如何不写 SQL ,探索和分析数据库?
王树义
读完需要
17
分钟速读仅需 6 分钟
数据分析的门槛在降低,希望你能及时意识到。

1
需求
今天是本学期《数据库系统原理》的最后一课。学生们完成了数据分析项目,依次上台做展示。

看到连计算机扫盲课都没有上过的文科生,经过一个学期的学习,能够自己从网上找数据,导入关系型数据库,用 SQL 来做查询,直到以数据来回答自己感兴趣的问题,我觉得很开心。
在这个大数据时代,我们每个人的工作,都或多或少要跟数据打交道。小到记录自己的账本,大到用数据辅助企业战略决策。用好数据,可以帮助你所在的团队,和你个人增值。
有价值的数据,许多都存储在了各种数据库里面。想要使用好它们,只会用 Excel 或者 Access 是不够的。一般来说,查询它们的最好方式,是学会各种查询语言。最常见的,就是 SQL。
在著名的 Python 课程 Programming for Everybody 里面,主讲教授密歇根大学的 Chuck (Dr. Charles Severance) 认为,SQL 语言是编程语言中最简单的一种。
但是,我们还是现实一点。
许多时候,你有分析数据的冲动,然而并非人人都有时间和意愿去学一门 SQL 课程,来完成日常工作中的数据查询、分析和可视化工作。
2
工具
好在,技术的发展,总是把很多原先专业人士才能做的事儿,变成大众都能做的。
例如自动挡汽车,例如手机上的相机应用,再例如我今天要给你介绍的 Metabase 。
Metabase 的 Slogan ,是这个样子的。

翻译过来,重点就是:
所有人都能用
可以容易表达你的问题
使你能从数据中学习
3
安装
我们来尝试一下。
Metabase 这款工具,完全可以适用于团队协作,因为它提供了 Docker 镜像、AWS 和 Heroku 等方便的云端使用方式。
为了介绍的简单与方便,这里我只给你介绍一下单机版的安装。其余的应用形式,你可以学习本文之后,自己继续挖掘。
因为我自己使用的是 macOS ,所以这里选择 Mac 下面编译好的安装文件就行。
