Linux搭建Hive On Spark环境(spark-1.6.3-without-hive+hadoop2.8.0+hive2.1.1)
概述
1各个机器安装概况
2下载和解压缩各种包
3配置环境变量
4修改hostname文件
4.1在3台机器上执行hostname命令
4.2编辑hosts文件
5 Hadoop的安装和启动
5.1设置ssh免密码登录
5.2 创建一堆目录
5.3 对conf目录下的文件做配置
5.3.1修改core-site.xml
5.3.2修改hadoop-env.sh
5.3.3修改hdfs-site.xml
5.3.4新建并且修改mapred-site.xml
5.3.5修改slaves文件
5.3.6修改yarn-site.xml文件
5.4启动hadoop
6 Spark的安装和启动
6.1对conf目录下的文件做配置
6.1.1 新建spark-env.h文件
6.1.2 新建slaves文件
6.1.3新建spark-defaults.conf文件
6.2在HDFS上创建目录
6.3启动spark
7 Hive的配置和启动
7.1执行命令创建HDFS目录
7.2对conf目录下的配置文件进行配置
7.2.1新建hive-env.sh文件并进行修改
7.2.2对hive-site.xml文件进行配置
7.2.2.1目录相关的配置
7.2.2.2Mysql数据库相关的配置
7.2.2.3其他配置
7.3将MySQL驱动包上载到lib目录
7.4将Spark下的某些jar包拷贝到hive目录下
7.5对hive所要连接的数据库做初始化
7.6启动hive命令行窗口
7.7在hive中创建数据表
8对Hive On Spark环境做测试
8.1执行select count命令进行测试
8.2 在浏览器里访问spark的UI界面
关键字:Linux CentOS Java Scala Hive On Spark
版本号:CentOS7 JDK1.8 Scala2.11.8 Hive2.1.1 Spark-1.6.3-with-out-hive Hadoop2.8.0
概述
Hive默认的执行引擎是Hadoop提供的MapReduce,而MapReduce的缺点是读写磁盘太多,为了提高Hive执行某些SQL的效率,有必要将Hive的执行引擎替换为Spark,这就是Hive On Spark。不过Hive On Spark的环境搭建的确是有点麻烦,主要是因为Hive和Spark的版本不能随意搭配,首先Spark必须是without-hive版本才可以(编译时用特殊命令申明排除掉某些jar包)。要拥有这样的Spark的版本,你可以自己编译,但是要自己编译还得做很多准备工作,也是较为麻烦和费时的。其次拥有了without-hive版本的Spark,还得选择合适的Hive版本才可以,也就是说Hive和Spark必须使用恰当的版本,才能搭建Hive On Spark环境。
自己编译without-hive版本的Spark这里暂时不讲了,留在后面的博文中在说,本文先使用官方发布的without-hive版的Spark和官方发布的Hive版本来搭建Hive On Spark环境。
1 各个机器安装概况
3台机器是master、slave1、slave2,使用的操作系统是CentOS7(使用Ubuntu也可以,用为用的是压缩包,所以安装方法都一样),3台机器的信息如下表:
|
|
master |
slave1 |
slave2 |
| 内存 |
2G(越大越好) |
2G(越大越好) |
2G(越大越好) |
| IP地址 |
192.168.27.141 |
192.168.27.142 |
192.168.27.143 |
| 节点类型 |
Hadoop的namenode节点 Spark的master节点 |
Hadoop的datanode节点 Spark的slave节点 |
Hadoop的datanode节点 Spark的slave节点 |
| JAVA_HOME |
/opt/java/jdk1.8.0_121 |
/opt/java/jdk1.8.0_121 |
/opt/java/jdk1.8.0_121 |
| SCALA_HOME |
/opt/scala/scala-2.11.8 |
/opt/scala/scala-2.11.8 |
/opt/scala/scala-2.11.8 |
| HADOOP_HOME |
/opt/hadoop/hadoop-2.8.0 |
/opt/hadoop/hadoop-2.8.0 |
/opt/hadoop/hadoop-2.8.0 |
| SPARK_HOME |
/opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive |
/opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive |
opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive |
| HIVE_HOME |
/opt/hive/apache-hive-2.1.1-bin |
无需安装 |
无需安装 |
说明:在此强调一下,这里的Spark是spark-1.6.3-bin-hadoop2.4-without-hive而不是spark-1.6.3-bin-hadoop2.4,否则无法成功。Hadoop的版本倒是无所谓,用2.x基本上都可以的,我这里用的是2.8.0。
2 下载和解压缩各种包
3台机器分别需要安装什么东西,上面的表格已经很明确,下载、解压缩、配置即可,这里不详细讲怎么安装,只列出下载地址。
JDK的下载地址这里就不说了,Oracle这个流氓公司,还要求注册才能下载。
Scala-2.11.8的下载地址:
https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz
Hadoop-2.8.0下载地址:
http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
spark-1.6.3-bin-hadoop2.4-without-hive下载地址是:
http://mirror.bit.edu.cn/apache/spark/spark-1.6.3/spark-1.6.3-bin-hadoop2.4-without-hive.tgz
hive-2.1.1的下载地址是:
http://mirror.bit.edu.cn/apache/hive/stable-2/apache-hive-2.1.1-bin.tar.gz
JDK、SCALA、Hadoop、Spark、Hive的安装方法跟之前博文讲到的没什么不同,只是在Spark和Hive的配置上有一些不同,配置相关的东西,本博文下面会讲到,安装方法的话这里不细述了,有需要的可以参考下面列出的这些博文。
JDK安装参考(Ubuntu和CentOS都可以参考下面的博文):
http://blog.csdn.net/pucao_cug/article/details/68948639
Hadoop安装参考:
http://blog.csdn.net/pucao_cug/article/details/71698903
SCALA 和Spark的安装参考:
http://blog.csdn.net/pucao_cug/article/details/72353701
Hive的安装参考:
http://blog.csdn.net/pucao_cug/article/details/71773665
请分别按照上面提供的参考博文,将这几样东西都安装成功后,在参考下文提供的配置步骤来修改配置文件,然后运行Hive On Spark。
3 配置环境变量
编辑/etc/profile文件,编辑完成后执行source /etc/profile命令。
在master机器上添加:
export JAVA_HOME=/opt/java/jdk1.8.0_121
export SCALA_HOME=/opt/scala/scala-2.11.8
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export HIVE_HOME=/opt/hive/apache-hive-2.1.1-bin
