Python实现向量自回归(VAR)模型——完整步骤
废话不多说,先开始分享:
1. 首先啥是VAR模型,我这里简略通俗的说一下,想看代码的童鞋直接跳到第3部分就好了:
以金融价格为例,传统的时间序列模型比如ARIMA,ARIMA-GARCH等,只分析价格自身的变化,模型的形式为:
![]()
其中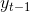 称为自身的滞后项。
称为自身的滞后项。
但是VAR模型除了分析自身滞后项的影响外,还分析其他相关因素的滞后项对未来值产生的影响,模型的形式为:
![]()
其中 就是其他因子的滞后项。
就是其他因子的滞后项。
总结一下,就是可以把VAR模型看做是集合多元线性回归的优点(可以加入多个因子)以及时间序列模型的优点(可以分析滞后项的影响)的综合模型。
VAR其实是一类模型,以上是最基础的VAR模型形式,其他还有SVAR,CVAR,VECM,同统称为VAR类模型。
2. VAR模型的建模步骤
这种数学模型都有固定的建模步骤:
1)画N个因子的序列相关图,计算相关系数 correlation coiffiant,查看一下线性相关度。(相关系数大小只反映线性相关程度,不反应非线性相关,如果等于0,不能排除存在非线性相关的可能。)
2)对N个因子的原始数据进行平稳性检验,也就是ADF检验。
VAR模型要求所有因子数据同阶协整,也就是N个因子里面如果有一个因子数据不平稳,就要全体做差分,一直到平稳为止。
3)对应变量(yt)和影响因子(Xt)做协整检验
一般就是EG协整关系检验了,为了看看Y和各个因子Xi之间是否存在长期平稳的关系,这个检验要放在所有数据都通过ADF检验以后才可以做。如果那个因子通不过协整检验,那基本就要剔除了。
4)然后就是通过AIC,BIC,以及LR定阶。
一般来说是综合判断三者。AIC,BIC要最小的,比如-10的AIC就优于-1AIC,LR反之要最大的。但是具体偏重那个,就看个人偏好,一般来说,博主的经验是看AIC和LR,因为BIC的惩罚力度大于AIC,大多数时间不太好用。
具体的实现步骤一般是,把滞后项的阶数列一个范围,比如1-5,然后直接建模,其他啥都不看,先看AIC,BIC,LR的值。一般符合条件的不会只有一个,可以挑2-3个最好的,继续进行。
5)定阶完成后,就是估计参数,看参数的显著性。
好的模型所有参数的要通过显著性检验。
6)对参数进行稳定性检验
VAR除了对原始数据要进行平稳处理,估计出来的参数还需要检验参数稳定性。
这是为了查看模型在拟合时,数据样本有没有发生结构性变化。
有两张检验方法,这两种方法的基本概念是:
第一个是:AR根,VAR模型特征方程根的绝对值的倒数要在单位圆里面。
第二个是:cusum检验,模型残差累积和在一个区间内波动,不超出区间。
这里要注意的是CUSUM检验的原价设(H0):系数平稳,备择假设才是不平稳。所以CUSUM结果要无法拒绝原假设才算通过。
只有通过参数稳定性检验的模型才具有预测能力,进行脉冲响应和方法分解分析才有意义。
7)使用乔里斯基正交化残差进行脉冲响应分析
举例:要分析和预测的是Y,影响Y的有两个因子X1,X2。
脉冲响应是1对1,根据以上条件,就要做两个脉冲响应分析,分别是:Y和X1,Y和X2。
看看不同因子上升或者下降,对Y的冲击的程度和方式(Y上升还是下降),以及持续时间。
8)使用乔里斯基正交化残差进行方差分解分析
举例:要分析和预测的是Y,影响Y的有两个因子X1,X2。
方差分解是1对1,根据以上条件,就要做两个方差分解分析,分别是:Y和X1,Y和X2。
9)为什么使用乔里斯基正交化残差?