如果你使用的是其他系统,例如 Linux 或者 Windows ,安装也不麻烦。只需要点击“其他平台”按钮,下载一个 jar 类型文件。只要你在系统里面安装好 Java 运行环境,就可以直接双击该文件运行了。

这里以我电脑上的 macOS 系统为例。打开下载的 dmg 文件后,把可执行文件拖入到“应用”文件夹,就可以了。
 第一次运行的时候,可能需要一些时间初始化。
第一次运行的时候,可能需要一些时间初始化。
当出现以下界面的时候,就意味着准备就绪了。

请你点击上图里面的蓝色按钮,开始设置。
我们需要输入一些基本注册信息。

之后,选择我们需要连接的数据库。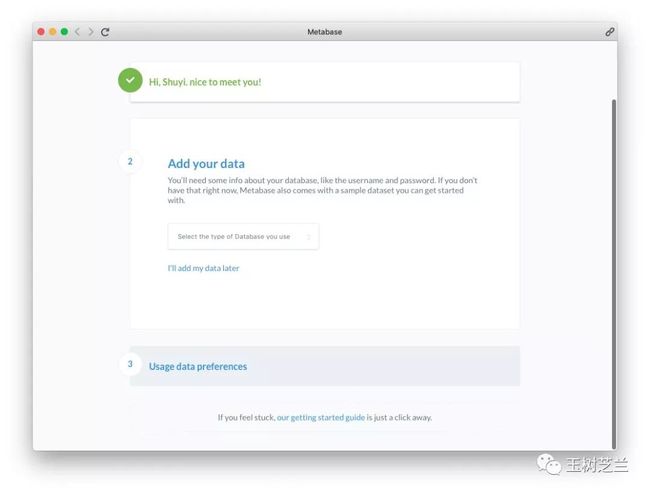
注意,这里有很多选项可以选择。这些选项,基本上涵盖了市面上常见的主流数据库类型。

为了方便起见,这里我们使用“麻雀虽小五脏俱全”的 SQLite 数据库。其他类型的数据库,你可以稍后自己尝试。
我用的样例,是 Stanford 数据库开放课程使用的 colleges.db 。我自己上课的时候,一直用它作为基础样例演示给学生。
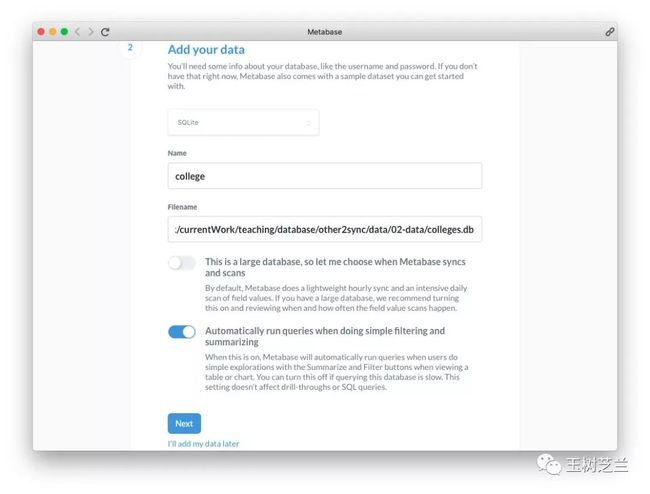
设置完毕之后,下面需要注意,有个数据统计选项。Metabase 是在询问你,是否允许把你的使用行为统计信息发给它,帮助改进。
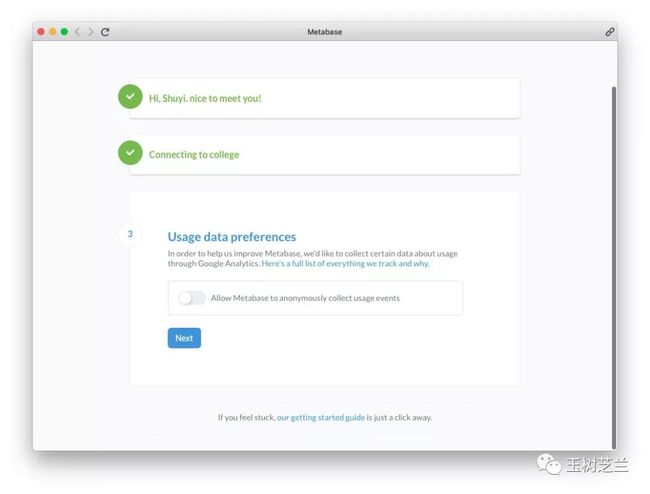
如果你乐于分享,可以保持原先设定。若对自己的隐私比较注重,不用纠结了,可以关闭该选项。
到这里,安装和设置就算完成了。
4
浏览
下面我们看看有哪些数据表可以查看。
这个数据库里面包含了3张表格,分别是:
Student 学生信息
Apply 申请信息
College 招生学校信息
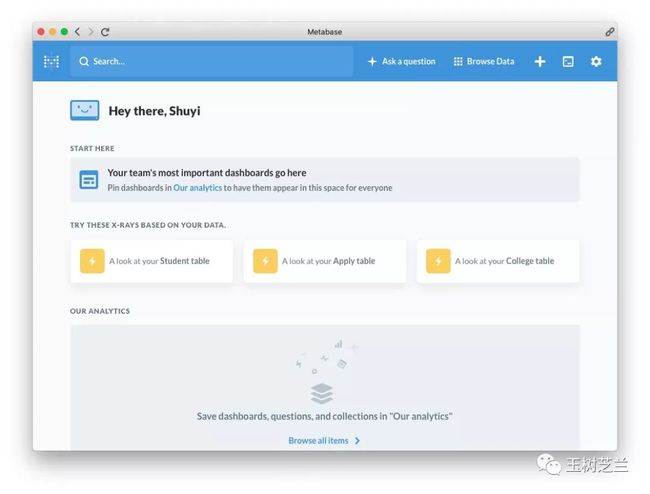
我们选择其中的学生表格。
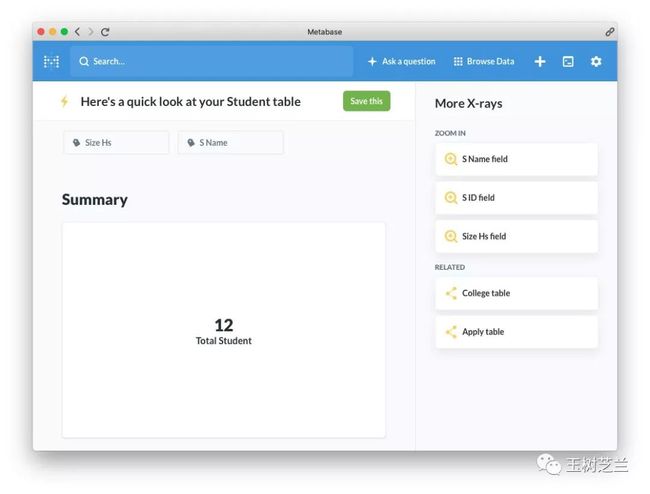
Metabase 默认给了我们一些基本的描述性统计结果。
