python - opencv中的dnn模块使用 简单的物体识别
% 用于读取图像文件的py文件
import os
# 可供筛选的后缀名 以“元组”的方式,不然后续会查找出错
images_type = (".jpg", ".jpeg", ".png", ".bmp", ".tif", ".tiff")
def list_images(base_path, contains=None):
return list_file(base_path, validExt=images_type, contain=contains)
def list_file(base_path, validExt=None, contain=None):
# 遍历base_path:rootDir 为根路径 dirNames为子文件夹名 fileNames为文件名
for (rootDir, dirNames, fileNames) in os.walk(base_path):
for file in fileNames:
if contain is not None and file.find(contain) == -1:
continue
ext = file[file.rfind("."):].lower()
if validExt is None or ext.endswith(validExt):
imagePath = os.path.join(rootDir, file)
yield imagePath # 配合list使用% main 文件
import utils_paths
import numpy as np
import cv2
# 标签文件处理,找到所有的类标签
row = open("./model_files/synset_words.txt").read().strip().split("\n")
class_label = [r[r.find(" "):].split(",")[0] for r in row]
# Caffe所需的配置文件
net = cv2.dnn.readNetFromCaffe("./model_files/bvlc_googlenet.prototxt", "./model_files/bvlc_googlenet.caffemodel")
# 图像路径
imagePaths = sorted(list(utils_paths.list_images("./images")))
# 图像数据预处理(一)
img = cv2.imread(imagePaths[0])
# 自然物体的识别均值 (104, 117, 123)
blob = cv2.dnn.blobFromImage(img, 1, (224, 224), (104, 117, 123))
print("First Blob: {}".format(blob.shape))
# 预测结果
net.setInput(blob)
preds = net.forward()
# 排序, 取概率最大的结果
idx = np.argsort(preds[0])[-1] # 注意这里的preds[0]
# 注意是:{:.2f}
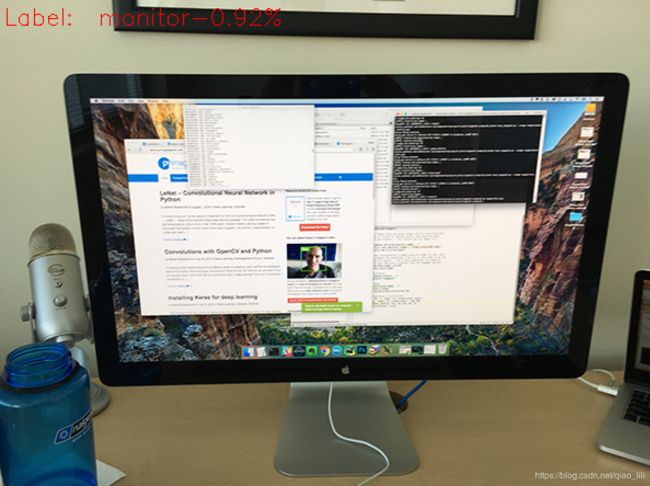
text = "label: {}-{:.2f}%".format(class_label[idx], preds[0][idx]*100)
cv2.putText(img, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255))
cv2.imshow("figure", img)
cv2.waitKey(0)
# 图像数据预处理(二)打包识别
# 打包
imgs = []
for file in imagePaths:
imgs.append(cv2.imread(file))
del imgs[0]
blob = cv2.dnn.blobFromImages(imgs, 1, (224, 224), (104, 117, 123))
# 识别
net.setInput(blob)
preds = net.forward()
for (i, img) in enumerate(imgs):
idx = np.argsort(preds[i])[-1]
text = "Label: {}-{:.2f}%".format(class_label[idx], preds[i][idx])
cv2.putText(img, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255))
cv2.imshow("figure", img)
cv2.waitKey(0)Result: