最简单的单层神经网络实现鸢尾花分类
一,知识背景
鸢尾花的分类由四个数据定义,分别是花萼长、花萼宽、花瓣长、花瓣宽。我们把这样的一组数据称为是一组特征,根据特征可以分为三类鸢尾花。
二,神经元模型
神经元采用最简单的简化MP(麦卡洛克-皮茨)模型,模型表示如下:
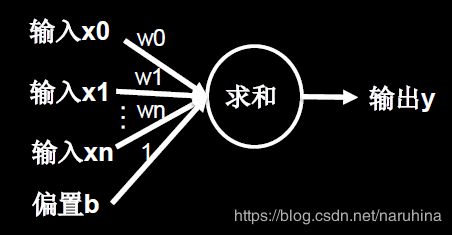
在鸢尾花分类的例子里,输入为x0,x1,x2,x3以及偏置项b。我们可以定义鸢尾花特征有四个维度,每个维度分别对应一个输入x。
简化模型可以表示为y=x0* w0+x1* w1+x2* w2+x3* w3+b。该形式是很经典的加权求和式,即每个特征维度都对输出结果起到一定的贡献,贡献多少由权重系数w定义。
三,神经网络模型
这里是最简单的单层网络,仅有一个输出层,没有隐藏层:
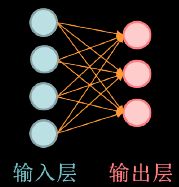
输入层输入的是一组特征,对应于特征的四个维度,输出层就是三个判别结果。网络的权重矩阵为四行三列的矩阵,输入特征应为一行四列矩阵,矩阵相乘得到一行三列矩阵,分别就是三种分类花型的结果。
四,权重更新方法
首先,我们定义损失函数为真实结果与预测结果的均方误差
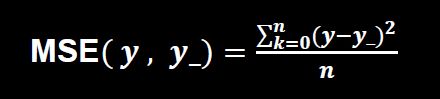
即平方误差的均值。(关于损失函数,有三大类,第一类以MSE为基准,第二类是以交叉熵为基准,第三类就是自行定义误差)
我们要做的是在在训练网络的过程中不断更新权重和偏置参数使得损失函数(loss function)不断减小最终收敛于某个值。整个过程与LMS法自适应滤波极为相似。保证损失函数下降的方法为取损失函数的梯度,在每次训练时沿着负梯度的方向更新参数:
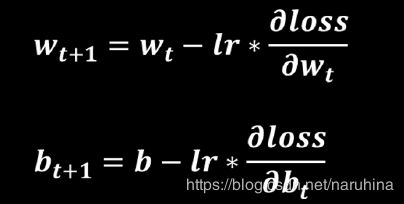
五,编程实现
编程实现分为以下几个步骤:
1.加载数据集
2.数据集乱序变换
3.数据集分割为训练集和测试集
4.数据集中的特征与对应的标签配对
5.定义神经网络的权重系数矩阵和偏置
6.设定参数迭代轮次,每次迭代分为一次训练(内有若干批训练数据对网络进行训练),一次更新,以及一次测试(测试也是分为若干批测试数据对网络测试)
7.在训练过程中使用梯度下降法更新权重与偏置并给出训练过程中的损失函数值
8.训练完毕后输入测试数据,输出软分类结果,计算正确率
9.不断重复7和8直到参数迭代次数到达设定值。
# 导入所需模块
import tensorflow as tf
from sklearn import datasets
from matplotlib import pyplot as plt
import numpy as np
# 导入数据,分别为输入特征和标签
x_data = datasets.load_iris().data # 150行,4列
y_data = datasets.load_iris().target # 1行,150列
print(y_data)
# 随机打乱数据(因为原始数据是顺序的,顺序不打乱会影响准确率)
# seed: 随机数种子,是一个整数,当设置之后,每次生成的随机数都一样(为方便教学,以保每位同学结果一致)
np.random.seed(116) # 使用相同的seed,保证输入特征和标签一一对应,seed使用一次就失效了
np.random.shuffle(x_data) # shuffle函数可以打乱列表顺序,打乱的规则由seed决定
np.random.seed(116)
np.random.shuffle(y_data)
tf.random.set_seed(116)
# 将打乱后的数据集分割为训练集和测试集,训练集为前120行,测试集为后30行
x_train = x_data[:-30]
y_train = y_data[:-30]
x_test = x_data[-30:]
y_test = y_data[-30:]
# 转换x的数据类型,否则后面矩阵相乘时会因数据类型不一致报错
x_train = tf.cast(x_train, tf.float32)
x_test = tf.cast(x_test, tf.float32)
# from_tensor_slices函数使输入特征和标签值一一对应。(把数据集分批次,每个批次batch组数据)
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)
# train_db的遍历需要的循环次数为4,每次遍历是一个((),()),第一个括号为32行,4列的特征数据,第二个括号为1行32列的标签
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)
# test_db的遍历需要的循环次数为1,每次遍历是一个((),()),第一个括号为30行,4列的特征数据,第二个括号为1行30列的标签
# 生成神经网络的参数,4个输入特征故,输入层为4个输入节点;因为3分类,故输出层为3个神经元
# 用tf.Variable()标记参数可训练
# 使用seed使每次生成的随机数相同(方便教学,使大家结果都一致,在现实使用时不写seed)
w1 = tf.Variable(tf.random.truncated_normal([4, 3], stddev=0.1, seed=1))
b1 = tf.Variable(tf.random.truncated_normal([3], stddev=0.1, seed=1)) # 一行三列
lr = 0.1 # 学习率为0.1
train_loss_results = [] # 将每轮的loss记录在此列表中,为后续画loss曲线提供数据
test_acc = [] # 将每轮的acc记录在此列表中,为后续画acc曲线提供数据
epoch = 500 # 循环500轮
loss_all = 0 # 每轮分4个step,loss_all记录四个step生成的4个loss的和
