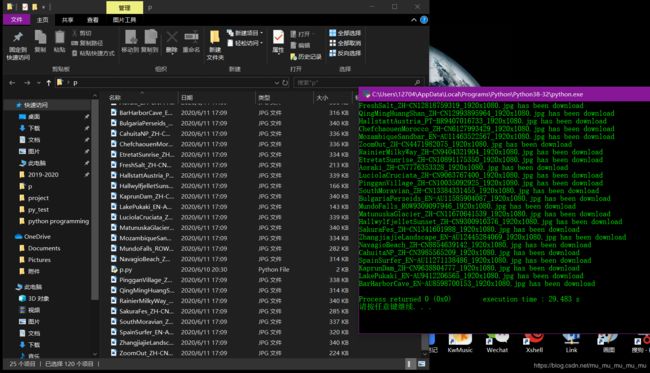
python爬虫----爬取bing电脑壁纸
爬取必应壁纸排行榜前10页的图片
import requests
import time
import re
head = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
for page in range(1, 11):
'''request website'''
website = 'https://bing.ioliu.cn/ranking?p=' + str(page)
response = requests.get(website, headers = head)
html_code = response.text
'''resolve website and get the photo website'''
urls_list = re.findall('', html_code)
'''get the photo's name by split in the photo website'''
photoname_list = [url.split('?')[0].split('/')[-1] for url in urls_list]
'''Splice to get the real picture address'''
start_str = 'http://h1.ioliu.cn/bing/'
end_str = '_1920x1080.jpg'
realsite_list = [start_str + photoname + end_str for photoname in photoname_list]
'''download photos'''
for realsite in realsite_list:
time.sleep(1)
file_name = realsite.split('/')[-1]
respon = requests.get(realsite, headers = head)
with open(file_name, 'wb') as f:
f.write(respon.content)
print(file_name + " has been download")
f.close()