例如最重要的,是一张表格到底有多少行。这里样例 Student 表里,一共有12个学生的记录。
还没完,往下翻, Metabase 还为我们自动生成了一些其他统计结果。
首先是学生的学号分布。
当然,由于学号无非是个独特数字而已,所以这个统计没有什么用处。
但下面这张,就不一样了。
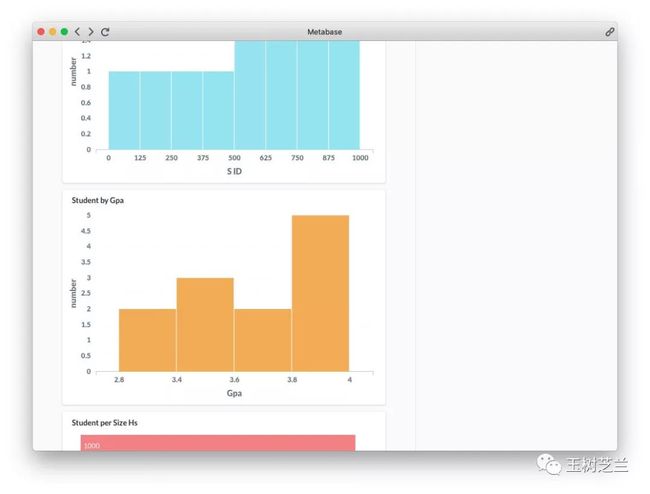
这是学生的 GPA 分布,可见,大部分学生的成绩高于 3.6 分。数据集不是个均匀或者正态分布。
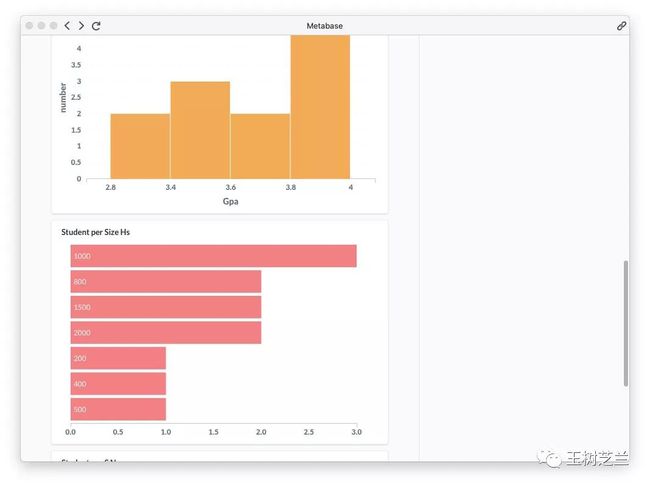
上面这张图,反映了学生来自的高中学校大小。看得出来,大部分学生还是来自于学生人数较多的学校。来自小而精的高中学生人数,相对较少。
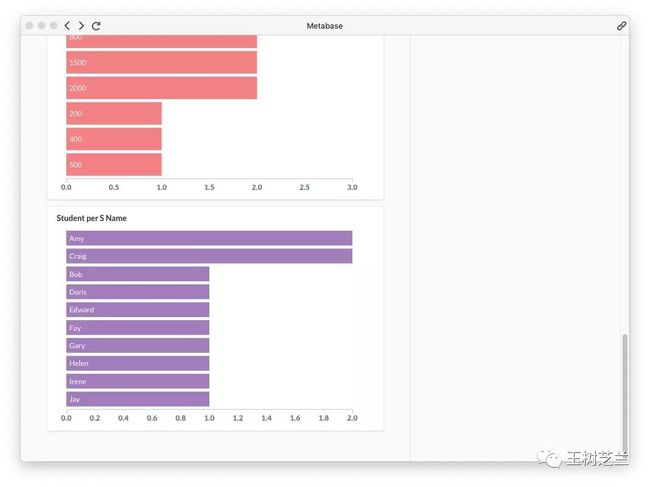
后面这张图,统计了学生姓名。有意思的是,你可以清楚看到,有重名的学生。
如果你不满足于只看这些统计信息,而希望查看原始数据。那么可以点击“Browse Data” 按钮,选择 college 数据库。
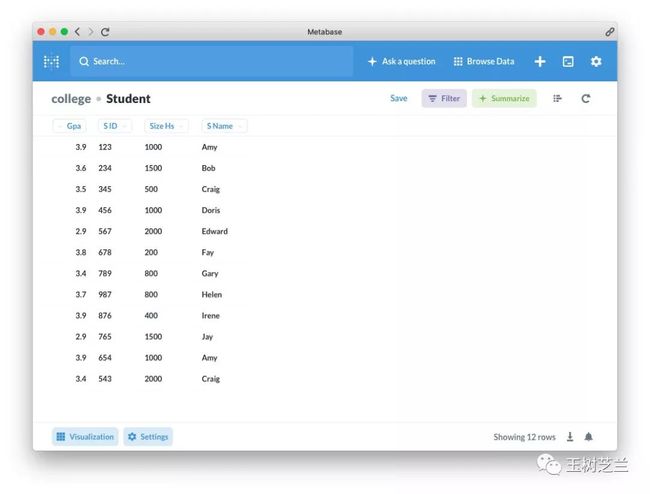
然后选择其中的 Student 表格,就能看到全部学生记录信息。
5
分析
如果我们只关注其中一部分学生的情况,可以选择上方紫色的“Filter”(过滤)按钮。
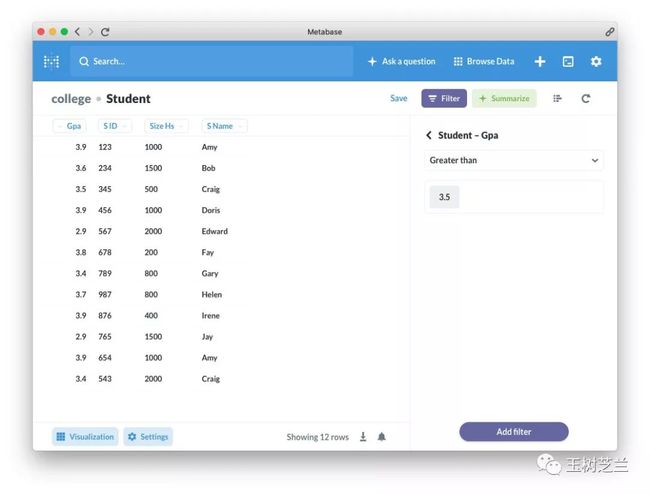 这里,所有的条件,都可以通过选择和输入数值来完成,不需要编程。我们选择过滤结果只保留 GPA 大于 3.5 的学生。
这里,所有的条件,都可以通过选择和输入数值来完成,不需要编程。我们选择过滤结果只保留 GPA 大于 3.5 的学生。
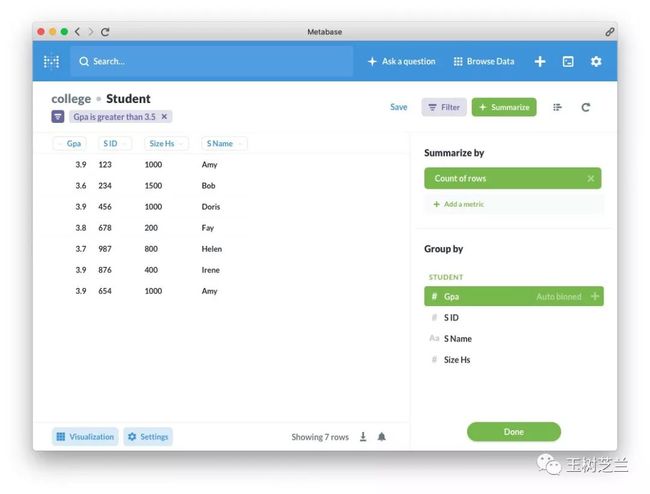
上图左侧就是我们想看的结果了。
但是我们会觉得,“一幅图胜似千言万语”。
怎么办呢?我们选择右下方,以 GPA 作为分组依据,然后点击左下方的 Visualization (可视化)按钮。
