基于caffe的模型压缩
训练出来的模型有很多参数,比如AlexNet有高达6千万个,体积有232MB之大,具体计算方法参见深度学习 计算模型中每层参数的个数和FLOPs,对于部署到移动端来说显然是不合适的,那么怎么样才能减少模型的体积呢?怎么样才能加速呢?
裁剪、量化和蒸馏是常用的三种方式,本文将介绍其中的前两种方法.
1.裁剪
看下在Mnist数据集训练精度达99%的LeNet网络的滤波器权重, conv1第一个和fc2第一个,大部分都接近0.
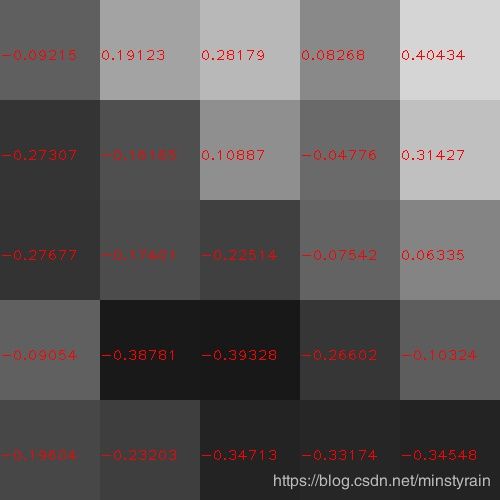

再来看下压缩后的对比:


大部分已经截断为0.
分析下LeNet的结构可以发现conv2占据了绝大部分的计算量,fc1占用了大部分参数量,因此对其优化收益最佳
layer name Filter Shape Output Size Params Flops Ratio
conv1 (20, 1, 5, 5) (64, 20, 24, 24) 500 288000 12.56
conv2 (50, 20, 5, 5) (64, 50, 8, 8) 25000 1600000 69.778
ip1 (500, 800) (64, 500) 400000 400000 17.444
ip2 (10, 500) (64, 10) 5000 5000 0.218
Layers num: 4
Total number of parameters: 430500
Total number of FLOPs: 2293000DeepCompression-caffe精简后的日志:
stage1
I1102 17:28:31.986773 29076 cmp_conv_layer.cpp:47] CONV THR: 0.115747 0.33
I1102 17:28:31.986806 29076 cmp_conv_layer.cpp:65] sparsity: 0.33
I1102 17:28:31.988147 29076 cmp_conv_layer.cpp:65] sparsity: 0
I1102 17:28:32.014879 29076 cmp_inner_product_layer.cpp:62] sparsity: 0
I1102 17:28:32.015149 29076 cmp_inner_product_layer.cpp:62] sparsity: 0
I0527 11:15:41.981787 7460 solver.cpp:317] Iteration 500, loss = 0.00337758
I0527 11:15:41.981802 7460 solver.cpp:337] Iteration 500, Testing net (#0)
I0527 11:15:42.053822 7460 solver.cpp:404] Test net output #0: accuracy = 0.9914
I0527 11:15:42.053841 7460 solver.cpp:404] Test net output #1: loss = 0.0273776 (* 1 = 0.0273776 loss)
stage2
I1102 17:28:33.807425 29226 cmp_conv_layer.cpp:47] CONV THR: 0 0.33
I1102 17:28:33.807464 29226 cmp_conv_layer.cpp:65] sparsity: 0.33
I1102 17:28:33.808884 29226 cmp_conv_layer.cpp:47] CONV THR: 0.0529969 0.8
I1102 17:28:33.808957 29226 cmp_conv_layer.cpp:65] sparsity: 0.8
I1102 17:28:33.834861 29226 cmp_inner_product_layer.cpp:62] sparsity: 0
I0527 11:15:45.206871 7483 solver.cpp:317] Iteration 1000, loss = 0.00963775
I0527 11:15:45.206888 7483 solver.cpp:337] Iteration 1000, Testing net (#0)
I0527 11:15:45.279081 7483 solver.cpp:404] Test net output #0: accuracy = 0.9917
I0527 11:15:45.279103 7483 solver.cpp:404] Test net output #1: loss = 0.0283742 (* 1 = 0.0283742 loss)
stage3
I1102 17:28:36.274431 29278 cmp_conv_layer.cpp:47] CONV THR: 0 0.33
I1102 17:28:36.274452 29278 cmp_conv_layer.cpp:65] sparsity: 0.33
I1102 17:28:36.274977 29278 cmp_conv_layer.cpp:47] CONV THR: 0 0.8
I1102 17:28:36.275055 29278 cmp_conv_layer.cpp:65] sparsity: 0.8
I1102 17:28:36.302774 29278 cmp_inner_product_layer.cpp:46] THR: 0.0397202
I1102 17:28:36.303934 29278 cmp_inner_product_layer.cpp:62] sparsity: 0.9
I1102 17:28:36.304250 29278 cmp_inner_product_layer.cpp:62] sparsity: 0
I0527 11:16:12.605298 7509 solver.cpp:317] Iteration 10500, loss = 0.0248651
