详解分布式共识(一致性)算法Raft
分布式共识及Raft简介
所谓分布式共识(consensus),与CAP理论中的一致性(consistency)其实是异曲同工,就是在分布式系统中,所有节点对同一份数据的认知能够达成一致。保证集群共识的算法就叫共识算法,它与一致性协议这个词也经常互相通用。
当今最著名的共识算法就是Paxos算法。它由Leslie Lamport在1990年提出,很长时间以来都是一致性的事实标准。但是它有两个不小的缺点:难以理解和证明,难以在实际工程中实现。Google Chubby的工程师就曾有以下的评论:
There are significant gaps between the description of the Paxos algorithm and the needs of a real-world system... the final system will be based on an unproven protocol.
于是2014年,来自斯坦福的两位大佬Diego Ongaro与John Ousterhout通过论文《In Search of an Understandable Consensus Algorithm》提出了一个新的共识算法Raft。从题目就可以看出,Raft的特点就是容易理解,在此基础上也容易实现,因此在real world中,它的应用也比Paxos要广泛,比较有名的如etcd、Kudu等。
Raft为了达到易懂易用的目标,主要做了两件事:一是分解问题(decomposition),即将复杂的分布式共识问题拆分为领导选举(leader election)、日志复制(log replication)和安全性(safety)三个子问题,并分别解决;二是压缩状态空间(state space reduction),相对于Paxos算法而言施加了更合理的限制,减少因为系统状态过多而产生的不确定性。
下面先简要介绍共识算法的基础——复制状态机,然后就来按顺序研究Raft是如何解决三个子问题的。
复制状态机
在共识算法中,所有服务器节点都会包含一个有限状态自动机,名为复制状态机(replicated state machine)。每个节点都维护着一个复制日志(replicated logs)的队列,复制状态机会按序输入并执行该队列中的请求,执行状态转换并输出结果。可见,如果能保证各个节点中日志的一致性,那么所有节点状态机的状态转换和输出也就都一致。共识算法就是为了保障这种一致性的,下图示出简单的复制状态机及其相关架构。
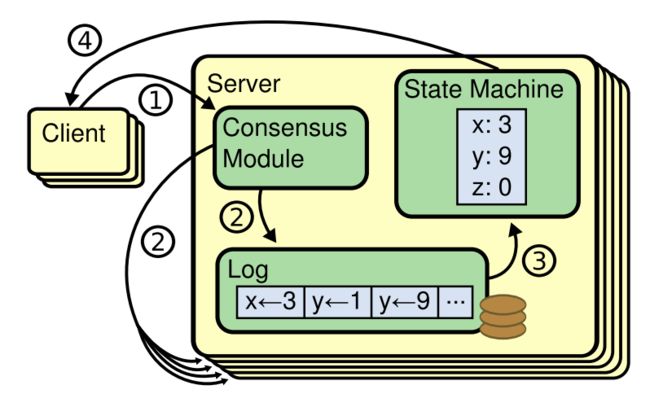
- 某个节点的共识模块(包含共识算法的实现)从客户端接收请求。
- 该共识模块将请求写入自身的日志队列,并与其他节点的共识模块交流,保证每个节点日志都相同。
- 复制状态机处理日志中的请求。
- 将输出结果返回给客户端。
领导选举
节点状态与转移规则
根据分布式系统的Quorum机制与NRW算法,集群中半数以上节点可用时,就能正确处理分布式事务,因此Raft集群几乎都使用奇数节点,可以防止脑裂并避免浪费资源。采用ZAB协议的ZooKeeper集群也是如此。
在Raft集群中,任意节点同一时刻只能处于领导者(leader)、跟随者(follower)、候选者(candidate)三种状态之一。下图示出节点状态的转移规则。
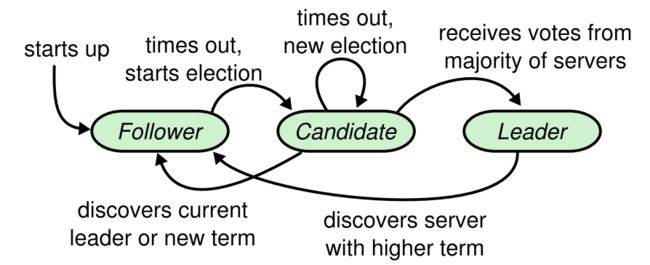
可见,集群建立时所有节点都是跟随节点。如果在一定时间过后发现没有领导节点,就会切换到候选状态,发起选举。得到多数票的候选者就会成为领导节点。如果候选节点或当前领导节点发现了更新的领导者,就会主动退回跟随状态。