可见,在成绩大于3.5的学生里面,有4个是3.9分的成绩。这部分学生里面,学霸占的比例不小啊。
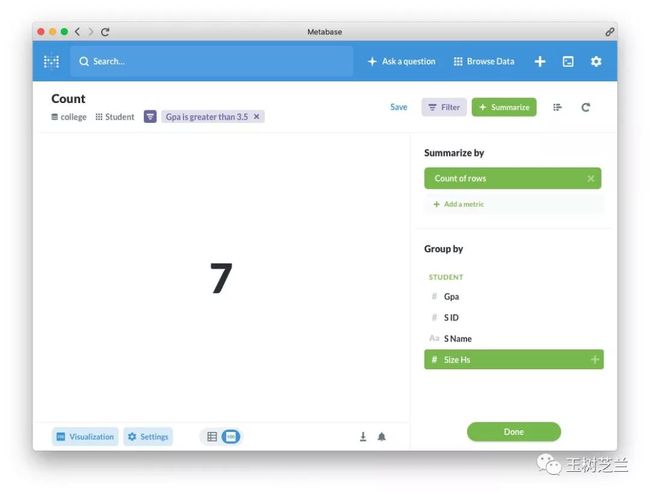
我们还可以换一种分组方式,这里我们使用高中学校人数作为分组依据。然后再次进行可视化。
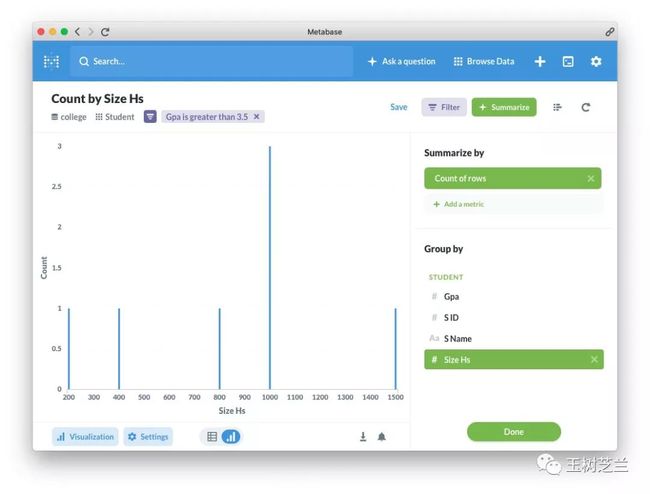
于是你可以看到,GPA 3.5 分以上的学生,来自于人数规模1000的高中最多。
点击可视化按钮,我们可以选择不同的图形来表示。
这里我们选择饼图。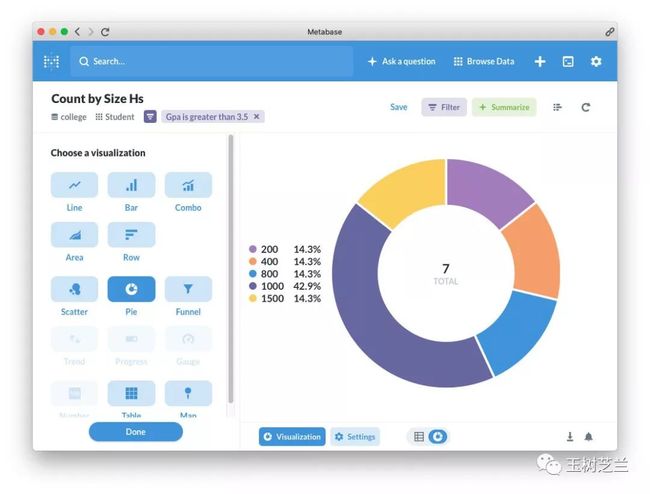
你觉得在这个问题里,柱状图和饼图,哪个更适合描述咱们的过滤分析结果呢?
6
地图
下面我们来看看,如何对数据进行地理信息可视化。也就是,画个地图出来。
这里,我们选用的,是其中 College 这张表格。
这张表格里面,包含以下信息。
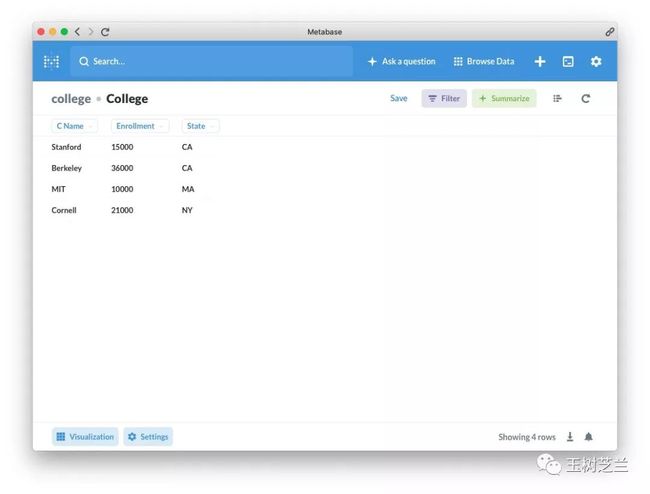
我们打算看看,不同州大学的录取人数。做法很简单。还是点击 Visualization 。
选择图形选项最右下方的“地图”(Map)。
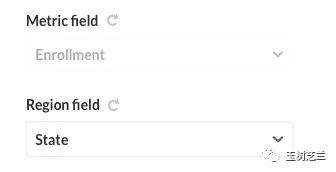
修改 Metric field 为 Enrollment 。然后 Region Field 为 State (州)。
于是你就能看见下面这样的地图了。
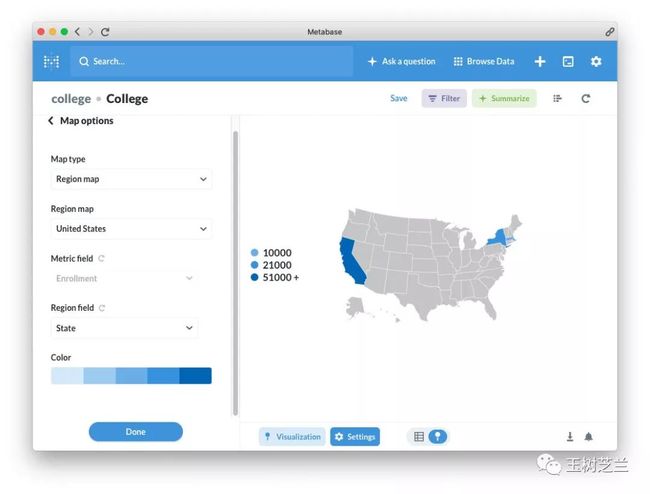
有意思的是,Metabase 对于州的简写方式也能正确识别,并且把它们标记在地图上。而且根据汇总招生人数的多寡,还自动选择了不同深浅的颜色。
7
关联
下面我们来看看更实用的分析手段——关联查询。
从一张表里,我们已经可以分析出不少东西了。但是更多情况下,我们希望采用多张表格联合在一起,从而能从中挖掘出洞见(Insights)。
例如这里我给你提一个问题:
不同大学录取最低 GPA 是多少?