I0527 11:16:12.605315 7509 solver.cpp:337] Iteration 10500, Testing net (#0)
I0527 11:16:12.683331 7509 solver.cpp:404] Test net output #0: accuracy = 0.9907
I0527 11:16:12.683354 7509 solver.cpp:404] Test net output #1: loss = 0.0299526 (* 1 = 0.0299526 loss)
stage4
I1102 17:28:53.363138 29602 cmp_conv_layer.cpp:47] CONV THR: 0 0.33
I1102 17:28:53.363155 29602 cmp_conv_layer.cpp:65] sparsity: 0.33
I1102 17:28:53.363728 29602 cmp_conv_layer.cpp:47] CONV THR: 0 0.8
I1102 17:28:53.363800 29602 cmp_conv_layer.cpp:65] sparsity: 0.8
I1102 17:28:53.371803 29602 cmp_inner_product_layer.cpp:46] THR: 0
I1102 17:28:53.372537 29602 cmp_inner_product_layer.cpp:62] sparsity: 0.9
I1102 17:28:53.372779 29602 cmp_inner_product_layer.cpp:46] THR: 0.0979528
I0527 11:16:41.465282 7631 solver.cpp:317] Iteration 11000, loss = 0.00405698
I0527 11:16:41.465301 7631 solver.cpp:337] Iteration 11000, Testing net (#0)
I0527 11:16:41.544684 7631 solver.cpp:404] Test net output #0: accuracy = 0.9908
I0527 11:16:41.544704 7631 solver.cpp:404] Test net output #1: loss = 0.0296194 (* 1 = 0.0296194 loss)
stage5
I1102 17:29:10.394448 29928 cmp_conv_layer.cpp:47] CONV THR: 0 0.33
I1102 17:29:10.394480 29928 cmp_conv_layer.cpp:65] sparsity: 0.33
I1102 17:29:10.395453 29928 cmp_conv_layer.cpp:47] CONV THR: 0 0.8
I1102 17:29:10.395548 29928 cmp_conv_layer.cpp:65] sparsity: 0.8
I1102 17:29:10.408223 29928 cmp_inner_product_layer.cpp:46] THR: 0
I1102 17:29:10.408944 29928 cmp_inner_product_layer.cpp:62] sparsity: 0.9
I1102 17:29:10.472780 29928 cmp_inner_product_layer.cpp:46] THR: 0
I1102 17:29:10.472833 29928 cmp_inner_product_layer.cpp:62] sparsity: 0.8
I1102 17:29:10.477787 29928 cmp_conv_layer.cpp:47] CONV THR: 0 0.33
I1102 17:29:10.477800 29928 cmp_conv_layer.cpp:65] sparsity: 0.33
I0527 11:16:43.887966 7733 solver.cpp:317] Iteration 500, loss = 0.0114702
I0527 11:16:43.887984 7733 solver.cpp:337] Iteration 500, Testing net (#0)
I0527 11:16:43.971312 7733 solver.cpp:404] Test net output #0: accuracy = 0.9905
I0527 11:16:43.971331 7733 solver.cpp:404] Test net output #1: loss = 0.0297006 (* 1 = 0.0297006 loss)附滤波器参数可视化代码:
import os
import numpy as np
import matplotlib.pyplot as plt
import caffe
import cv2
def draw_filters(name,weights):
data = weights.copy()
data -= data.min()
data /= data.max()
sh = data.shape
width = sh[3]
height =sh[2]
c_out = sh[0]
c_in = sh[1]
savedir="filters/"+name
if not os.path.exists(savedir):
os.makedirs(savedir)
for i in range(c_out):
for j in range(c_in):
img = np.zeros((height*100,width*100,3),dtype=np.float32)
#img = data[i][j]
for h in range(height):
