01CSI 发展和现状
XSKY早在2018年底就实现了容器存储接口(CSI) driver,而CSI也在2018年底发布的Kubernetes(K8s) v1.13版本中正式GA,现在已经成为了容器和存储的标准接口。
作为国内率先拥抱CSI的存储厂商,XSKY开始CSI driver是使用块(iSCSI)对接的,后来又支持文件(NFS)对接,经过一年多的验证,目前已经十分稳定并为各大客户提供了稳定的容器化场景支持。
Kubernetes CSI后来推出了越来越多的新特性,XSKY紧随社区步伐,不断更新迭代,先后支持了各种实用的新特性,包括扩容,裸卷,快照等。但是,仅仅是"多"还不够,正所谓“天下武功,唯快不破”,我们在"快"上也花了一点功夫。

图一:图片来源网络
众所周知,容器相比虚拟机要更加轻量,在K8s集群中,运行着众多的Pod,由于容器是应用级的隔离环境,相比虚拟机而言,一个K8s集群里面Pod的数量从几十个到几万个的场景都会存在,因此,在大规模调度的时候对持久卷的管理可以说是很关键的操作。
但是在使用过程中,如果发生大规模的调度时候难免有些不理想的情况,举个例子,在最初正式支持CSI的K8s 1.13版本,一个常见的问题是挂载的时候经常看到Pod调度完成后出现Attach timeout的警告,这就是一个最常见的挂载超时场景。
02原因分析
首先明确问题之前我们回顾下之前分享过的文章有提到K8s和存储是如何交互的。
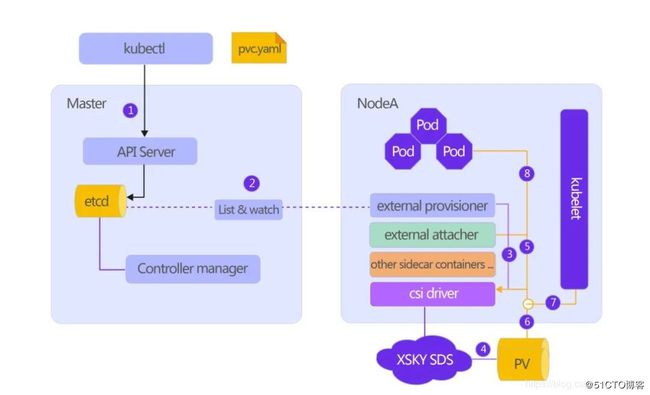
图二
早前的文章《详解支持 kubernetes CSI的持久化容器存储》有具体介绍一个PV的产生和挂载的具体流程, 这里不妨再温习一次,为简化模型,我们把整个流程分成两部分。
从用户提交一个pvc.yaml文件开始,上图1,2,3,4步骤我们称之为provisioning过程,它的作用是从API server开始创建一个卷的流程。从PV挂载到实际使用的容器或者说业务Pod的过程称之为Publish Volume。相对应的是上图5,6,7,8。
不难看出,一个存储卷的使用过程是经过多阶段的处理,调用方式也是包括且不限RESTful接口,RPC调用,以及其他各进程间状态同步,因此整套流程下来需要考虑的问题比较多。
其中provision过程即创建PV的过程实测还是比较快的,100个卷的创建仅需几十秒,所以暂时也不需要优化。
而对于挂载卷的流程可以看到external attacher和kubelet这两个组件都会调用XSKY CSI driver来对卷进行挂载处理。由于这两步都是通过gRPC实现远程调用,在比较早的K8s版本中,它们是硬编码,超时时间为15秒,此外对于未完成的或失败请求有指数退避算法重试。
也就是说,在一次重试后暂时挂载不上它会在30秒后再重试,再失败就60秒,如果请求数比较少的情况没有太大问题,但如果是在大批量容器同时调度的过程中这种场景就出现较多重试的情况,因为挂载请求下发到存储集群后并不能马上就处理完成,而K8s对这些请求只等待15秒,所以有相当一部分的请求并未正确处理,再加上指数退避重试机制,如果存储底层有较多卷请求堆积未处理完成,那K8s的重试间隔将越拉越长,甚至拉到10几分钟之后。