这个问题,你若是只用一张表,是无非回答的。
因为 Apply 表里面虽然有录取决策信息,但是不包含 GPA;
Student 表里面虽然包括了 GPA,但你不知道学生报了哪所学校,以及是否被录取了。
让我们点击上方菜单栏里面的“问问题”(Ask a question)按钮,然后从下图中选择“定制问题”(Custom Question)。
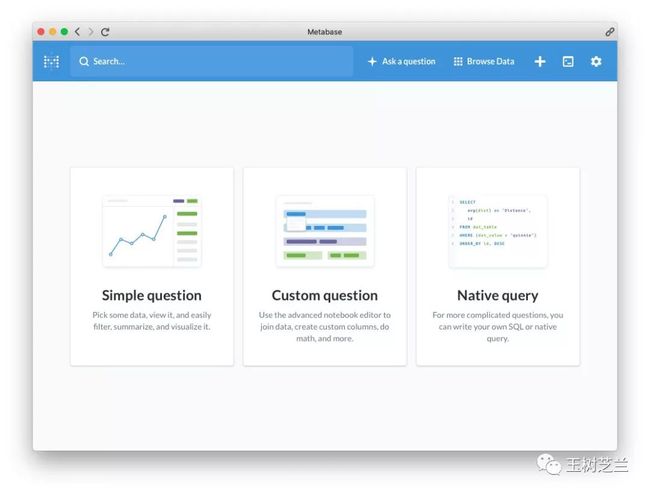
然后,你需要选择数据库。
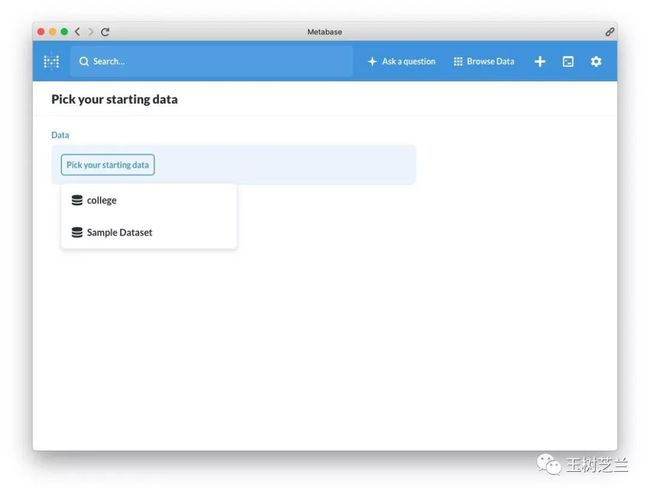
还得选择一个初始的表格。
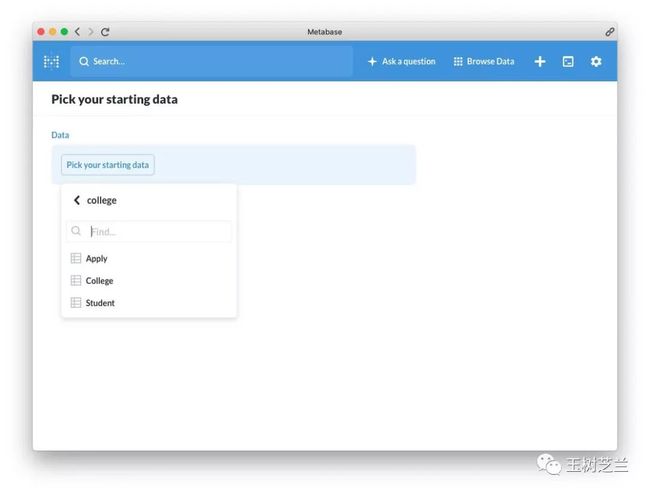 我们选择 Student 表。
我们选择 Student 表。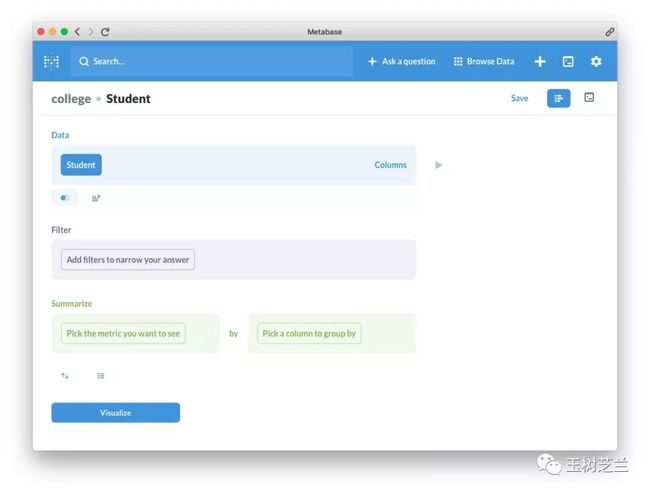 然后选择 Join data (关联数据)。
然后选择 Join data (关联数据)。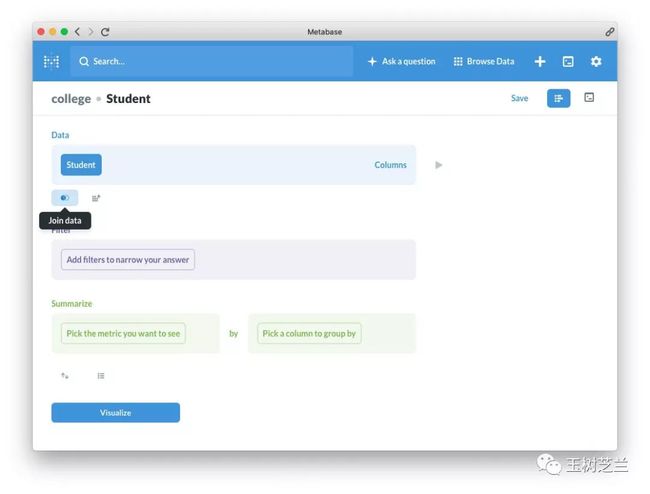
这里我们需要选择 Apply 表格。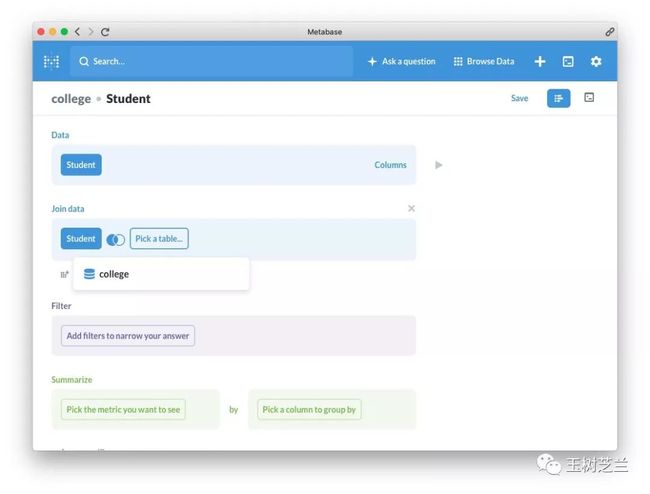 然后会让我们选择用哪个列进行关联。毕竟,如果我们把张三的学生信息关联到李四的录取信息记录上,是没有意义的。