领导节点全权负责管理复制日志,也就是从客户端接收请求,复制到跟随节点,并告诉跟随节点何时可以处理这些请求。如果领导节点故障或断开连接,就会重新进行选举。可见,领导节点的存在大大简化了共识算法的设计。
领导任期
在上面的图中出现了任期(term)这个词。领导者并不是一直“在位”的,工作一段时间之后,就会选举出新的领导者来接替它。

由上图可见,蓝色表示选举时间段,绿色表示选举出的领导者在位的时间段,这两者合起来即称作一个任期,其计数值是自增的。任期的值就可以在逻辑上充当时间戳,每个节点都会保存一份自己所见的最新任期值,称为currentTerm。另外,如果因为票数相同,没能选出领导,就会立即再发起新的选举。
选举流程
如果一个或多个跟随节点在选举超时(election timeout)内没有收到领导节点的心跳(一个名为AppendEntries的RPC消息,本意是做日志复制用途,但此时不携带日志数据),就会发起选举流程:
- 增加本地的currentTerm值;
- 将自己切换到候选状态;
- 给自己投一票;
- 给其他节点发送名为RequestVote的RPC消息,请求投票;
- 等待其他节点的消息。
根据其他节点回复的消息,会出现如下三种结果:
- 收到多数节点的投票,赢得选举,成为领导节点;
- 收到其他当选节点发来的AppendEntries消息,转换回跟随节点;
- 选举超时后没收到多数票,也没有其他节点当选,就保持候选状态重新选举。
获得多数票的节点只要当选,就会立即给其他所有节点发送AppendEntries,避免再次选举。另外,在同一任期内,每个节点只能投一票,并且先到先得(first-come-first-served),也就是会把票投给RequestVote消息第一个到达的那个节点。
至于上面的第三种情况,也就是所谓“split vote”现象,容易在很多跟随者变成候选者时出现,因为没有节点能得到多数票,选举有可能无限继续下去。所以,Raft设置的选举超时并不是完全一样的,而是有些许随机性,来尽量使得投票能够集中到那些较“快”的节点上。
日志复制
日志格式
领导节点选举出来后,集群就可以开始处理客户端请求了。前面已经说过,每个节点都维护着一个复制日志的队列,它们的格式如下图所示。

可见,日志由一个个按序排列的entry组成。每个entry内包含有请求的数据,还有该entry产生时的领导任期值。在论文中,每个节点上的日志队列用一个数组log[]表示。
复制流程
当客户端发来请求时,领导节点首先将其加入自己的日志队列,再并行地发送AppendEntries RPC消息给所有跟随节点。领导节点收到来自多数跟随者的回复之后,就认为该请求可以提交了(见图中的commited entries)。然后,领导节点将请求应用(apply)到复制状态机,并通知跟随节点也这样做。这两步做完后,就不会再回滚。
这种从提交到应用的方式与最基础的一致性协议——两阶段提交(2PC)有些相似,但Raft只需要多数节点的确认,并不需要全部节点都可用。
注意在上图中,领导节点和4个跟随节点的日志并不完全相同,这可能是由于跟随节点反应慢、网络状况差等原因。领导节点会不断地重试发送AppendEntries,直到所有节点上的日志达到最终一致,而不实现强一致性。这就是CAP理论中在保证P的情况下,C与A无法兼得的体现。
日志复制的过程仍然遗留了一个问题:如果领导或者跟随节点发生异常情况而崩溃,如何保证日志的最终一致性?它属于下面的安全性问题中的一部分,稍后会解答它。
安全性
安全性是施加在领导选举、日志复制两个解决方案上的约束,用于保证在异常情况下Raft算法仍然有效,不能破坏一致性,也不能返回错误的结果。所有分布式算法都应保障安全性,在其基础上再保证活性(liveness)。
Raft协议的安全性保障有5种,分别是:选举安全性(election safety)、领导者只追加(leader append-only)、日志匹配(log matching)、领导者完全性(leader completeness)、状态机安全性(state machine safety) 。下面分别来看。
