深入解读AlphaGo,Nature-2016:Mastering the game of Go with deep neural networks and tree search
主要参考:
http://blog.csdn.net/songrotek/article/details/51065143
http://blog.csdn.net/songrotek/article/details/50610684
http://studygolang.com/articles/6466
http://www.360doc.com/content/16/0317/09/31057678_542874401.shtml
http://blog.csdn.net/u010165147/article/details/50885325
本文将分析AlphaGo的这篇Nature文章,去解密真人工智能的奥秘!
AlphaGo的”大脑“是怎样的
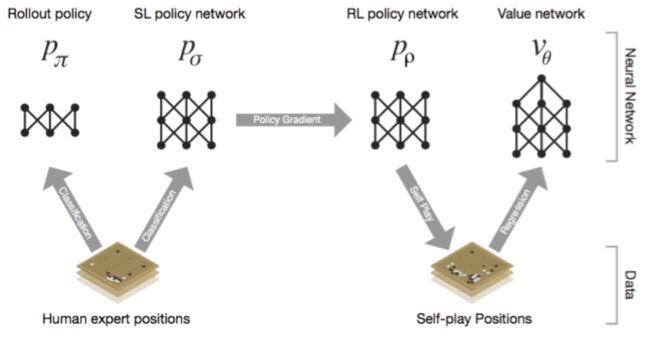
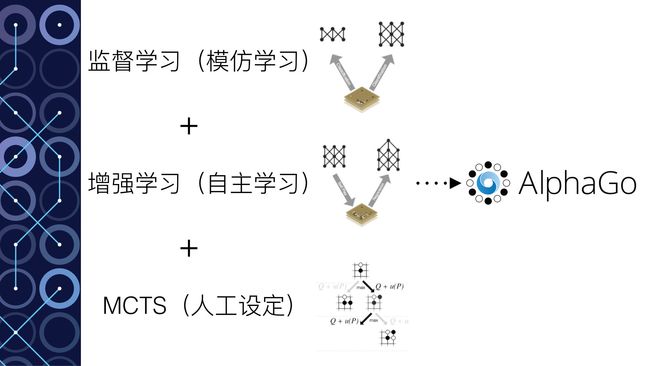
深度神经网络是AlphaGo的”大脑“,我们先把它当做一个黑匣子,有输入端,也有输出端,中间具体怎么处理先不考虑。那么AlphaGo的”大脑“实际上分成了四大部分:
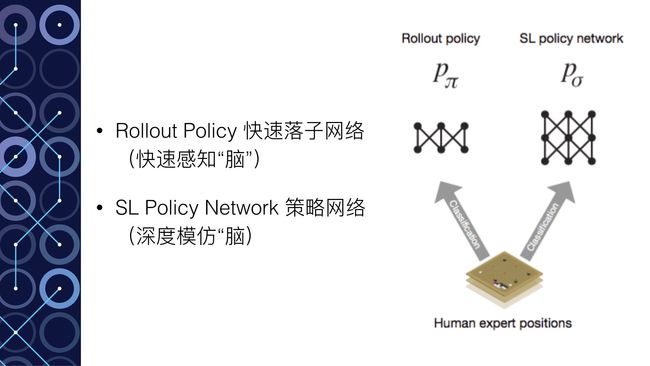
- Rollout Policy 快速感知”脑“:用于快速的感知围棋的盘面,获取较优的下棋选择,类似于人观察盘面获得的第一反应,准确度不高
- SL Policy Network 深度模仿”脑“:通过人类6-9段高手的棋局来进行模仿学习得到的脑区。这个深度模仿“脑”能够根据盘面产生类似人类棋手的走法。
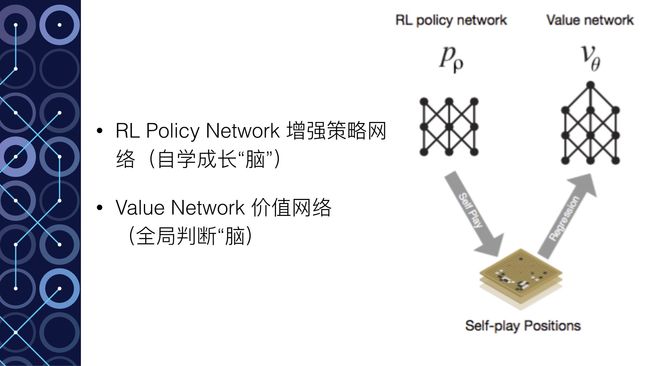