然后会让我们选择用哪个列进行关联。毕竟,如果我们把张三的学生信息关联到李四的录取信息记录上,是没有意义的。 我们观察一下,发现在 Student 和 Apply 中,都出现了学生的 ID (sID),这是学生的唯一标识。就用它好了。
我们观察一下,发现在 Student 和 Apply 中,都出现了学生的 ID (sID),这是学生的唯一标识。就用它好了。
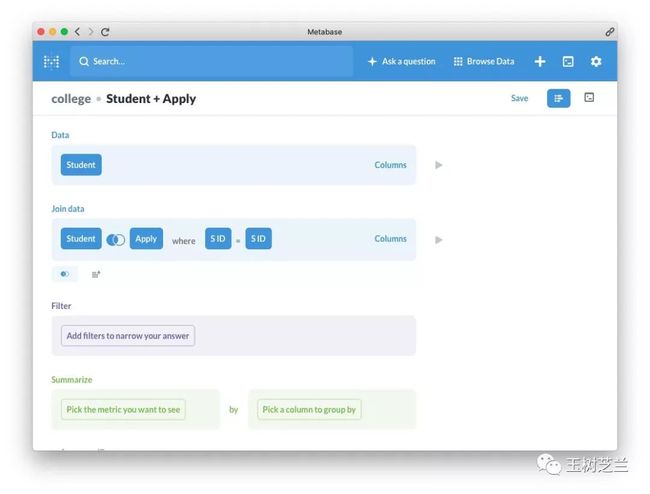
下面我们设置一下过滤条件。显然,既然考虑录取分数,那么就得找出那些被录取的人。
于是我们在 Filter 一栏里面点击。
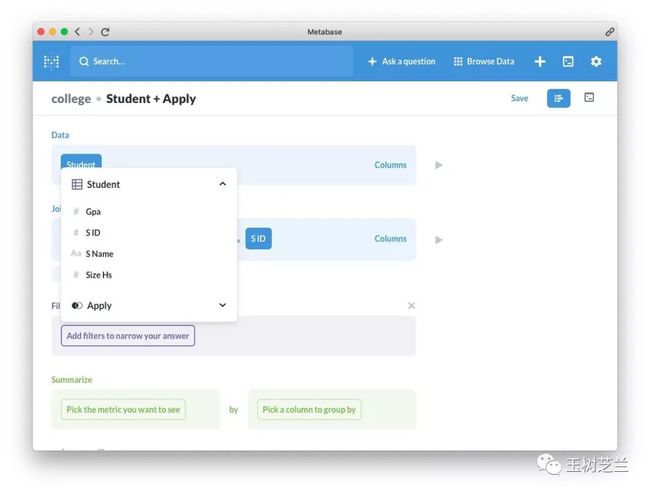
选择 Apply 表格。
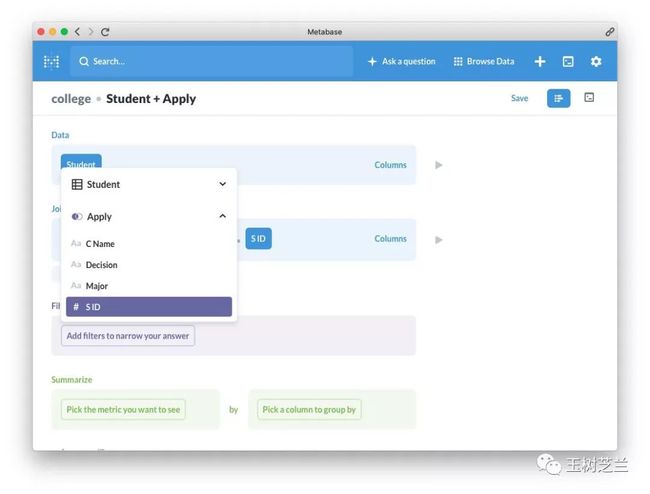 然后从中选择 Decision (录取决策)。
然后从中选择 Decision (录取决策)。
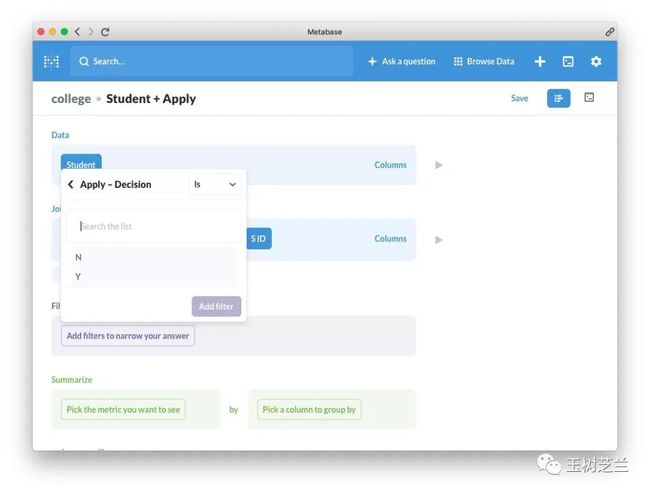 因为这里只有两种取值选择。所以我们可以选择 Y (录取)。
因为这里只有两种取值选择。所以我们可以选择 Y (录取)。
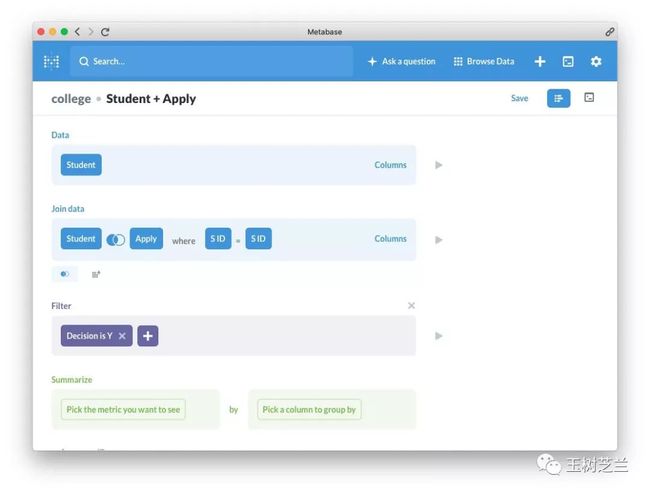