export HIVE_CONF_DIR=${HIVE_HOME}/conf
export SPARK_HOME=/opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive
export CLASSPATH=.:${JAVA_HOME}/lib:${SCALA_HOME}/lib:${HIVE_HOME}/lib:$CLASSPATH
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${HIVE_HOME}/bin:$PATH在slave机器上添加:
export JAVA_HOME=/opt/java/jdk1.8.0_121
export SCALA_HOME=/opt/scala/scala-2.11.8
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export SPARK_HOME=/opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive
export CLASSPATH=.:${JAVA_HOME}/lib:${SCALA_HOME}/lib:${HIVE_HOME}/lib:$CLASSPATH
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:$PATH4 修改hostname文件
4.1 在3台机器上执行hostname命令
分别编辑3太机器上的/etc/houstname文件,
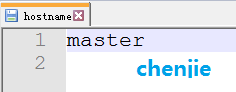
master机器上将该文件内容修改为master
如图:
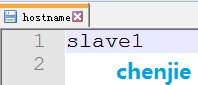
在slave1机器上修改为slave1:
如图:
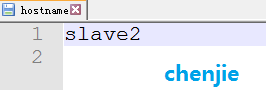
在slave2机器上修改为slave2:
如图:
4.2 编辑hosts文件
编辑/etc/hosts文件,3台机器的该文件中都添加如下配置:
192.168.27.141 master
192.168.27.142 slave1
192.168.27.143 slave25 Hadoop的安装和启动
搭建Hive OnSpark环境,并且不需要对Hadoop做特殊配置,如果已经参考上面提到的博文将Hadoop安装并且启动成功了,该章节可以跳过,直接看第6章。
5.1 设置ssh免密码登录
具体方法这里不细述了,如果有需要,请参考该博文的设置ssh免密码登录章节,博文是:
http://blog.csdn.net/pucao_cug/article/details/71698903
5.2 创建一堆目录
在master上执行命令创建目录的命令:
mkdir /root/hadoop
mkdir /root/hadoop/tmp
mkdir /root/hadoop/var
mkdir /root/hadoop/dfs
mkdir /root/hadoop/dfs/name
mkdir /root/hadoop/dfs/data在slave机器上执行创建目录的命令:
mkdir /root/hadoop
mkdir /root/hadoop/tmp
mkdir /root/hadoop/var
mkdir /root/hadoop/dfs
mkdir /root/hadoop/dfs/name
mkdir /root/hadoop/dfs/data5.3 对conf目录下的文件做配置
3台机器都一样,对/opt/hadoop/hadoop-2.8.0/etc/hadoop目录下的文件做如下配置。
5.3.1 修改core-site.xml
在
hadoop.tmp.dir
/root/hadoop/tmp
fs.default.name
hdfs://master:9000
5.3.2 修改hadoop-env.sh
将
export JAVA_HOME=${JAVA_HOME}修改为:
export JAVA_HOME=/opt/java/jdk1.8.0_121说明:修改为自己的JDK路径
5.3.3 修改hdfs-site.xml
在
dfs.name.dir
/root/hadoop/dfs/name
dfs.data.dir
/root/hadoop/dfs/data
dfs.replication
2
dfs.permissions
false
5.3.4 新建并且修改mapred-site.xml
在该版本中,有一个名为mapred-site.xml.template的文件,复制该文件,然后改名为mapred-site.xml,命令是:
cp /opt/hadoop/hadoop-2.8.0/etc/hadoop/mapred-site.xml.template /opt/hadoop/hadoop-2.8.0/etc/hadoop/mapred-site.xml 修改这个新建的mapred-site.xml文件,在
mapred.job.tracker
master:49001
mapred.local.dir
/root/hadoop/var
mapreduce.framework.name
yarn
5.3.5 修改slaves文件
将里面的localhost删除,添加如下内容:
slave1
slave25.3.6 修改yarn-site.xml文件
在
yarn.resourcemanager.hostname
master
yarn.resourcemanager.address
${yarn.resourcemanager.hostname}:8032
yarn.resourcemanager.scheduler.address
${yarn.resourcemanager.hostname}:8030
yarn.resourcemanager.webapp.address
${yarn.resourcemanager.hostname}:8088
yarn.resourcemanager.webapp.https.address
${yarn.resourcemanager.hostname}:8090
yarn.resourcemanager.resource-tracker.address
${yarn.resourcemanager.hostname}:8031
yarn.resourcemanager.admin.address
${yarn.resourcemanager.hostname}:8033
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.scheduler.maximum-allocation-mb
8182
yarn.nodemanager.vmem-pmem-ratio
3.1
yarn.nodemanager.resource.memory-mb
2048
yarn.nodemanager.vmem-check-enabled
false
说明:yarn.nodemanager.vmem-check-enabled 这个配置的意思是忽略虚拟内存的检查,如果你是安装在虚拟机上,这个配置很有用,配上去之后后续操作不容易出问题。如果是实体机上,并且内存够多,可以将这个配置去掉。
5.4 启动hadoop
如果是第一次启动hadoop,在启动之前需要先进行初始化。因为master是namenode,所以只需要对master进行初始化操作,所谓初始化也就是对hdfs进行format。
进入到master这台机器的/opt/hadoop/hadoop-2.8.0/bin目录,也就是执行命令:
cd /opt/hadoop/hadoop-2.8.0/bin执行初始化脚本,也就是执行命令:
./hadoop namenode -format如图:
完整输出:
[root@master bin]# ./hadoop namenode -format
DEPRECATED: Use of this script to executehdfs command is deprecated.