- RL Policy Network 自学成长“脑”:以深度模仿“脑”为基础,通过不断的与之前的“自己”训练提高下棋的水平。
- Value Network 全局分析“脑”:利用自学成长“脑”学习对整个盘面的赢面判断,实现从全局分析整个棋局。
所以,AlphaGo的“大脑”实际上有四个脑区,每个脑区的功能不一样,但对比一下发现这些能力基本对于人类棋手下棋所需的不同思维,既包含局部的计算,也包含全局的分析。其中的Policy Network用于具体每一步棋的优劣判断,而Value Network则对整个棋局进行形势的判断。
而且很重要的是,AlphaGo提升棋力首先是依靠模仿,也就是基于深度模仿“脑”来进行自我水平的提升。这和人类的学习方式其实是一模一样的。一开始都是模仿别人的下法,然后慢慢的产生自己的下法。
那么这些不同的脑区的性能如何呢?
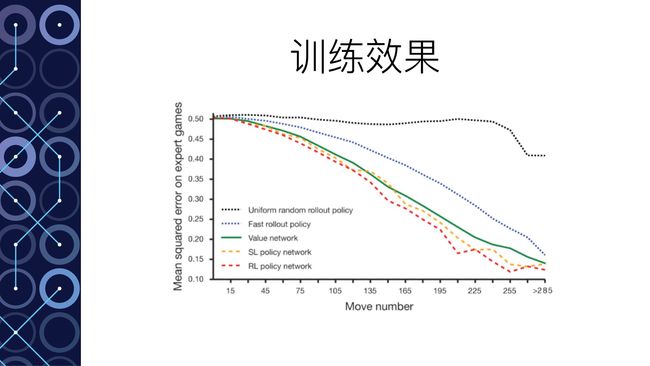
- 快速感知“脑”对下棋选择的判断对比人类高手的下棋选择只有24.2%的正确率
- 深度模仿“脑”对下棋选择的判断对比人类高手的下棋选择只有57.0%的正确率,也就是使用深度模仿“脑”,本身就有一半以上的几率选择和人类高手一样的走法。
- 自学成长“脑”在经过不断的自学改进之后,与深度模仿“脑”进行比赛,竟然达到80%的胜利。这本质上说明了通过自我学习,在下棋水平上取得了巨大的提升。
- 全局分析“脑”使用自学成长“脑”学习训练后,对全局局势的判断均方差在0.22~0.23之间。也就是有大约80%的概率对局面的形势判断是对的。这是AlphaGo能够达到职业棋手水准的关键所在。
从上面的分析可以看到AlphaGo的不同“脑区”的强大。具体每个大脑是怎么学习的在之后的小节分析,我们先来看看有了这些训练好的大脑之后AlphaGo是如何下棋的。
AlphaGo 是如何下棋的?