因为进行方差分解和脉冲响应分析的时候,要求模型的残差为白噪声。但是!现实中,我们很难把所有影响Y的因素都囊括进方程,这就导致,现实中VAR模型的残差一般都不是白噪声。因此使用乔里斯基正交化来处理模型的残差。
VAR建模的时候以上面的条件为例,其实模型估计参数时会给出三个3个方程(应变量各自不同):
方程1:![]()
方程2:![]()
方程3:![]()
方程1的残差序列: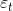
方程2的残差序列:![]()
方差3的残差序列:![]()
三个方程的乔里斯基正交化的步骤就是:
正交1:![]()
正交2:![]()
正交3:![]()
正交4:![]()
正交5:![]()
最后用正交4/正交5,得到的序列就是乔里斯基正交化残差了。
乔里斯基正交化之前要对方程的变量按重要性排序,更重要的放在分子上。
3. 然后就是如何使用PYTHON 实现VAR模型的建模了:
以上的步骤是不是很庞大,看着很麻烦?但是电脑都会一下子嗖嗖嗖处理好的。
1)导入模块
# 模型相关包
import statsmodels.api as sm
import statsmodels.stats.diagnostic
# 画图包
import matplotlib.pyplot as plt
# 其他包
import pandas as pd
import numpy as np
2)画序列相关图
fig = plt.figure(figsize=(12,8))
plt.plot(changeXAUUSD,'r',label='XAU USD')
plt.plot(shfeXAU,'g',label='SHFE XAU')
plt.title('Correlation: ' + str(correlation))
plt.grid(True)
plt.axis('tight')
plt.legend(loc=0)
plt.ylabel('Price')
plt.show()3)ADF单位根
python里的ADF检验结果就是下面的adfResult,我这里用output整理了一下,方便浏览。童鞋们也可以print结果,然后自行整理。
这里的数据格式应该是DataFrame里面的series格式,不过dataframe应该也可以吧,没试过。
adfResult = sm.tsa.stattools.adfuller(data,maxlags)
output = pd.DataFrame(index=['Test Statistic Value', "p-value", "Lags Used", "Number of Observations Used",
"Critical Value(1%)", "Critical Value(5%)", "Critical Value(10%)"],
columns=['value'])
output['value']['Test Statistic Value'] = adfResult[0]
output['value']['p-value'] = adfResult[1]
output['value']['Lags Used'] = adfResult[2]
output['value']['Number of Observations Used'] = adfResult[3]
output['value']['Critical Value(1%)'] = adfResult[4]['1%']
output['value']['Critical Value(5%)'] = adfResult[4]['5%']
output['value']['Critical Value(10%)'] = adfResult[4]['10%']4)协整检验
python里面的协整检验通过coint()这个函数进行的,返回P-value值,越小,说明协整关系越强。
result = sm.tsa.stattools.coint(data1,data2)5)模型估计+定阶
这里PYTHON真的很烦,python有两套var估计,一个是VARMAX,一个是VAR。我看了官方文档后,觉得估计参数和定阶还是用VARMAX最好,因为可以返回很多东西,尤其是summary()里面的统计结果特别详细,直接包含了AIC,BIC,HQIC。
这里要注意,PYTHON定阶没有LR这个指标,要看LR的童鞋只能用EVIEWS和R了。不过AIC,BIC也够用了。
这里插入的数据只能是DATAFRAME格式的,不然就报错。
给大家看一下数据构造吧:
lnDataDict = {'lnSHFEDiff':lnSHFEDiff,'lnXAUDiff':lnXAUDiff}
lnDataDictSeries = pd.DataFrame(lnDataDict,index=lnSHFEDiffIndex)
data = lnDataDictSeries[['lnSHFEDiff','lnXAUDiff']]这里的fitMod和resid变量后面会用到哦~~
#建立对象,dataframe就是前面的data,varLagNum就是你自己定的滞后阶数
orgMod = sm.tsa.VARMAX(dataframe,order=(varLagNum,0),trend='nc',exog=None)
#估计:就是模型
fitMod = orgMod.fit(maxiter=1000,disp=False)
# 打印统计结果
print(fitMod.summary())
# 获得模型残差
resid = fitMod.resid
result = {'fitMod':fitMod,'resid':resid}6)系数平稳检验:CUSUM检验
这里也注意,Python这里不像EVIEWS,python没有办法算AR根,弄不到AR根图,但是python可以进行cusum检验。返回3各变量,第2个是P-value值,记得我之前说的吗,cusum检验要无法拒绝原假设,也就是说P-value值要大于0.05
这里的resid就是前面模型的resid
# 原假设:无漂移(平稳),备择假设:有漂移(不平稳)
result = statsmodels.stats.diagnostic.breaks_cusumolsresid(resid)7)脉冲响应图
orthogonalized=True代表使用乔里斯基正交,这里很奇葩,官方文档没有加plt.show(),但是博主亲身试验,一定要加,不然画不出来。terms代表周期数。
# orthogonalized=True,代表采用乔里斯基正交
ax = fitMod.impulse_responses(terms, orthogonalized=True).plot(figsize=(12, 8))
plt.show()8)方差分解图
这里要注意:
VARMAX很怪,没有做方差分解的方法,但是VAR这个方法里面有。(python就是这么任性!)