for w in range(width):
img[h*100:(h+1)*100,w*100:(w+1)*100,:]=data[i][j][h][w]
v = round(weights[i][j][h][w],5)
cv2.putText(img,str(v),(w*100,h*100+60),1,1,(0,0,255))
savepath = savedir+"/"+str(i)+"_"+str(j)+".jpg"
cv2.imwrite(savepath,img*255)
def draw_linear(name,weights):
data = weights.copy()
data -= data.min()
data /= data.max()
sh = data.shape
c_out = sh[0]
c_in = sh[1]
savedir="filters/"+name
if not os.path.exists(savedir):
os.makedirs(savedir)
for i in range(c_out):
img = np.zeros((c_in*2,1000,3),dtype=np.float32)
for j in range(int(c_in/10)):
for k in range(10):
img[j*20:(j+1)*20,k*100:(k+1)*100,:]=data[i][j*10+k]
v = round(weights[i][j*10+k],7)
cv2.putText(img,str(v),(k*100,j*20+15),1,1,(0,0,255))
savepath = savedir+"/"+str(i)+".jpg"
cv2.imwrite(savepath,img*255)
if __name__=="__main__":
prototxt="lenet_deploy.prototxt"
#caffemodel="models/lenet_iter_10000.caffemodel"
#caffemodel="models/lenet_finetune_stage1_iter_500.caffemodel"
#caffemodel="models/lenet_finetune_stage2_iter_1000.caffemodel"
#caffemodel="models/lenet_finetune_stage3_iter_10500.caffemodel"
#caffemodel="models/lenet_finetune_stage4_iter_11000.caffemodel"
caffemodel="models/lenet_finetune_stage5_iter_500.caffemodel"
net = caffe.Net(prototxt,caffemodel,caffe.TEST)
for item in net.params.items():
name, layer = item
print(name)
layer_type = net.layer_dict[name].type
if layer_type == "Convolution":
if name == "conv1":
draw_filters(name,layer[0].data)
elif layer_type == "InnerProduct":
if name =="fc2":
draw_linear(name,layer[0].data)2.量化
为什么能做int8量化?
- (1) CNN对噪声不敏感 -> Int8有用
- (2) 模型太大,对存储和计算需求较大 -> 量化能有效降低推理过程中对存储和算力需求
- (3) 每个层weights波动范围不大 -> 适合做量化
量化的本质就是在原信号上进行采样: FP32 Tensor (T) = scale_factor(sf) * 8-bit Tensor(t)
量化的流程:

//首先分成 2048个组,每组包含多个数值(基本都是小数)
Input: FP32 histogram H with 2048 bins: bin[ 0 ], …, bin[ 2047 ]
For i in range( 128 , 2048 ): // |T|的取值肯定在 第128-2047 组之间,取每组的中点
reference_distribution_P = [ bin[ 0 ] , ..., bin[ i-1 ] ] // 选取前 i 组构成P,i>=128
outliers_count = sum( bin[ i ] , bin[ i+1 ] , … , bin[ 2047 ] ) //边界外的组
reference_distribution_P[ i-1 ] += outliers_count //边界外的组加到边界P[i-1]上,没有直接丢掉
P /= sum(P) // 归一化
// 将前面的P(包含i个组,i>=128),映射到 0-128 上,映射后的称为Q,Q包含128个组,
// 一个整数是一组
candidate_distribution_Q = quantize [ bin[ 0 ], …, bin[ i-1 ] ] into 128 levels
//这时的P(包含i个组,i>=128)和Q向量(包含128个组)的大小是不一样的,无法直接计算二者的KL散度
//因此需要将Q扩展为 i 个组,以保证跟P大小一样
expand candidate_distribution_Q to ‘ i ’ bins
Q /= sum(Q) // 归一化
//计算P和Q的KL散度
divergence[ i ] = KL_divergence( reference_distribution_P, candidate_distribution_Q)
End For
//找出 divergence[ i ] 最小的数值,假设 divergence[m] 最小,
//那么|T|=( m + 0.5 ) * ( width of a bin )