在分析AlphaGo是如何下棋之前,我们先来看看一下人类棋手会怎么下棋:
- Step 1:分析判断全局的形势
- Step 2:分析判断局部的棋局找到几个可能的落子点
- Step 3:预测接下来几步的棋局变化,判断并选择最佳的落子点。
那么,AlphaGo在拥有强大的神经网络”大脑“的基础上采用蒙特卡洛树搜索来获取最佳的落子点,本质上和人类的做法是接近的。
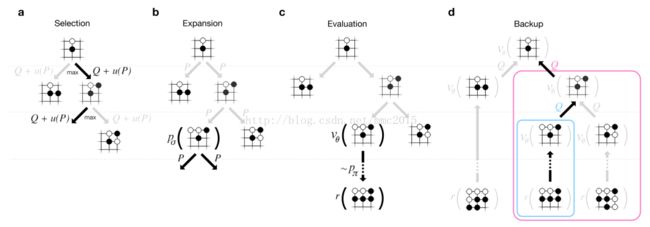
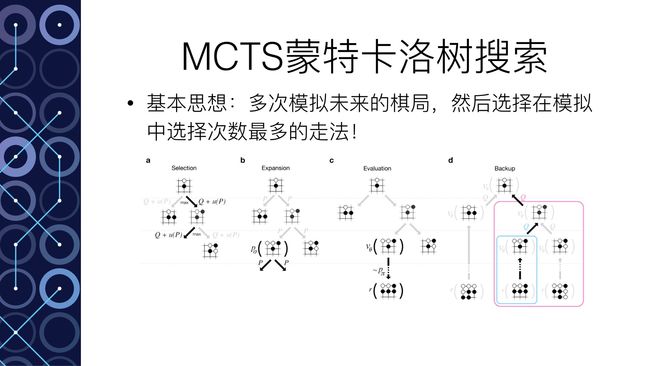
首先是采用蒙特卡洛树搜索的基本思想,其实很简单:
多次模拟未来的棋局,评估每一个走法,然后选择在模拟中被选择次数最多的走法
AlphaGo具体的下棋基本思想如下(忽略掉一些技术细节比如拓展叶节点):
对于当前的棋局,选择一种可能的下一步走法(step1);评估该走法的好坏(step2);进行多次模拟,每一次模拟结束后,考虑之前所有的模拟结果,如果出现同样的走法((s,a)相同),则对Q(s,a)进行取均值操作(step3)
- Step 1:基于
深度模仿“脑”来预测未来的下一步走法,直到L步。 - Step 2:结合两种方式来对未来到L的走势进行评估,一个是使用全局分析“脑”进行评估,判断赢面,一个是使用快速感知“脑”做进一步的预测直到比赛结束得到模拟的结果。综合两者对预测到未来L步走法进行评估。V(sL) = (1- λ)vθ(sL) + λzL 。评估完,将评估结果V (sL) 作为当前棋局下 一开始给出的下一步走法 的估值。
- Step 3:结合之前的模拟结果,如果出现同样的走法,则对走法的估值取平均(蒙特卡洛的思想在这里)
反复循环上面的步骤到n次。然后选择选择次数最多的走法作为下一步(Once the search is complete, the algorithm chooses the most visited move from the root position. )。
分析到这里,大家就可以理解为什么在AlphaGo与Fan Hui的比赛中,有一些AlphaGo的落子并不仅仅考虑局部的战术,也考虑了整体的战略。