Instead use the hdfs command for it.
17/05/26 14:25:07 INFO namenode.NameNode:STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: user = root
STARTUP_MSG: host = master/192.168.27.141
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.8.0
STARTUP_MSG: classpath =/opt/hadoop/hadoop-2.8.0/etc/hadoop:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/activation-1.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/asm-3.2.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/avro-1.7.4.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/commons-cli-1.2.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/commons-codec-1.4.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/commons-collections-3.2.2.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/commons-compress-1.4.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/commons-configuration-1.6.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/commons-digester-1.8.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/commons-io-2.4.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/commons-lang-2.6.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/commons-logging-1.1.3.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/commons-math3-3.1.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/commons-net-3.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/curator-client-2.7.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/curator-framework-2.7.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/curator-recipes-2.7.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/gson-2.2.4.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/guava-11.0.2.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/hadoop-annotations-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/hadoop-auth-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/hamcrest-core-1.3.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/htrace-core4-4.0.1-incubating.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/httpclient-4.5.2.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/httpcore-4.4.4.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/jcip-annotations-1.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/jersey-core-1.9.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/jersey-json-1.9.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/jersey-server-1.9.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/jets3t-0.9.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/jettison-1.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/jetty-6.1.26.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/jetty-sslengine-6.1.26.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/jetty-util-6.1.26.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/jsch-0.1.51.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/json-smart-1.1.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/jsp-api-2.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/jsr305-3.0.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/junit-4.11.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/log4j-1.2.17.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/mockito-all-1.8.5.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/netty-3.6.2.Final.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/nimbus-jose-jwt-3.9.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/paranamer-2.3.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/servlet-api-2.5.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/slf4j-api-1.7.10.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/stax-api-1.0-2.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/xmlenc-0.52.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/xz-1.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/zookeeper-3.4.6.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/hadoop-common-2.8.0-tests.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/hadoop-common-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/hadoop-nfs-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/asm-3.2.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/commons-io-2.4.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/guava-11.0.2.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/hadoop-hdfs-client-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/htrace-core4-4.0.1-incubating.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/jsr305-3.0.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/netty-all-4.0.23.Final.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/okhttp-2.4.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/okio-1.4.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/hadoop-hdfs-2.8.0-tests.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/hadoop-hdfs-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/hadoop-hdfs-client-2.8.0-tests.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/hadoop-hdfs-client-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/hadoop-hdfs-native-client-2.8.0-tests.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/hadoop-hdfs-native-client-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/hdfs/hadoop-hdfs-nfs-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/activation-1.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/aopalliance-1.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/asm-3.2.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/commons-cli-1.2.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/commons-codec-1.4.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/commons-collections-3.2.2.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/commons-io-2.4.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/commons-lang-2.6.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/commons-math-2.2.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/curator-client-2.7.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/curator-test-2.7.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/fst-2.24.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/guava-11.0.2.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/guice-3.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/javassist-3.18.1-GA.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/javax.inject-1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/jersey-client-1.9.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/jersey-core-1.9.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/jersey-json-1.9.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/jersey-server-1.9.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/jettison-1.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/jetty-6.1.26.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/jsr305-3.0.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/log4j-1.2.17.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/objenesis-2.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/servlet-api-2.5.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/xz-1.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/zookeeper-3.4.6-tests.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/hadoop-yarn-api-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/hadoop-yarn-client-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/hadoop-yarn-common-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/hadoop-yarn-registry-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/hadoop-yarn-server-common-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/hadoop-yarn-server-tests-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/hadoop-yarn-server-timeline-pluginstorage-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/asm-3.2.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/guice-3.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/hadoop-annotations-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/javax.inject-1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/junit-4.11.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/lib/xz-1.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.8.0-tests.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar:/opt/hadoop/hadoop-2.8.0/contrib/capacity-scheduler/*.jar:/opt/hadoop/hadoop-2.8.0/contrib/capacity-scheduler/*.jar
STARTUP_MSG: build =https://git-wip-us.apache.org/repos/asf/hadoop.git -r91f2b7a13d1e97be65db92ddabc627cc29ac0009; compiled by 'jdu' on2017-03-17T04:12Z
STARTUP_MSG: java = 1.8.0_121
************************************************************/
17/05/26 14:25:07 INFO namenode.NameNode:registered UNIX signal handlers for [TERM, HUP, INT]
17/05/26 14:25:07 INFO namenode.NameNode:createNameNode [-format]
17/05/26 14:25:08 WARNutil.NativeCodeLoader: Unable to load native-hadoop library for yourplatform... using builtin-java classes where applicable
17/05/26 14:25:08 WARN common.Util: Path/root/hadoop/dfs/name should be specified as a URI in configuration files.Please update hdfs configuration.