所以这里就用VAR重新估计,然后直接使用fevd进行方差分解。
打印summary()可以看到方差分解的具体结果,plot可以画图,要记得加plt.show()哦~~
这里的dataFrame就是前面的data噢~~
md = sm.tsa.VAR(dataFrame)
re = md.fit(2)
fevd = re.fevd(10)
# 打印出方差分解的结果
print(fevd.summary())
# 画图
fevd.plot(figsize=(12, 16))
plt.show()
以上就是今日份的分享~~然后博主要开始吐槽了!
博主真是苦逼,最近定期要写研报,博主挑了个向量自回归模型(VAR)来研究,然而博主之前接触过的就只有MATLAB和python,matlab虽然做这种统计很方便,但是一个是博主好久不用啦有点生疏,还有一个是跟项目开发合在一起的话不方便。
然后博主现在天天用python,所以为了赶稿子,也只能硬着头皮用python搞一波了。但是,博主发现,全网,基本没有人用python搞过这种高级计量经济学模型,因为连范文都找不到1篇!!!!博主亲身尝试摸索后,虽然完成了研报,但是!博主还是要说,统计类的东西,要么用R,要么用EVIEWS,用Python真心苦逼!!!
主要是各个函数都藏在不知道什么旮旯角落里!!!有些还没有!比如AR根和AR图,要不是靠参考链接里R语言的一篇样板文,我都不知道还有个检验系数稳定性的方法叫cusum,再从另一篇样例里面找到python做cusum的样例。cusum的原假设和备择假设还跟普通检验不一样,反过来的,我查了好多中外文献,才确定这一点。python里面还没有EG因果关系检验,而协整关系检验的名字竟然叫coint……也是从另一篇样例文中找到的!!!都是泪…………
然后,python只能对VAR模型,VECM模型进行估计,其他var类模型,各位别白废力气寻找了,直接用EVIEWS或者R吧。
好啦~吐槽结束,博主可以保证,这是全网唯一的,最完整的利用python进行VAR模型建模的教程文了~~~
参考文献:
1. VARMAX官方样例
http://www.statsmodels.org/stable/examples/notebooks/generated/statespace_varmax.html
2. VARMAX官方文档
http://www.statsmodels.org/stable/generated/statsmodels.tsa.statespace.varmax.VARMAX.html?highlight=varmax
3.VARMAX fit官方文档
http://www.statsmodels.org/stable/generated/statsmodels.tsa.statespace.varmax.VARMAX.fit.html#statsmodels.tsa.statespace.varmax.VARMAX.fit
4.VARMAX fit返回值
http://www.statsmodels.org/stable/generated/statsmodels.tsa.statespace.mlemodel.MLEResults.html#statsmodels.tsa.statespace.mlemodel.MLEResults
5. CUSUM检验文献:平稳过程趋势项变点的CUSUM检验
https://www.ixueshu.com/document/1d642b472b5dc0717d721b29bfac1625.html#pdfpreview
6. CUSUM检验文献:关于CUSUM检验的改进
https://wenku.baidu.com/view/65d91ee1172ded630b1cb62c.html
7. cusum外文文献
https://doc.docsou.com/b77f40843604bd6fcc70f6d0b-10.html
8.python实现时间序列
https://max.book118.com/html/2017/1006/136205976.shtm
9.VAR python W3Cschool样例
https://www.w3cschool.cn/doc_statsmodels/statsmodels-examples-notebooks-generated-interactions_anova.html?lang=en
10.R语言实现VAR模型
https://blog.csdn.net/Imliao/article/details/80352158
11. python statsmodel手册
https://blog.csdn.net/qq_41518277/article/details/85101141#VARVAR_processes_175
12. python cusum检验方法说明:breaks_cusumolsresid
https://www.cherylgood.cn/doc/statsmodels/statsmodels-statistics/5bacda5744e2a52489c5292a.html
13.python 进行cusum检验样例
https://blog.csdn.net/CoderPai/article/details/83657386