选举安全性
选举安全性是指每个任期内只允许选出最多一个领导。如果集群中有多于一个领导,就发生了脑裂(split brain)。根据“领导选举”一节中的描述,Raft能够保证选举安全,因为:
- 在同一任期内,每个节点只能投一票;
- 只有获得多数票的节点才能成为领导。
领导者只追加
在讲解日志复制时,我们可以明显地看出,客户端发出的请求都是插入领导者日志队列的尾部,没有修改或删除的操作。这样可以使领导者的行为尽量简单化,使之没有任何不确定的行为,同时也作为下一节要说的日志匹配的基础。
日志匹配
日志匹配的具体描述如下。
如果两个节点的日志队列中,两个entry具有相同的下标和任期值,那么:
- 它们携带的客户端请求相同;
- 它们之前的所有entry也都相同。
第一点自然由上一节的“领导者只追加”特性来保证,而第二点则由AppendEntries RPC消息的一个简单机制来保证:每条AppendEntries都会包含最新entry之前那个entry的下标与任期值,如果跟随节点在对应下标找不到对应任期的日志,就会拒绝接受并告知领导节点。
有了日志匹配特性,就可以解决日志复制中那个遗留问题了。假设由于节点崩溃,跟随节点的日志出现了多种异常情况,如下图。
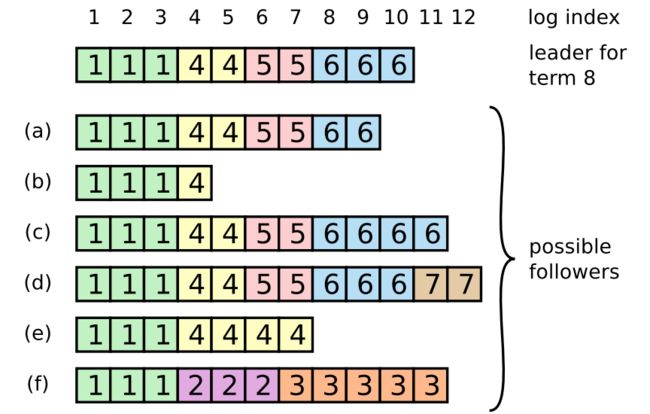
注意图中不是6个跟随节点,而是6种可能的情况。比如a和b是丢失了entry,c和d是有多余的未提交entry,e和f则是既有丢失又有冗余。这时领导节点就会找到两个日志队列中最近一条匹配的日志点,将该点之后跟随节点的所有日志都删除,然后将自己的这部分日志复制给它。例如对于上图中的情况e来说,最近一条匹配的日志下标为5,那么5之后的所有entry都会被删除,被替换成领导者的日志。
领导者完全性
领导者完全性是指,如果有一条日志在某个任期被提交了,那么它一定会出现在所有任期更大的领导者日志里。这也是由两点来决定的:
- 日志提交的定义:该条日志被成功复制到多数节点才算是提交;
- 选举投票的附加限制:只有当节点A的日志比节点B的日志更新时,B才可能会投票给A。也就是说,如果一个候选节点没有包含所有被提交的日志,那么它一定不会被选举为领导。
根据这两个描述,每次选举出的领导节点一定包含有最新的日志,因此只存在跟随节点从领导节点更新日志的情况,而不会反过来,这也使得一致性逻辑更加简化,并且为下面的状态机安全性提供保证。
状态机安全性
状态机安全性是说,如果一个节点已经向其复制状态机应用了一条日志中的请求,那么对于其他节点的同一下标的日志,不能应用不同的请求。这句话就很拗口了,因此我们来看一种意外的情况。

- 在时刻a,节点S1是领导者,第2个任期的日志只复制给了S2就崩溃了。
- 在时刻b,S5被选举为领导者,第3个任期的日志还没来得及复制,也崩溃了。
- 在时刻c,S1又被选举为领导者,继续复制日志,将任期2的日志给了S3。此时该日志复制给了多数节点,已经提交。
- 在时刻d,S1又崩溃,并且S5重新被选举为领导者,将任期3的日志复制给S0~S4。
这里就有问题了,在时刻c已经提交(甚至已经应用)的日志与新领导者的日志发生了冲突,此时状态机是不安全的。
为了解决该问题,Raft不允许领导者在当选后提交“前任”的日志,而是通过日志匹配原则,在处理“现任”日志时将之前的日志一同提交。具体方法是:在领导者任期开始时,立刻提交一条空的日志,所以上图中时刻c的情况不会发生,而是像时刻e一样先提交任期4的日志,连带提交任期2的日志。就算此时S1再崩溃,S5也不会重新被选举了。
The End
如果想要更直观地理解Raft,建议参考这里,是一个用动画来描述该算法的网页,形象生动。