17/05/26 14:25:08 WARN common.Util: Path/root/hadoop/dfs/name should be specified as a URI in configuration files.Please update hdfs configuration.
Formatting using clusterid:CID-dfd9af16-7746-405f-9c99-1750e7e80df8
17/05/26 14:25:08 INFO namenode.FSEditLog:Edit logging is async:false
17/05/26 14:25:08 INFOnamenode.FSNamesystem: KeyProvider: null
17/05/26 14:25:08 INFOnamenode.FSNamesystem: fsLock is fair: true
17/05/26 14:25:08 INFOnamenode.FSNamesystem: Detailed lock hold time metrics enabled: false
17/05/26 14:25:09 INFO blockmanagement.DatanodeManager:dfs.block.invalidate.limit=1000
17/05/26 14:25:09 INFOblockmanagement.DatanodeManager:dfs.namenode.datanode.registration.ip-hostname-check=true
17/05/26 14:25:09 INFOblockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec isset to 000:00:00:00.000
17/05/26 14:25:09 INFOblockmanagement.BlockManager: The block deletion will start around 2017 May 2614:25:09
17/05/26 14:25:09 INFO util.GSet: Computingcapacity for map BlocksMap
17/05/26 14:25:09 INFO util.GSet: VMtype = 64-bit
17/05/26 14:25:09 INFO util.GSet: 2.0% maxmemory 889 MB = 17.8 MB
17/05/26 14:25:09 INFO util.GSet:capacity = 2^21 = 2097152 entries
17/05/26 14:25:09 INFOblockmanagement.BlockManager: dfs.block.access.token.enable=false
17/05/26 14:25:09 INFOblockmanagement.BlockManager: defaultReplication = 2
17/05/26 14:25:09 INFOblockmanagement.BlockManager: maxReplication = 512
17/05/26 14:25:09 INFOblockmanagement.BlockManager: minReplication = 1
17/05/26 14:25:09 INFOblockmanagement.BlockManager: maxReplicationStreams = 2
17/05/26 14:25:09 INFOblockmanagement.BlockManager: replicationRecheckInterval = 3000
17/05/26 14:25:09 INFOblockmanagement.BlockManager: encryptDataTransfer = false
17/05/26 14:25:09 INFOblockmanagement.BlockManager: maxNumBlocksToLog = 1000
17/05/26 14:25:09 INFOnamenode.FSNamesystem: fsOwner = root (auth:SIMPLE)
17/05/26 14:25:09 INFOnamenode.FSNamesystem: supergroup = supergroup
17/05/26 14:25:09 INFOnamenode.FSNamesystem: isPermissionEnabled = false
17/05/26 14:25:09 INFOnamenode.FSNamesystem: HA Enabled: false
17/05/26 14:25:09 INFOnamenode.FSNamesystem: Append Enabled: true
17/05/26 14:25:09 INFO util.GSet: Computingcapacity for map INodeMap
17/05/26 14:25:09 INFO util.GSet: VMtype = 64-bit
17/05/26 14:25:09 INFO util.GSet: 1.0% maxmemory 889 MB = 8.9 MB
17/05/26 14:25:09 INFO util.GSet:capacity = 2^20 = 1048576 entries
17/05/26 14:25:09 INFOnamenode.FSDirectory: ACLs enabled? false
17/05/26 14:25:09 INFOnamenode.FSDirectory: XAttrs enabled? true
17/05/26 14:25:09 INFO namenode.NameNode:Caching file names occurring more than 10 times
17/05/26 14:25:09 INFO util.GSet: Computingcapacity for map cachedBlocks
17/05/26 14:25:09 INFO util.GSet: VMtype = 64-bit
17/05/26 14:25:09 INFO util.GSet: 0.25% maxmemory 889 MB = 2.2 MB
17/05/26 14:25:09 INFO util.GSet:capacity = 2^18 = 262144 entries
17/05/26 14:25:09 INFO namenode.FSNamesystem:dfs.namenode.safemode.threshold-pct = 0.9990000128746033
17/05/26 14:25:09 INFOnamenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
17/05/26 14:25:09 INFOnamenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
17/05/26 14:25:09 INFO metrics.TopMetrics:NNTop conf: dfs.namenode.top.window.num.buckets = 10
17/05/26 14:25:09 INFO metrics.TopMetrics:NNTop conf: dfs.namenode.top.num.users = 10
17/05/26 14:25:09 INFO metrics.TopMetrics:NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
17/05/26 14:25:09 INFOnamenode.FSNamesystem: Retry cache on namenode is enabled
17/05/26 14:25:09 INFOnamenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cacheentry expiry time is 600000 millis
17/05/26 14:25:09 INFO util.GSet: Computingcapacity for map NameNodeRetryCache
17/05/26 14:25:09 INFO util.GSet: VMtype = 64-bit
17/05/26 14:25:09 INFO util.GSet:0.029999999329447746% max memory 889 MB = 273.1 KB
17/05/26 14:25:09 INFO util.GSet:capacity = 2^15 = 32768 entries
17/05/26 14:25:09 INFO namenode.FSImage:Allocated new BlockPoolId: BP-344149450-192.168.27.141-1495779909753
17/05/26 14:25:09 INFO common.Storage:Storage directory /root/hadoop/dfs/name has been successfully formatted.