挂载卷的操作我们简化为三步动作,即向存储集群发起添加卷到访问路径,在K8s Node节点上扫描设备,以及格式化和挂载,对于并发的请求而言,有很多是在阻塞着,如果同时调度Pod发起挂载操作的话,就有可能出现K8s的重试间隔越拉越长。对于用户而言就是过了很久还没有把所有Pod启动成功。
图三
上图展示了并发挂载的过程,由于阻塞式挂载导致PublishVolume请求被越拖越长,因此一部分的挂载操作很容易就到达15秒的超时上限,然后等待下一次重试。
03优化
回顾“图二”的挂载流程,我们把整套流程自上而下进行分层分析,分别是K8s平台层, CSI driver中间层,xmsd控制层以及XDC存储管理层。针对每个层面都做了一些优化和调整。
1、K8s顶层优化
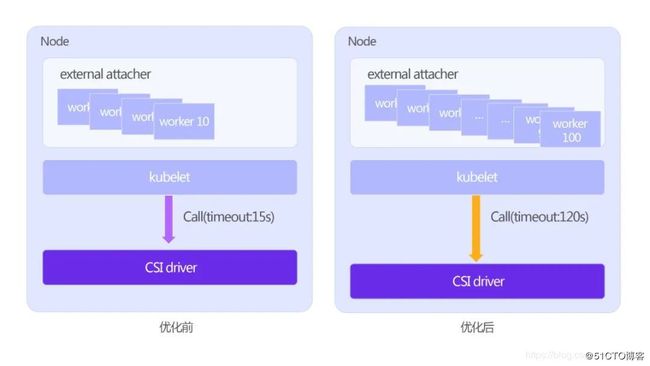
图四
K8s Pod挂载卷时候主要是external attacher和kubelet两个组件来调用CSI driver,因此可以从这两者着手:external attacher是一个sidecar容器,负责监听K8s集群中的volumeattachment对象,每当controller manager生成一个volumeattachment对象时就代表K8s内要进行一次卷挂载操作,external attacher监听到此对象的产生时候就开始向XSKY 的CSI driver发起一个RPC请求,完成第一阶段处理。
默认这个external attacher只有10个协程去处理这样的监听事件,这对于普通场景使用尚且可以,但是对于大规模的集群就未必是最佳值。考虑到用户场景的不同,我们向社区提交了一个PR将工作协程数改成可配置,这样既不会有API breaking change,又能根据用户所在集群动态配置,比如在这种存在大批量并发的K8s集群默认使用的是100个worker,以达到最佳监听效果。
Kubelet是一个核心组件,它也是直接参与了持久卷挂载的操作,在完成第一阶段的请求后,由kubelet向CSI driver发起另一个RPC请求。
前面提到由于kubelet每次请求设置的超时时间只有15秒,显然对于很多存储商而言15秒其实还是不够的,开源社区也有其他成员讨论过这一点。经过大家实践后得出的结论是,建议最佳值为2分钟。
虽然这是一个小改动,但是对于存储端而言极大提升了一次挂载成功的概率,一定程度上减少了很多无意义的重试,不至于把重试间隔拉到10分钟以上,对于用户体验的提升也是比较明确的。因此,建议有条件的优先使用更新版本的Kubernetes。
2、CSI driver优化
为方便理解,前面描述Kubernetes挂载卷的操作,我们简化为一个PublishVolume动作,其中包含3步耗时操作,包括AddVolume,ScanDevice 和Format。
其中AddVolume是直接调用XMS的接口实现,我们后面会介绍这部分优化。现在我们关注在ScanDevice。
ScanDevice的优化:向访问路径添加卷操作完成之后,CSI driver开始在K8s 的node节点上扫描iSCSI设备,这里扫描设备的操作就基于iscsiadm来完成的,当有大量Pod在挂载卷的准备过程,可以发现存在大量的iscsiadm命令在执行,这对于同一个节点而言很多都是重复的请求,比如说Pod A添加完卷操作后调用 iscsiadm 来发现和登陆,同时Pod B添加完成后也调用 iscsiadm来登陆和刷新,假如同一个Node上有100个Pod,那甚至会出现数百个 iscsiadm进程,这对于target端而言反而是增大负载,刷新进程的数量多并不会使发现设备的过程加快。