知道了AlphaGo的具体下棋方法之后,我们会明白让AlphaGo棋力如此之强的还是在于AlphaGo的几个深度神经网络上。
所以,让我们看看AlphaGo的大脑是怎么学习来的。
AlphaGo是如何学习的?
AlphaGo的学习依赖于深度学习Deep Learning和增强学习Reinforcement Learning,合起来就是Deep Reinforcement Learning。这实际上当前人工智能界最前沿的研究方向。
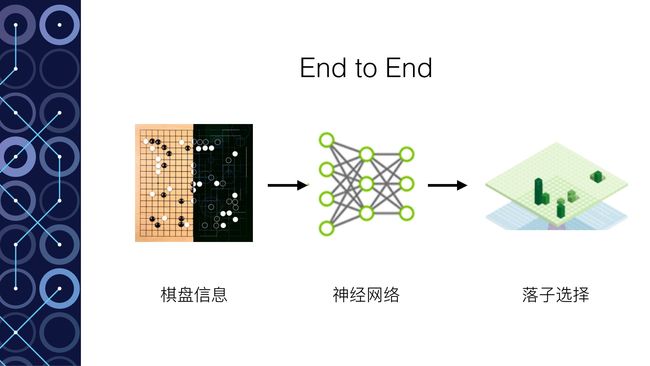
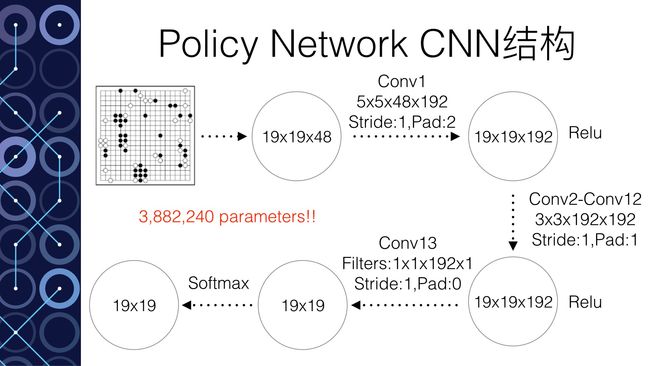
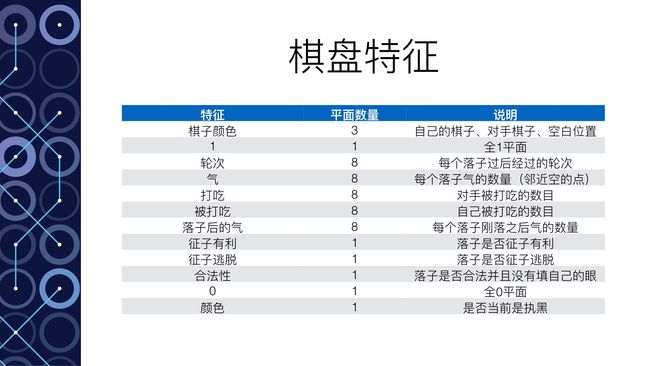
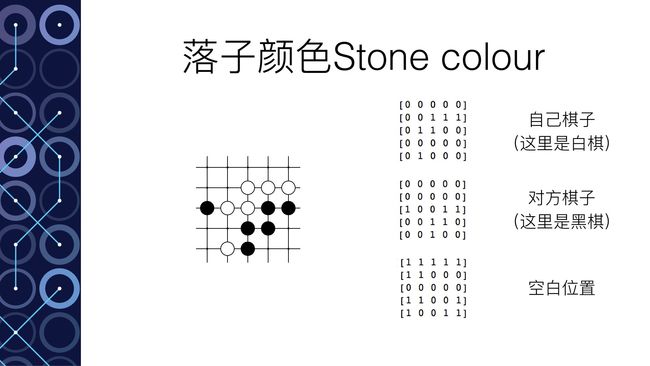
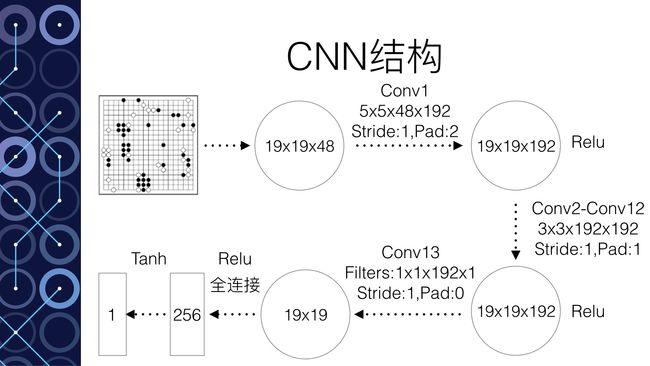
以深度模拟“脑”为例。这个实际上是一个12层的神经网络。输入主要是整个棋盘的19*19的信息(比如黑棋的信息,白棋的信息,空着的信息,还有其他一些和围棋规则有关的信息一共48种)。输出要求是下一步的落子。那么Google Deepmind拥有3000万个落子的数据,这就是训练集,根据输出的误差就可以进行神经网络的训练。训练结束达到57%的正确率。也就是说输入一个棋盘的棋局状态,输出的落子有一半以上选择了和人类高手一样的落子方式。从某种意义上讲,就是这个神经网络领悟了棋局,从而能够得到和人类高手一样的落子方法。
接下来的自学成长“脑”采用深度增强学习(deep reinforcement learning)来更新深度神经网络的参数。通过反复和过去的“自己”下棋来获得数据,通过输赢来判断好坏,根据好坏结果计算策略梯度,从而更新参数。通过反复的自学,我们看到自学成长“脑”可以80%胜率战胜深度模仿“脑”,说明了这种学习的成功,进一步说明自学成长“脑”自己产生了新的下棋方法,形成了自己的一套更强的下棋风格。
深度解读AlphaGo