17/05/26 14:25:10 INFOnamenode.FSImageFormatProtobuf: Saving image file/root/hadoop/dfs/name/current/fsimage.ckpt_0000000000000000000 using nocompression
17/05/26 14:25:10 INFOnamenode.FSImageFormatProtobuf: Image file/root/hadoop/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 321bytes saved in 0 seconds.
17/05/26 14:25:10 INFOnamenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
17/05/26 14:25:10 INFO util.ExitUtil:Exiting with status 0
17/05/26 14:25:10 INFO namenode.NameNode:SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode atmaster/192.168.27.141
************************************************************/
[root@master bin]#说明:初始化只需要进行一次即可,后面再启动并不需要执行初始化。
上面初始化完成了,直接进入sbin目录:
cd /opt/hadoop/hadoop-2.8.0/sbin执行启动命令:
./start-all.sh如图:
完整的输出信息是:
[root@masterbin]# cd /opt/hadoop/hadoop-2.8.0/sbin
[root@master sbin]# ./start-all.sh
This script is Deprecated. Instead usestart-dfs.sh and start-yarn.sh
17/05/26 14:27:00 WARNutil.NativeCodeLoader: Unable to load native-hadoop library for yourplatform... using builtin-java classes where applicable
Starting namenodes on [master]
master: starting namenode, logging to/opt/hadoop/hadoop-2.8.0/logs/hadoop-root-namenode-master.out
slave1: starting datanode, logging to/opt/hadoop/hadoop-2.8.0/logs/hadoop-root-datanode-slave1.out
slave2: starting datanode, logging to/opt/hadoop/hadoop-2.8.0/logs/hadoop-root-datanode-slave2.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode,logging to/opt/hadoop/hadoop-2.8.0/logs/hadoop-root-secondarynamenode-master.out
17/05/26 14:27:25 WARNutil.NativeCodeLoader: Unable to load native-hadoop library for yourplatform... using builtin-java classes where applicable
starting yarn daemons
starting resourcemanager, logging to/opt/hadoop/hadoop-2.8.0/logs/yarn-root-resourcemanager-master.out
slave1: starting nodemanager, logging to/opt/hadoop/hadoop-2.8.0/logs/yarn-root-nodemanager-slave1.out
slave2: starting nodemanager, logging to/opt/hadoop/hadoop-2.8.0/logs/yarn-root-nodemanager-slave2.out
[root@master sbin]#开放50070端口,或者直接关闭防火墙。CentOS7防火墙相关的操作请参考给博文:
http://blog.csdn.net/pucao_cug/article/details/72453382
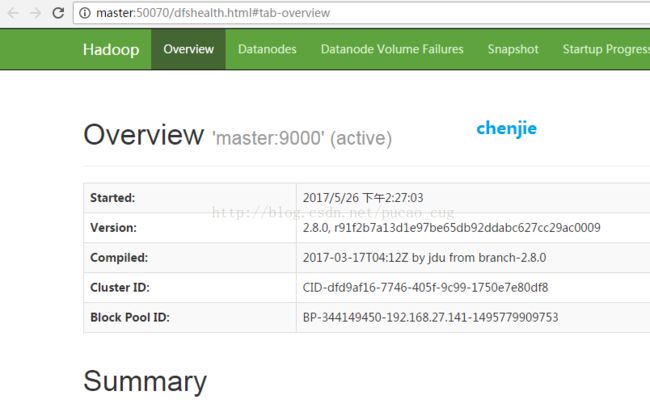
访问下面的地址看,看是否启动成功:
http://master:50070
如图:
还可以访问这个地址:http://master:50090
如图:

或者这个地址:http://master:8088
如图:

6 Spark 的安装和启动
在Hive OnSpark的环境中,Spark的配置要做一些修改,本章会讲到这些配置内容。
6.1 对conf目录下的文件做配置
对3台机器的/opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive/conf的一系列文件做配置。
6.1.1 新建spark-env.h文件
执行命令,进入到/opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive/conf目录内:
cd /opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive/conf以spark为我们创建好的模板创建一个spark-env.h文件,命令是:
cp spark-env.sh.template spark-env.sh编辑spark-env.h文件,在里面加入配置(具体路径以自己的为准):
export SCALA_HOME=/opt/scala/scala-2.11.8
export JAVA_HOME=/opt/java/jdk1.8.0_121
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive
export SPARK_MASTER_IP=master
export SPARK_EXECUTOR_MEMORY=512M6.1.2 新建slaves文件
以spark为我们创建好的模板创建一个slaves文件,命令是:
cp spark-defaults.conf.template spark-defaults.conf编辑slaves文件,里面的内容为:
slave1
slave26.1.3 新建spark-defaults.conf文件
以spark为我们创建好的模板创建一个slaves文件,命令是:
cp spark-defaults.conf.template spark-defaults.conf编辑spark-defaults.conf文件,在里面新增配置:
spark.master spark://master:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/directory
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 700M
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value-Dnumbers="one two three"6.2 在HDFS上创建目录
因为上面的配置中让spark将eventLog存到HDFS的directory目录下,所以需要执行hadoop命令,在HDFS上创建directory目录,创建目录命令是:
$HADOOP_HOME/bin/hadoop fs -mkdir -p /directory授权命令是:
$HADOOP_HOME/bin/hadoop fs -chmod 777 /directory如图:

6.3 启动spark
进入sbin目录,也就是执行下面的命令:
cd /opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive/sbin执行启动脚本:
./start-all.sh如图:

完整的输出是:
[root@mastersbin]# cd /opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive/sbin