# 训练部分
for epoch in range(epoch): # 数据集级别的循环,每个epoch循环一次数据集
for step, (x_train, y_train) in enumerate(train_db): # batch级别的循环 ,每个step循环一个batch
with tf.GradientTape() as tape: # with结构记录梯度信息
y = tf.matmul(x_train, w1) + b1 # 神经网络乘加运算,b1加到x_train*w1结果矩阵的每一行
y = tf.nn.softmax(y) # 使输出y符合概率分布(此操作后与独热码同量级,可相减求loss),y的大小为32行,3列
y_ = tf.one_hot(y_train, depth=3) # 将标签值转换为独热码格式(32行,3列),方便计算loss和accuracy
loss = tf.reduce_mean(tf.square(y_ - y)) # 采用均方误差损失函数mse = mean(sum(y-out)^2)
loss_all += loss.numpy() # 将每个step计算出的loss累加,为后续求loss平均值提供数据,这样计算的loss更准确
# 计算loss对各个参数的梯度
grads = tape.gradient(loss, [w1, b1])
# 实现梯度更新 w1 = w1 - lr * w1_grad b = b - lr * b_grad
w1.assign_sub(lr * grads[0]) # 参数w1自更新
b1.assign_sub(lr * grads[1]) # 参数b自更新
# 每个epoch,打印loss信息
print("Epoch {}, loss: {}".format(epoch, loss_all / 4))
train_loss_results.append(loss_all / 4) # 将4个step的loss求平均记录在此变量中
loss_all = 0 # loss_all归零,为记录下一个epoch的loss做准备
# 测试部分
# total_correct为预测对的样本个数, total_number为测试的总样本数,将这两个变量都初始化为0
total_correct, total_number = 0, 0
temp = 0
for x_test, y_test in test_db:
temp += 1
print("temp:", temp)
# 使用更新后的参数进行预测
y = tf.matmul(x_test, w1) + b1
y = tf.nn.softmax(y)
pred = tf.argmax(y, axis=1) # 返回y中最大值的索引,即预测的分类
print("pred.shape", pred.shape)
# 将pred转换为y_test的数据类型
pred = tf.cast(pred, dtype=y_test.dtype)
# 若分类正确,则correct=1,否则为0,将bool型的结果转换为int型
correct = tf.cast(tf.equal(pred, y_test), dtype=tf.int32)
# 将每个batch的correct数加起来
correct = tf.reduce_sum(correct)
# 将所有batch中的correct数加起来
total_correct += int(correct)
# total_number为测试的总样本数,也就是x_test的行数,shape[0]返回变量的行数
total_number += x_test.shape[0]
# 总的准确率等于total_correct/total_number
acc = total_correct / total_number
test_acc.append(acc)
print("Test_acc:", acc)
print("--------------------------")
# 绘制 loss 曲线
plt.title('Loss Function Curve') # 图片标题
plt.xlabel('Epoch') # x轴变量名称
plt.ylabel('Loss') # y轴变量名称
plt.plot(train_loss_results, label="$Loss$") # 逐点画出trian_loss_results值并连线,连线图标是Loss
plt.legend() # 画出曲线图标
plt.show() # 画出图像
# 绘制 Accuracy 曲线
plt.title('Acc Curve') # 图片标题
plt.xlabel('Epoch') # x轴变量名称
plt.ylabel('Acc') # y轴变量名称
plt.plot(test_acc, label="$Accuracy$") # 逐点画出test_acc值并连线,连线图标是Accuracy
plt.legend()
plt.show()
程序不难分析,只要抓住各数据的结构就很容易分析清楚,重要数据的结构已经标注在注释里了。关于独热码,通常是对训练集的标签使用的,能够把分类问题如三分类问题的标签变为一个一行三列数组,其中只有一个一,举个例子:
现有一个训练集的标签向量:[0,1,2,2,1,1],变换为独热码后为:
[1 0 0
0 1 0
0 0 1
0 0 1
0 1 0
0 1 0 ]
变成了6行3列的矩阵,训练集特征数据是6行4列,权重系数为4行3列,相乘后为6行3列,与标签的独热码矩阵大小一致,可以直接相减求误差。
程序中的softmax函数作用如下:在训练集特征数据(6行4列)与权重系数(4行3列)相乘得到的矩阵是一个数值矩阵,数值可以大于一,此时我们可以做一次变换,把所有数值转换为一个概率,转换公式为:

参考:北京大学《人工智能实践-Tensorflow笔记》课程
注:本例子未使用激活函数,未使用正则化,无优化器,使用的是最简单的梯度下降法