Find index ‘m’ for which divergence[ m ] is minimal
threshold = ( m + 0.5 ) * ( width of a bin )通过不断地构造P和Q,并计算相对熵,然后找到最小(截断长度为m)的相对熵,此时表示Q能极好地拟合P分布了,而阀值就等于(m + 0.5)*一个bin的长度. 通过上述步骤就能得到校准表,然后送入量化模块进行量化,那么在端上如何使用呢?NCNN Conv进行Int8计算时,计算流程如下:

在进行conv前,对input和weight做量化,计算完后反量化到fp32,再加bias
NCNN首先将输入(bottom_blob)和权重(weight_blob)量化成INT8,在INT8下计算卷积,然后反量化到fp32,再和未量化的bias相加,得到输出(top_blob)
quantize(量化)公式为
![]()
![]()
在做前向inference(推理)时,计算输入和权重的乘积:
![]()
所以dequantize(反量化)时,反量化因子为:
![]()
进行前向推理运算时,有:
![]()
附caffe训好的模型一键式转换ncnn和运行
@echo off
set NCNN_DIR=D:/CNN/ncnn
set TOOLS=%NCNN_DIR%/build/tools/caffe/Release/caffe2ncnn
SET OPT=%NCNN_DIR%/build/tools/Release/ncnnoptimize
set NCNN2TABLE=%NCNN_DIR%/build/tools/quantize/Release/ncnn2table
set NCNN2int8=%NCNN_DIR%/build/tools/quantize/Release/ncnn2int8
set MODEL_NAME=mobilenet_ssd_voc
set IMAGES=images
call:ncnntools
rem method 1: use caffe-int8-convert-tools
:caffe2ncnn
echo "generating quantization table"
set pytool=D:/CNN/caffe_models/caffe-int8-convert-tools/caffe-int8-convert-tool-dev-weight.py
python %pytool% --proto=%MODEL_NAME%-depth.prototxt --model=%MODEL_NAME%.caffemodel --mean 127.5 127.5 127.5 --norm 0.007843 --images=%IMAGES% --output=%MODEL_NAME%.table --gpu=1
echo "converting model"
rem "%TOOLS%" %MODEL_NAME%.prototxt %MODEL_NAME%.caffemodel %MODEL_NAME%.param %MODEL_NAME%.bin
"%TOOLS%" %MODEL_NAME%.prototxt %MODEL_NAME%.caffemodel %MODEL_NAME%-int8.param %MODEL_NAME%-int8.bin 256 %MODEL_NAME%.table
goto:run
rem mtehod 2: use ncnnoptimize ncnn2table ncnn2int8
:ncnntools
"%TOOLS%" %MODEL_NAME%.prototxt %MODEL_NAME%.caffemodel %MODEL_NAME%.param %MODEL_NAME%.bin
"%OPT%" %MODEL_NAME%.param %MODEL_NAME%.bin %MODEL_NAME%.param %MODEL_NAME%.bin 1
"%NCNN2TABLE%" --param=%MODEL_NAME%.param --bin=%MODEL_NAME%.bin --images=%IMAGES% --output=%MODEL_NAME%.table --mean=127.5,127.5,127.5 --norm=0.007843,0.007843,0.007843 --size=300,300 --thread=4 --swapRB=0
"%NCNN2int8%" %MODEL_NAME%.param %MODEL_NAME%.bin %MODEL_NAME%-int8.param %MODEL_NAME%-int8.bin %MODEL_NAME%.table
goto:run
:run
echo "start running demo"
"../x64/Release/voc" images/test.jpg
pause运行日志:
Collect histograms of activations:
loop stage 2 : 0/2
conv0 bin : 2046 threshold : 0.999250 interval : 0.000488 scale : 127.095313
conv1 bin : 767 threshold : 11.684288 interval : 0.015224 scale : 10.869297
conv2 bin : 1279 threshold : 10.785722 interval : 0.008430 scale : 11.774826
conv3 bin : 1151 threshold : 24.829513 interval : 0.021563 scale : 5.114881
conv4 bin : 1535 threshold : 9.157705 interval : 0.005964 scale : 13.868103
conv5 bin : 1279 threshold : 9.892059 interval : 0.007731 scale : 12.838580
conv6 bin : 895 threshold : 7.349082 interval : 0.008207 scale : 17.281069
conv7 bin : 1535 threshold : 9.801176 interval : 0.006383 scale : 12.957628
conv8 bin : 1151 threshold : 7.922781 interval : 0.006880 scale : 16.029725
conv9 bin : 1279 threshold : 7.027348 interval : 0.005492 scale : 18.072251
conv10 bin : 1279 threshold : 8.220346 interval : 0.006425 scale : 15.449472
conv11 bin : 1663 threshold : 8.217446 interval : 0.004940 scale : 15.454924
conv13 bin : 1279 threshold : 14.380681 interval : 0.011239 scale : 8.831292
conv14_1 bin : 1791 threshold : 23.348444 interval : 0.013033 scale : 5.439335
conv14_2 bin : 1535 threshold : 5.194996 interval : 0.003383 scale : 24.446602
conv15_1 bin : 2046 threshold : 3.439832 interval : 0.001681 scale : 36.920405
conv15_2 bin : 2046 threshold : 2.459520 interval : 0.001202 scale : 51.636100
conv16_1 bin : 2046 threshold : 4.317693 interval : 0.002110 scale : 29.413857
conv16_2 bin : 1535 threshold : 1.746493 interval : 0.001137 scale : 72.717155
conv17_1 bin : 2046 threshold : 3.930415 interval : 0.001921 scale : 32.312110
conv17_2 bin : 1919 threshold : 2.801916 interval : 0.001460 scale : 45.326128
conv11_mbox_loc bin : 2046 threshold : 5.171228 interval : 0.002527 scale : 24.558963
conv11_mbox_conf bin : 2046 threshold : 5.171228 interval : 0.002527 scale : 24.558963
conv13_mbox_loc bin : 1791 threshold : 23.348444 interval : 0.013033 scale : 5.439335
conv13_mbox_conf bin : 1791 threshold : 23.348444 interval : 0.013033 scale : 5.439335
conv14_2_mbox_loc bin : 2046 threshold : 3.439832 interval : 0.001681 scale : 36.920405
conv14_2_mbox_conf bin : 2046 threshold : 3.439832 interval : 0.001681 scale : 36.920405
conv15_2_mbox_loc bin : 2046 threshold : 4.317693 interval : 0.002110 scale : 29.413857
conv15_2_mbox_conf bin : 2046 threshold : 4.317693 interval : 0.002110 scale : 29.413857
conv16_2_mbox_loc bin : 2046 threshold : 3.930415 interval : 0.001921 scale : 32.312110
conv16_2_mbox_conf bin : 2046 threshold : 3.930415 interval : 0.001921 scale : 32.312110
conv17_2_mbox_loc bin : 1663 threshold : 4.633778 interval : 0.002786 scale : 27.407440
conv17_2_mbox_conf bin : 1663 threshold : 4.633778 interval : 0.002786 scale : 27.407440
Caffe Int8 Calibration table create success, it's cost 0:01:16.598000, best wish for your INT8 inference has a low accuracy loss...\(^鈻絕)/...2333...注意mobilenet-ssd中的pointwise-dw层不要去量化,否则损失会很大.
TensorRT(5)-INT8校准原理
模型量化原理笔记
Int8量化-介绍(一)
Int8量化 - python实现以及代码分析(二)
NCNN Conv量化详解(一)
NCNN量化详解(二)
Int8量化-Winograd量化原理及实现
基于Caffe-Int8-Convert-Tools进行caffe模型转int8量化日常记录
Pytorch 模型量化实战