简单易学多维数据可视化R实现:神奇的卡通脸谱图Chernoff faces
Chernoff face是由美国统计学家Chernoff在1976年率先提出的,用脸谱来分析多维度数据,即将P个维度的数据用人脸部位的形状或大小来表征。
他首先将该方法用于聚类分析,引起了各国统计学家的极大兴趣,并对他的画法作出了改进,一些统计软件也收入了脸谱图分析法,国内也有很多研究工作者将该方法应用于多元统计分析中。
脸谱图分析法的基本思想是由15-18个指标决定脸部特征,若实际资料变量更多将被忽略,若实际资料变量较少则脸部有些特征将被自动固定。统计学曾给出了几种不同的脸谱图的画法,而对于同一种脸谱图的画法,将变量次序重新排列,得到的脸谱的形状也会有很大不同。
按照切尔诺夫于1973年提出的画法,采用15个指标,各指标代表的面部特征为:
1表示脸的范围
2表示脸的形状
3表示鼻子的长度
4表示嘴的位置
5表示笑容曲线
6表示嘴的宽度
7—11分别表示眼睛的位置,分开程度,角度,形状和宽度
12表示瞳孔的位置
13—15分别表示眼眉的位置,角度及宽度。
这样,按照各变量的取值,根据一定的数学函数关系,就可以确定脸的轮廓、形状及五官的部位、形状,每一个样本点都用一张脸谱来表示。
脸谱容易给人们留下较为深刻的印象,通过对脸谱的分析,就可以直观地对原始资料进行归类或比较研究。
由于Chernoff脸谱图能形象地在平面上表示多维度数据并给人以直观的印象,可帮助使用者形象记忆分析结果,提高判断能力,加快分析速度。目前已应用于多地域经济战略指标数据分析,空间数据可视化等领域。
在R软件中,用aplpack包中的faces()函数作脸谱图,具体函数参数如下:
faces(xy,which.row,fill=FALSE,nrow,ncol,scale = TRUE,byrow =FALSE,main,labels)
下面是2008年美国各州的犯罪率部分统计数据在R中实现Chernoff 脸谱图过程:
-
下载R,安装aplpack软件包
In[1]:install.packages("aplpack")
2. 获取数据
Flowingdata网站中数据集有清洗过的2008年美国各州的犯罪率部分统计。可以在http://datasets.flowingdata.com/crimeRatesByState-formatted.csv中找到,我们没有必要下载它,可以通过URL在R中直接调用read.csv()函数直接下载数据。
In[2]:crime<-read.csv("http://datasets.flowingdata.com/crimeRatesByState-formatted.csv")
3.查看数据,在控制台键入
In[3]:crime[1:6,]
将显示数据集的前6行数据:
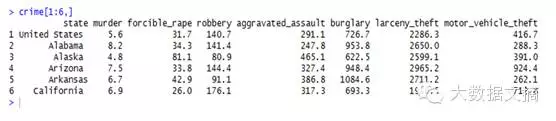
记住,数据集总共有8列,第一列是州的名字,其余的列为7中类型的犯罪。
4. 制作脸谱图
一旦有了数据,使用aplpack包的faces()函数可以很容易地制作。首先,加载软件包:
Library(aplpack)
如果在加载过程中,出现错误,需要检查你安装的是否正确。
脸谱图:
In[4]:Windows()
Faces(crime[,2:8])

Windows()新建一个图形窗口,faces(crime[,2:8])用数据集的第2至8列变量来画脸谱,
其中:
murder(谋杀)类型的变量表示脸高,眼宽,耳朵高度;
forcible_rape(强奸)类型变量表示脸宽,头发高度;
robbery(抢劫)类型变量表示脸的结构,头发宽度;
aggravated_assault(恶意攻击)类型变量表示嘴巴高度,头发发型;
burglary(夜盗)类型变量表示嘴宽,鼻子高度;
larceny_theft(盗窃)类型变量表示微笑,鼻子宽度;
motor_vehicle_theft(机动车辆盗窃)变量表示眼宽,耳朵宽度。

5. 变换特征
观察上面的脸谱图,52张脸代表52个州,每张脸表示了每个州的7种犯罪类型,可以很容易地发现第3,10张明显地与其他脸不同,说明第3,10个州与其他州的犯罪类型明显不同。
但是在上面的脸谱图中还需要做一些改变:
-
这些脸是用数字标签的,如果没有关键字没有多大用,所以需要用州的名字进行标签;
2.有些脸是带有微笑的,对于积极的数据集,比如生活质量或棒球统计,微笑是有意义的,值越高越好,而对于犯罪数据,犯盗窃罪微笑是不符合常理的,值越高越差。
不巧的是,R中face()函数并不允许我们自己选择每个变量关联的人脸部分,我们需要找到一个解决办法,根据帮助文件(在R控制台键入?faces),在这个案例中微笑的曲线被用在输入矩阵的第6列中。将数据集的第6列填充相同的值0,即所有的曲线是中性的
In[5]:Crime_filled<-cbind(crime[,1:5],rep(0,length(crime$state)),crime[,7:8])
cbind()函数联合多个列形成一个矩阵,上面将犯罪数据集的第6列置为0,其余不变,并重新赋值给crime_filled变量,查看crime_filled前6行:
In[6]:Crime_filled[1:6,]

注意,新的数据集中有1列数据的值都为0。
对crime_filled矩阵使用faces()函数
In[7]:windows()
faces(crime_filled[,2:8])

可以得到类似的脸,但是没有笑脸:

6.添加标签
用州的名字替换数字来标签每张脸谱:
In[8]:faces(crime_filled[,2:8],labels=crime_filled$state)

Label参数设置为crime_filled数据集的州列

可以很容易地将每张脸与对应的州关联起来。怎么样,还不错吧!仔细阅读R中faces()帮助文件,还可以根据其它功能画出不同效果图。比如,头像可以以圣诞老人为模。
In[9]windows()
a<-faces(crime_filled[,2:8],labels=crime_filled$state,face.type=2)
哇哦,世界上竟然有如此浪漫的统计学家!如此简单易学,只需要一组多维数据、一个faces()函数,就可以轻松搞定Chernoff脸谱。
总之,Chernoff脸谱是一种有趣的数据呈现方法,它可以把多元数据用二维的人脸的方式整体表现出来。各类数据变量经过编码后,转变为脸型,眉毛,眼睛,鼻子,嘴,下巴等面部特征,数据整体就是一张表情各异的人脸。面对错综复杂的信息时,人们会自动过滤掉无用信息,保留有用信息。人脑通常可以察觉到一些非常细微甚至难于测量的变化,然后对其做出反应,同时,人脑区分脸谱时,这种优越性更加明显,因为无论是脸的胖瘦,还是五官的大小位置,都极易给人留下深刻的印象,因而易于区别。
转载自 http://mp.weixin.qq.com/s?__biz=MjM5MTQzNzU2NA==&mid=209354629&idx=2&sn=08bb45632ab35fd12dec18879f45a159&scene=23&srcid=0929iIE7hWYGz3JpPNcdQTjk#rd