Squeeze-and-ExcitationNetworks流程图及其原理解析
介绍一下这个SE-Block,作者利用它获得了最后一届imageNet的冠军
论文链接:
https://arxiv.org/abs/1709.01507
GitHub:
https://github.com/hujie-frank/SENet
论文翻译: https://blog.csdn.net/Quincuntial/article/details/78605463
论文解读:https://blog.csdn.net/xjz18298268521/article/details/79078551
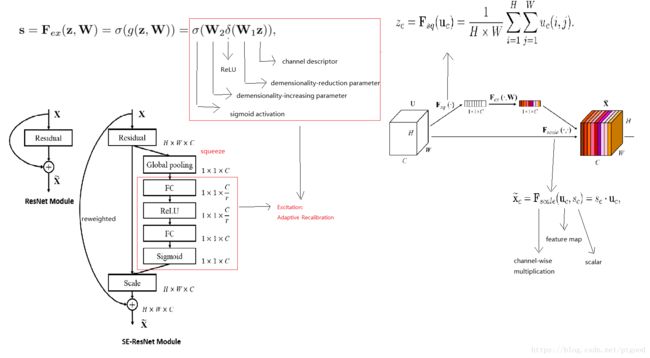
图中W1和W2是conv的权重
The use of the whole SE-block is to , quoted from the paper:through which it can learn to use global information to selectively emphasise informative features and suppress less useful one.
USAGE:the SE-Block can directly replace other network block in the architecture , in other words, quote from the paper: SE blocks can also be used as a drop-in replacement for the original block at any depth in the architecture.
The SE-block can be divided into two parts(desite the orignal block part):Squeeze and Excitations
The goal for Squeeze action: to exploit channel dependencies
How to squeeze:using global average pooling to generate channel-wise statistics,in other words,用global average pooling产生通道交互,as the details of squeeze are in the figure above.
The goal for Excitation operation :to fully capture channel-wise dependencies to make use of the information aggregated in the squeeze operation(利用好在squeeze操作中汇聚好的信息)
论文提到:activation作为适应input-specific feature descriptor 的channel weights。在这方面,SE-block本质上引入了以输入为条件的动态特性,helping to boost feature discriminability。这句话的意思...有待思考
The meaning behind the structure still remained to be found..
作者提到SE-block增强了网络的表征能力,by dynamic channel-wise feature重校准( recalibration),至于如何重校准(recalibration).把这个问题留到以后解决..
给以后留下的问题:每层网络这样干的原因..
=====================================================================================
分界线2019年2月2日16:30:59更新
在看网络对比时再次看到SE Net,重新审视了一下发现以前看过它,不过又忘了,重新解读下
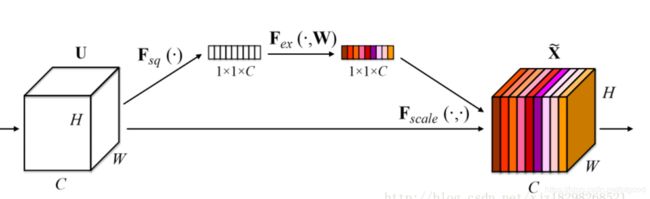 这个图片里,Fex(`,W)操作是:
这个图片里,Fex(`,W)操作是: 这个操作就是excitation(激励)操作
这个操作就是excitation(激励)操作
此操作,将1*1*C 降维成1*1*C/r再升维1*1*C,降维比例为r,降维方式:全连接层,或者说两个1*1conv层,为什么要exicitation:作者说是为了限制模型复杂度和辅助泛化。这样操作后估计1*1*C的结果会比原来更简单(限制模型复杂度),虽然过程更加复杂了(加入了W来降低和提高维度,有点像变分自编码器)
而F scale操作是将上面得到的“通道权重”与特征相乘
回答之前给自己留下的问题:每层网络这样干的原因..
首先,为什么要有这个SE-block方法的原因:文中写的是,或者说,普通的CNN的filter产生的feature map,都无法利用其它feature map的上下文信息,所以意思是这个方法能充分开发feature map 之间的有效关系咯;自己的想法是,其他的CNN网络不能解决feature map相互间的依赖性问题,他们都是独立的(猜想,等待以后验证),而这个SE-block可以解决这个问题,
如何充分开发feature map间信息呢,通过:通俗来讲,就是让网络利用全局信息有选择的增强有益feature通道并抑制无用feature通道,原文:【through which it can learn to use global information to selectively emphasise informative features and suppress less useful one. 】;自己的话来讲,就是通过引入入一个权重,权重大小代表feature map每个通道作用大小(feature map一层代表一个filter,相当于对那些filter加入权重参数);加入权重参数,应该引入怎样的参数呢,一个feature map名为INPUT,将它global average pooling,再进行于参数W有关的变换F excitation,变成一个与INPUT通道数相同的1*1tensor,每个通道对应一个权重,这个1*1tensor即是feature map INPUT的权重,而和参数W有关的变化excitation,实际是conv操作,conv的权重即为W,由训练所得(猜测,还没看原文)。
Squeeze操作:即SE-block里的global pooling(averge pooling)操作,将每个二特征通道变成一个实数,作用:使得每一个(1*1*C)feature map通道上的实数能代表那个通道里的整个图像范围,或者说,feature map对应的感受野提升到了全局(原本每个filter感受野只有局部)