然后我们就可以根据学校来查看最低录取分数了。
这里我们填写绿色的 Summarize 。
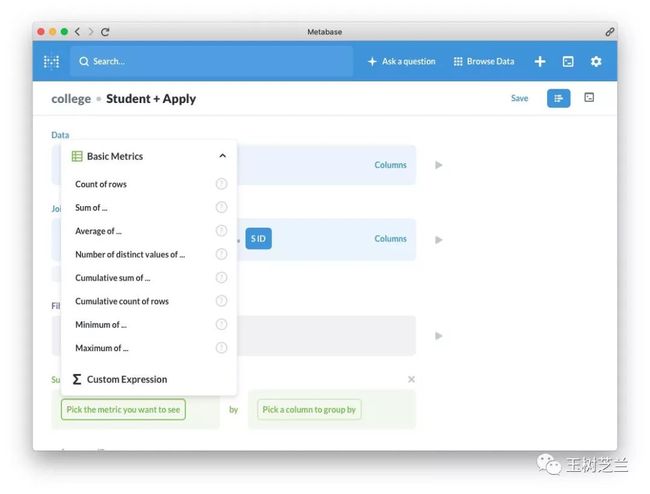 我们感兴趣的是最低录取分数,所以可以从中选择 Minimum of 。
我们感兴趣的是最低录取分数,所以可以从中选择 Minimum of 。
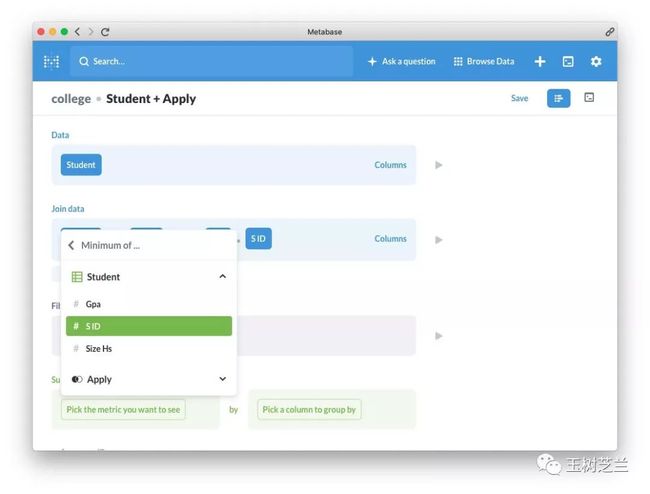 然后选择 GPA 作为最小值选择列。
然后选择 GPA 作为最小值选择列。
还没完。因为我们是需要按照学校来分别计算的。所以在 by 后面选择 cName 。
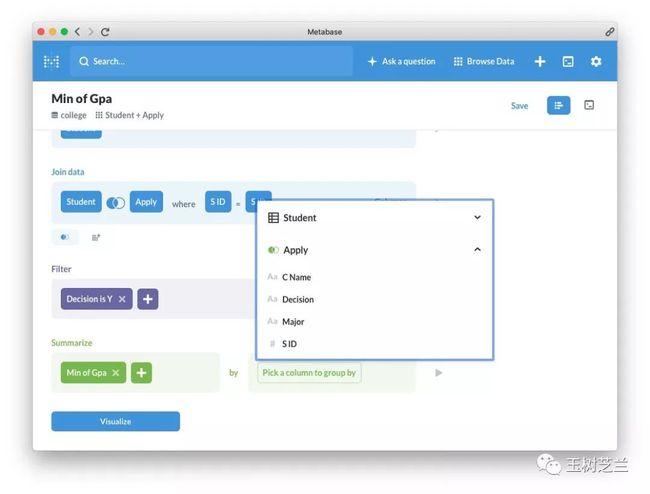
通过简单的点选,你现在已经有了所有需要设置的信息。
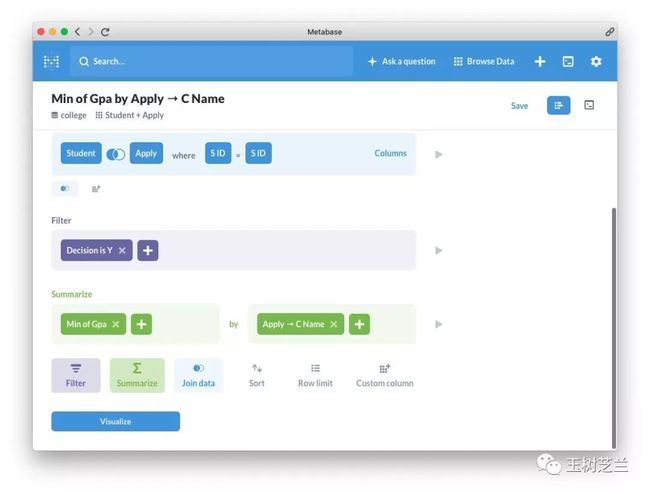
好,我们执行吧。选择 Visualize 。
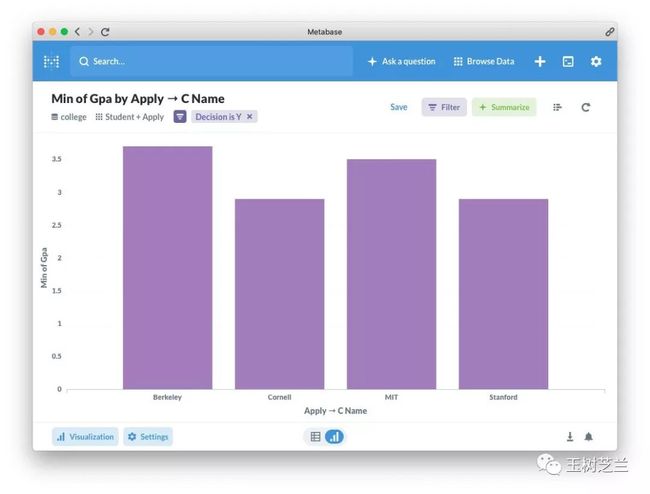
从这张图里,我们可以看到,Berkeley 录取学生的 GPA 线最高。Cornell 和 Stanford 并列最低。
由此看来,名校看重的,绝不仅仅是 GPA 成绩啊。
是吗?
这个作为思考题,欢迎你把自己的答案写在留言区里面和大家交流。
8
小结
