性的取值范围内定义多个划分点。

寻找最优划分点,同样是基于纯度。再将样本根据此点一分为2,即完成划分。

此外,还可能出现样本中某一
属性值缺失
的情况,需要解决两个个问题:
(1)如何在属性值缺失的情况下进行划分属性选择
引入权值ro,代表无缺失数据比重,例如若样本对于某一属性值有40%数据丢失,则ro=0.6,利用无缺失属性值数据计算出的信息增益后需要乘上ro,作为真实信息增益。
(2)若样本在该属性上的值缺失,如何划分该样本
将样本同时投入所有分支,但在不同分支权重不同,权重由不同分支中的数据量决定
多变量决策树
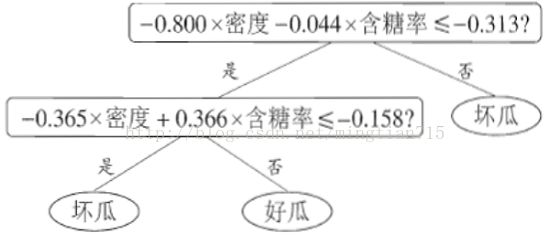
之前所述决策树划分条件都是单一变量,使用多变量作为划分条件可以使得决策树变得更复杂,划分更加精确,但是边界寻找比较困难。如下图是一个多变量决策树。

MATLAB函数使用
1.创建分类决策树或回归决策树
load carsmall % contains Horsepower, Weight, MPG
X = [Horsepower Weight];
rtree = fitrtree(X,MPG);% create regression tree
load fisheriris % load the sample data
ctree = fitctree(meas,species); % create classification tree
view(ctree) % text description
顺便提一下,MATLAB中默认的划分方法是基于基尼系数的。
2.用训练好的决策树做数据分类
load ionosphere % contains X and Y variables
ctree = fitctree(X,Y);
Ynew = predict(ctree,mean(X))
3.检验决策树性能并修正
最简单的性能检测就是生成一颗决策树后,输入所有数据样本,进行误差检验。
这种检测方法输入数据样本中包含了训练数据,因此得到结果比实际结果要好的多,泛化能力差,过于乐观。
load fisheriris
ctree = fitctree(meas,species);
resuberror = resubLoss(ctree)
因此常常采用交叉检验法,因为交叉检验法使用的测试数据不同于训练数据,且是一个多次平均的结果,因此其对性能的估计比较准确。并根据交叉检验法进行决策树的修改,使得其性能表现更好。
(1)限定每个叶节点包含的最少数据量
如果不进行限定,每个叶节点包含的最小数据量为1,过多的叶子结点必然造成决策树泛化能力的降低,因此应该求得一个Leaf(min),从而使得计算出交叉误差最小。
leafs = logspace(1,2,10);
rng('default')
N = numel(leafs);
err = zeros(N,1);
for n=1:N
t = fitctree(X,Y,'CrossVal','On',...
'MinLeaf',leafs(n));
err(n) = kfoldLoss(t);
end
plot(leafs,err);
xlabel('Min Leaf Size');
ylabel('cross-validated error');
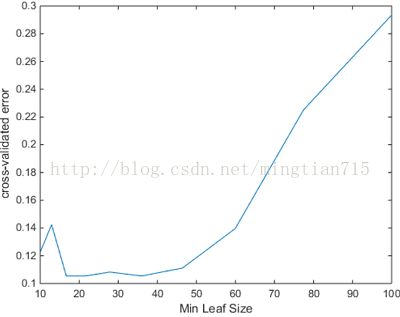
得到最小的叶子尺寸,再进行决策树生成
OptimalTree = fitctree(X,Y,'minleaf',40);
(2)剪枝
与上面类似,计算不同剪枝下的交叉检测误差,选择最小误差处剪枝。
[~,~,~,bestlevel] = cvLoss(tree,...
'SubTrees','All','TreeSize','min')
tree = prune(tree,'Level',bestlevel);