后来经过实践我们改良了这种实现,合理复用了iscsiadm,将服务器压力严格控制下来避免这种情况。
锁的粒度控制:在第一个CSI driver版本,我们曾经对很多资源都做了锁的控制。那是因为和后端存储交互的API大多不是为容器场景设计的,会有很多方面的限制,包括资源竞争,状态冲突等情况,因此需要在顶层自行控制并发,结果就是访问路径,客户端组等资源的操作都加锁,代价就是我们的并发量很多受限于此设计。我们重新进行了优化,现在可以实现并发的操作,将来自K8s的请求快速转换到xmsd和XDC层面处理。
3、XMS接口优化
XMS (XSKY Management Service) : 即XSKY管理服务,作为数据管理平台来提供分布式存储集群的管理功能,并提供API等方式提供存储的扩展能力。
考虑到容器使用的访问路径有概率被管理面误操作,也为了更快创建所需要的资源,把一些XSKY的资源被抽象定义到Kubernetes集群中,因此可以在K8s集群使用一个yaml配置文件,一条kubectl create命令即可完成几乎所有的初始化工作,极大解放了部署成本。
图五
其中访问路径,VIP是通过CRD集成到Kubernetes。由于自定义控制器的工作机制,总能保障有指定数量的访问路径和网关组以及VIP的存在,而不担心用户误操作影响存储集群的使用。管理员所需要的操作仅仅是一条kubectl命令,然后就等待部署完成。
另外,XMS设计初衷并不是针对容器场景,很多操作基本是互斥,因此很多API请求都被拒绝,效率比较低,于是在后续的版本已经优化这一点。使得在API接口层允许并发添加和移除卷请求,一定程度提高了API的可用性。
Task优化:task是XMS的内部执行单元,它负责将API转换为具体的动作,比如前面提到的添加卷的行为则对应一个task,这个task去调底层XDC来完成mapping操作。在以前由于接口限制只能一个一个往下添加,所以task执行的密度并不高。完成优化后则可以实现大量的task同时执行添加映射操作,任务十分密集。
4、XDC优化
XDC (XSKY Data Client): 即XSKY数据客户端,块存储网关,支持iSCSI、FC、SCSI及RBD等不同类型的访问路径网关,XDC服务提供数据QoS、流控、流量,卷管理等功能。
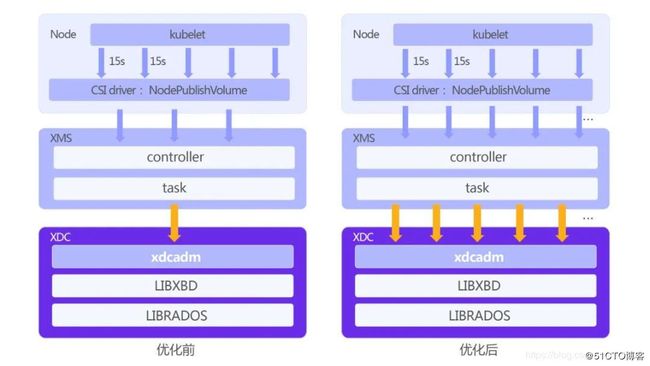
图六
XDC作为底层最关键的映射管理单元,之前的工作模式都是比较直接,任务请求逐个排队处理,效率非常低,为了应对容器大规模场景,我们已经重新设计成可支持并发的模型。
04小结
至此,已经从K8s平台层到CSI driver,以及内部xmsd和XDC每个层面都进行了各种类型的优化。对应100个Pod的挂载,以前需要十几、二十分钟到现在一、两分钟,时间缩短10倍,助力用户建设高效的容器云平台。
————————————————
版权声明:本文为CSDN博主「XSKY」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/XSKY/article/details/106901570