scrapy学习
一、scrapy框架介绍
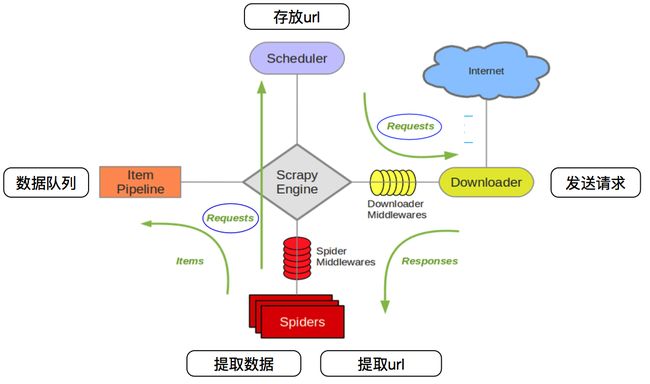
Scrapy Engine(引擎):
负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器):
它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):
负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):
它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):
它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):
你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):
你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
二、scrapy项目建立
新建项目
scrapy startproject myspider
新建爬虫文件
scrapy genspider jobbole jobbole.com
三、Item Pipeline管道
案例:
import something
class SomethingPipeline(object):
def __init__(self):
# 可选实现,做参数初始化等
# doing something
def process_item(self, item, spider):
# item (Item 对象) – 被爬取的item
# spider (Spider 对象) – 爬取该item的spider
# 这个方法必须实现,每个item pipeline组件都需要调用该方法,
# 这个方法必须返回一个 Item 对象,被丢弃的item将不会被之后的pipeline组件所处理。
return item
def open_spider(self, spider):
# spider (Spider 对象) – 被开启的spider
# 可选实现,当spider被开启时,这个方法被调用。
def close_spider(self, spider):
# spider (Spider 对象) – 被关闭的spider
# 可选实现,当spider被关闭时,这个方法被调用
四、Scrapy Spider文件介绍
scrapy.Spider是最基本的类,所有编写的爬虫必须继承这个类。
主要用到的函数及调用顺序为:
init() :
初始化爬虫名字和start_urls列表
start_requests() 调用make_requests_from url():
生成Requests对象交给Scrapy下载并返回response
parse():
解析response,并返回Item或Requests(需指定回调函数)。
Item传给Item pipline持久化 , 而Requests交由Scrapy下载,并由指定的回调函数处理(默认parse()),一直进行循环,直到处理完所有的数据为止。
主要属性和方法
name
定义spider名字的字符串。
allowed_domains
包含了spider允许爬取的域名(domain)的列表,可选。
start_urls
初始URL元组/列表。当没有制定特定的URL时,spider将从该列
表中开始进行爬取。
start_requests(self)
该方法必须返回一个可迭代对象(iterable)。该对象包含了
spider用于爬取(默认实现是使用 start_urls 的url)的第
一个Request。
当spider启动爬取并且未指定start_urls时,该方法被调用。
parse(self, response)
当请求url返回网页没有指定回调函数时,默认的Request对象回
调函数。用来处理网页返回的response,以及生成Item或者
Request对象。
log(self, message[, level, component])
使用 scrapy.log.msg() 方法记录(log)message。
五、Scrapy CrawlSpiders介绍和使用
class XcfcrawlspiderSpider(CrawlSpider):
#爬虫名称
name = 'xcfCrawlSpider'
#设置允许爬取的域
allowed_domains = ['xiachufang.com']
#设置起始的url
start_urls = ['http://www.xiachufang.com/category/']
rules = (
Rule(
LinkExtractor(allow=r'.*?/category/\d+/'),
callback='parse_item',
follow=True,
process_links='check_category_url'
),
)
rules
link_extractor:
是一个Link Extractor对象,用于定义需要提取的链接。
callback:
从link_extractor中每获取到链接得到Responses时,会调用参数所指定的值作为回调函数,该回调函数接收一个response作为其一个参数。
follow:
是一个布尔(boolean)值,指定了根据该规则从response提取的链接是否需要跟进。如果callback为None,follow 默认设置为True ,否则默认为False。
process_links:
指定spider中哪个的函数将会被调用,从link_extractor中获取到链接列表时将会调用该函数。该方法主要用来过滤。
process_request:
指定处理函数,根据该Rule提取到的每个Request时,该函数将会被调用,可以对Request进行处理,该函数必须返回Request或者None
LinkExtractorsclass scrapy.linkextractors.LinkExtractor
LinkExtractors 的目的很简单: 提取链接。
class scrapy.linkextractors.LinkExtractor(
allow = (),
deny = (),
allow_domains = (),
deny_domains = (),
deny_extensions = None,
restrict_xpaths = (),
tags = ('a','area'),
attrs = ('href'),
canonicalize = True,
unique = True,
process_value = None
)
主要参数:
allow:
满足括号中“正则表达式”的URL会被提取,如果为空,则全部匹配。
deny:
满足括号中“正则表达式”的URL一定不提取(优先级高于allow)。
allow_domains:
会提取的链接的domains。
deny_domains:
一定不会被提取链接的domains。
restrict_xpaths:
使用xpath表达式,和allow共同作用过滤链接。
六、Scrapy Request和Response相关参数介绍
Request 相关参数:
url:
就是需要请求,并进行下一步处理的url
callback:
指定该请求返回的Response,由那个函数来处理。
method:
请求一般不需要指定,默认GET方法,可设置为"GET", "POST", "PUT"等,且保证字符串大写
headers:
请求头
cookies:
cookies,模拟用户登录需要指定用户的cookies,字典dict型
meta:
比较常用,在不同的请求之间传递数据使用的。字典dict型
request_with_cookies = Request( url="http://www.example.com", cookies={'currency': 'USD', 'country': 'UY'}, meta={'dont_merge_cookies': True} )
encoding:
编码类型,使用默认的 'utf-8' 就行。
dont_filter:
表明该请求不由调度器过滤。这是当你想使用多次执行相同的请求,忽略重复的过滤器。默认为False。
errback:
指定错误处理函数
Response相关参数介绍
status:
响应码
body:
响应体
url:
响应url
self.request
(request对象)
self.headers
(响应头)