[root@master sbin]# cd /opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive/sbin
[root@master sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master,logging to/opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
slave1: startingorg.apache.spark.deploy.worker.Worker, logging to /opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave1.out
slave2: startingorg.apache.spark.deploy.worker.Worker, logging to/opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave2.out
[root@master sbin]#访问这个地址看是否启动成功:
http://master:8080
如图:

7 Hive的配置和启动
对于Hive安装不熟悉的可以参考该博文:
http://blog.csdn.net/pucao_cug/article/details/71773665
不过需要强调的是,那篇博文中没有搭建 Hive On Spark环境,所以那篇博文只是用于对安装Hive做参考,如果要搭建Hive On Spark本章节后面的配置不能略过,必须认真看。
7.1 执行命令创建HDFS目录
hive的文件存储在hadoop提供的HDFS分布式文件系统里,需要调用hadoop命令,在hdfs上创建几个目录。
执行创建命令:
$HADOOP_HOME/bin/hadoop fs -mkdir -p /user/hive/warehouse给刚才新建的目录赋予读写权限,执行命令:
$HADOOP_HOME/bin/hadoop fs -chmod 777 /user/hive/warehouse 执行创建命令:
$HADOOP_HOME/bin/hadoop fs -mkdir -p /tmp/hive执行授权命令:
$HADOOP_HOME/bin/hadoop fs -chmod 777 /tmp/hive如图:

7.2 对conf目录下的配置文件进行配置
对/opt/hive/apache-hive-2.1.1-bin/conf目录下的一系列文件做配置,这些配置很关键。
7.2.1 新建hive-env.sh文件并进行修改
进入到/opt/hive/apache-hive-2.1.1-bin/conf目录,命令是:
cd /opt/hive/apache-hive-2.1.1-bin/conf将hive-env.sh.template文件复制一份,并且改名为hive-env.sh,命令是:
cp hive-env.sh.template hive-env.sh打开hive-env.sh配置并且添加以下内容:
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HIVE_CONF_DIR=/opt/hive/apache-hive-2.1.1-bin/conf
export HIVE_AUX_JARS_PATH=/opt/hive/apache-hive-2.1.1-bin/lib7.2.2 对hive-site.xml文件进行配置
首先要创建hive-site.xml文件
进入到/opt/hive/apache-hive-2.1.1-bin/conf目录,命令是:
cd /opt/hive/apache-hive-2.1.1-bin/conf将hive-default.xml.template文件复制一份,并且改名为hive-site.xml,命令是:
cp hive-default.xml.template hive-site.xml7.2.2.1 目录相关的配置
首先在master机器上上创建临时目录/opt/hive/tmp
将hive-site.xml文件中的所有${system:java.io.tmpdir}替换为/opt/hive/tmp
将hive-site.xml文件中的所有${system:user.name}都替换为root
7.2.2.2 MySQL数据库相关的配置
搜索javax.jdo.option.ConnectionURL,将该name对应的value修改为MySQL的地址,例如我修改后是:
javax.jdo.option.ConnectionURL
jdbc:mysql://192.168.27.138:3306/hive?createDatabaseIfNotExist=true 搜索javax.jdo.option.ConnectionDriverName,将该name对应的value修改为MySQL驱动类路径:
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver 搜索javax.jdo.option.ConnectionUserName,将对应的value修改为MySQL数据库登录名:
javax.jdo.option.ConnectionUserName
root 搜索javax.jdo.option.ConnectionPassword,将对应的value修改为MySQL数据库的登录密码:
javax.jdo.option.ConnectionPassword
cj 搜索hive.metastore.schema.verification,将对应的value修改为false:
hive.metastore.schema.verification
false 7.2.2.3 其他配置
搜索hive.execution.engine,将对应的value修改为spark:
hive.execution.engine
spark 在末尾新增配置:
hive.enable.spark.execution.engine
true
spark.home
/opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive
spark.master
spark://master:7077
spark.submit.deployMode
client
spark.serializer
org.apache.spark.serializer.KryoSerializer
spark.eventLog.enabled
true
spark.eventLog.dir
hdfs://master:9000/directory
spark.executor.memory
512m
7.3 将MySQL驱动包上载到lib目录
将MySQL驱动包上载到Hive的lib目录下,例如我是上载到/opt/hive/apache-hive-2.1.1-bin/lib目录下。
如图:

7.4 将Spark下的某些jar包拷贝到hive目录下
在master 机器上,将/opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive/lib目录下的spark-assembly-1.6.3-hadoop2.4.0.jar包拷贝到/opt/hive/apache-hive-2.1.1-bin/lib目录下。
如图:

7.5 对hive所要连接的数据库做初始化
进入到hive的bin目录执行命令:
cd /opt/hive/apache-hive-2.1.1-bin/bin对数据库进行初始化,执行命令:
schematool -initSchema -dbType mysql如图:

完整输出是:
[root@mastersbin]# cd /opt/hive/apache-hive-2.1.1-bin/bin
[root@master bin]# schematool -initSchema -dbType mysql
which: no hbase in(.:/opt/java/jdk1.8.0_121/bin:/opt/hadoop/hadoop-2.8.0/bin:/opt/hadoop/hadoop-2.8.0/sbin:/opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive/bin:/opt/zookeeper/zookeeper-3.4.10/bin:/opt/hive/apache-hive-2.1.1-bin/bin:/opt/maven/apache-maven-3.3.9/bin:/opt/scala/scala-2.11.8/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin)
SLF4J: Class path contains multiple SLF4Jbindings.