本文我带你用一个极简的数据库样例,尝试了不写任何一句 SQL 代码,对数据库进行过滤、分析、统计、可视化,以及表间关联查询。
你可能会觉得,这么简单的数据,我拿眼看心算,都比你这方法快!
没错,但是想象一下,如果你的每张表里面,数据量都多上1000倍呢?
我们要学东西,就需要掌握这种能规模化应用的技能。虽然初始学习的时候觉得有些繁琐,但是真正帮你应对大规模数据结果的时候,你就能尝到掌握它的甜头了。
祝数据分析愉快!
感觉有用的话,请点“在看”,并且把它转发给你身边有需要的朋友。
赞赏就是力量。

由于微信公众号外部链接的限制,文中的部分链接可能无法正确打开。如有需要,请点击文末的“阅读原文”按钮,访问可以正常显示外链的版本。
订阅我的微信公众号“玉树芝兰”,第一时间免费收到文章更新。别忘了加星标,以免错过新推送提示。

如果你对 Python 与数据科学感兴趣,希望能与其他热爱学习的小伙伴一起讨论切磋,答疑解惑,欢迎加入知识星球。
延伸阅读
你可能也会对以下话题感兴趣。点击链接就可以查看。
如何把 Markdown 文件批量转换为 pdf?
如何用iPad运行Python代码?
如何用Sikuli自动录入成绩?
如何高效学 Python ?
《文科生数据科学上手指南》分享
题图:Photo by National Cancer Institute on Unsplash