SLF4J: Found binding in[jar:file:/opt/hive/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in[jar:file:/opt/hive/apache-hive-2.1.1-bin/lib/spark-assembly-1.6.3-hadoop2.4.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in[jar:file:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Seehttp://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type[org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://192.168.27.138:3306/hive?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
Starting metastore schema initialization to2.1.0
Initialization scripthive-schema-2.1.0.mysql.sql
Initialization script completed
schemaTool completed
[root@master bin]#7.6 启动hive命令行窗口
现在打开到hive的bin目录中,打开命令是:
cd /opt/hive/apache-hive-2.1.1-bin/bin执行hive脚本,也就是执行命令:
./hive如图:

完整输出是:
[root@mastersbin]# cd /opt/hive/apache-hive-2.1.1-bin/bin
[root@master bin]# schematool -initSchema -dbType mysql
which: no hbase in(.:/opt/java/jdk1.8.0_121/bin:/opt/hadoop/hadoop-2.8.0/bin:/opt/hadoop/hadoop-2.8.0/sbin:/opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive/bin:/opt/zookeeper/zookeeper-3.4.10/bin:/opt/hive/apache-hive-2.1.1-bin/bin:/opt/maven/apache-maven-3.3.9/bin:/opt/scala/scala-2.11.8/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin)
SLF4J: Class path contains multiple SLF4Jbindings.
SLF4J: Found binding in[jar:file:/opt/hive/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in[jar:file:/opt/hive/apache-hive-2.1.1-bin/lib/spark-assembly-1.6.3-hadoop2.4.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in[jar:file:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Seehttp://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type[org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://192.168.27.138:3306/hive?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
Starting metastore schema initialization to2.1.0
Initialization scripthive-schema-2.1.0.mysql.sql
Initialization script completed
schemaTool completed
[root@master bin]# cd /opt/hive/apache-hive-2.1.1-bin/bin
[root@master bin]# ./hive
which: no hbase in(.:/opt/java/jdk1.8.0_121/bin:/opt/hadoop/hadoop-2.8.0/bin:/opt/hadoop/hadoop-2.8.0/sbin:/opt/spark/spark-1.6.3-bin-hadoop2.4-without-hive/bin:/opt/zookeeper/zookeeper-3.4.10/bin:/opt/hive/apache-hive-2.1.1-bin/bin:/opt/maven/apache-maven-3.3.9/bin:/opt/scala/scala-2.11.8/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin)
SLF4J: Class path contains multiple SLF4Jbindings.
SLF4J: Found binding in[jar:file:/opt/hive/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in[jar:file:/opt/hive/apache-hive-2.1.1-bin/lib/spark-assembly-1.6.3-hadoop2.4.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in[jar:file:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindingsfor an explanation.
SLF4J: Actual binding is of type[org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration infile:/opt/hive/apache-hive-2.1.1-bin/conf/hive-log4j2.properties Async: true
hive>7.7 在hive中创建数据表
在hive命令行中执行hive命令,创建表:
create table t_hello(id int, name string)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;如图:

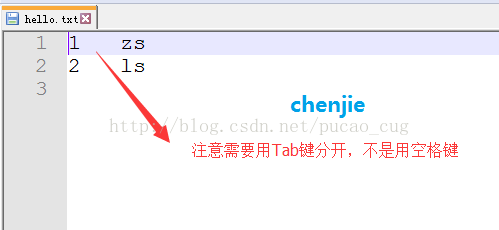
表已经有了,往表里加点数据吧,首先在/opt/hive目录下创建一个hello.txt文件,往文件里添加点数据
如图:
在hive命令行中执行hive命令,将hello.txt中的内容加载到t_hello表中,命令是:
load data local inpath'/opt/hive/hello.txt' into table t_hello;如图:

执行查询命令,看看t_hello表里的内容:
select * from t_hello;如图:

8 对Hive On Spark环境做测试
8.1 执行select count命令进行测试
是否能顺利执行selectcount命令,才是我们Hive On Spark环境是否搭建成功的标志。
接着7.7章节的命令行窗口继续执行select count命令:
select count(*) from t_hello;如图:
完整的输出信息是:
hive> create table t_hello(id int, namestring) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;
OK
Time taken: 2.332 seconds
hive> load data local inpath '/opt/hive/hello.txt' into table t_hello;
Loading data to table default.t_hello
OK
Time taken: 2.587 seconds
hive> select * from t_hello;
OK
1 zs
2 ls
Time taken: 1.917 seconds, Fetched: 2row(s)
hive> select count(*) from t_hello;
Query ID =root_20170526151457_6e319edf-b3e8-4274-9a02-736306cb00d6
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for areducer (in bytes):
sethive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number ofreducers:
sethive.exec.reducers.max=
In order to set a constant number ofreducers:
setmapreduce.job.reduces=
Starting Spark Job =52a77fdf-22a7-45aa-b02d-2f9c764de424
state = SENT
state = SENT
state = SENT
state = SENT
state = SENT
state = SENT
state = SENT
state = SENT
state = SENT
state = SENT
state = SENT
state = SENT
state = SENT
state = SENT
state = SENT
state = SENT
state = SENT
state = STARTED
state = STARTED
state = STARTED
state = STARTED
state = STARTED
state = STARTED
state = STARTED
state = STARTED
state = STARTED
state = STARTED
state = STARTED
Query Hive on Spark job[0] stages:
0
1
Status: Running (Hive on Spark job[0])
Job Progress Format
CurrentTime StageId_StageAttemptId:SucceededTasksCount(+RunningTasksCount-FailedTasksCount)/TotalTasksCount[StageCost]
2017-05-26 15:15:33,439 Stage-0_0: 0/1 Stage-1_0: 0/1
state = STARTED
2017-05-26 15:15:34,470 Stage-0_0:0(+1)/1 Stage-1_0: 0/1
state = STARTED
state = STARTED
state = STARTED
2017-05-26 15:15:37,533 Stage-0_0:0(+1)/1 Stage-1_0: 0/1
state = STARTED
state = STARTED
state = STARTED
2017-05-26 15:15:40,643 Stage-0_0:0(+1)/1 Stage-1_0: 0/1
state = STARTED
state = STARTED
state = STARTED
2017-05-26 15:15:43,779 Stage-0_0: 0(+1)/1 Stage-1_0: 0/1
state = STARTED
state = STARTED
state = STARTED
2017-05-26 15:15:46,904 Stage-0_0:0(+1)/1 Stage-1_0: 0/1
state = STARTED
state = STARTED
state = STARTED
2017-05-26 15:15:50,098 Stage-0_0:0(+1)/1 Stage-1_0: 0/1
state = STARTED
state = STARTED
state = STARTED
2017-05-26 15:15:53,150 Stage-0_0:0(+1)/1 Stage-1_0: 0/1
state = STARTED
state = STARTED
state = STARTED
2017-05-26 15:15:56,187 Stage-0_0:0(+1)/1 Stage-1_0: 0/1
state = STARTED
state = STARTED
state = STARTED
2017-05-26 15:15:59,361 Stage-0_0:0(+1)/1 Stage-1_0: 0/1
state = STARTED
state = STARTED
state = STARTED
2017-05-26 15:16:02,515 Stage-0_0:0(+1)/1 Stage-1_0: 0/1
state = STARTED
state = STARTED
2017-05-26 15:16:04,559 Stage-0_0: 1/1 FinishedStage-1_0: 0(+1)/1
state = STARTED
state = SUCCEEDED
2017-05-26 15:16:06,598 Stage-0_0: 1/1Finished Stage-1_0: 1/1 Finished
Status: Finished successfully in 60.76seconds
OK
2
Time taken: 69.023 seconds, Fetched: 1row(s)
hive> 说明:在数据很少的时候并不能体现Hive on Spark的优势,但是数据很多的时候就会比较明显了。能够正常执行select cout命令,证明我们的Hive On Spark环境搭建成功了。
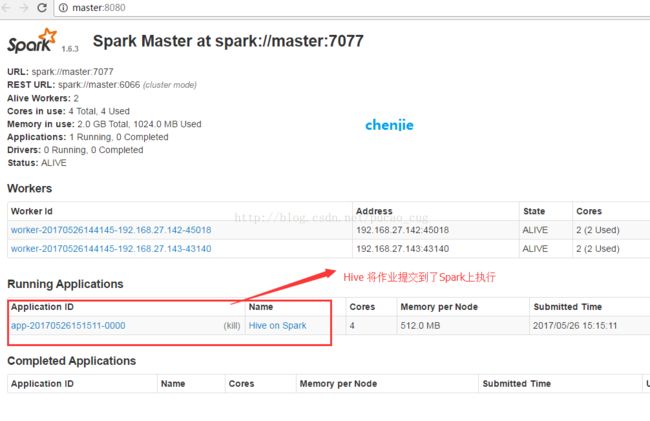
8.2 在浏览器里访问spark的UI界面
如果Hive On Spark运行成功,可以在spark的UI界面上查看,我们是否在Hive中成功调用了Spark集群来执行任务。访问下面的地址:http://master:8080/
如图: