敖夜肝了这份Scrapyd核心源码剖析及爬虫项目实战部署
文章目录
- 1. Scrapyd它是什么
- 2. Scrapyd安装与启动
- 3. Scrapyd源码文件剖析
- 4. Srapyd API源码剖析
- 5. 开启Scrapyd远程访问
- 6. 安装Scrapyd-client
- 7. 修改Scrapy项目配置
- 8. 部署爬虫工程到Scrapyd
- 9. 通过API指令启动爬虫
- 10. 通过Python代码启动爬虫
- 11. 查看Scrapyd中爬虫效果
- 12. 致谢
1. Scrapyd它是什么
scrapyd它是Scrapy爬虫框架团队所开发,用于部署 Scrapy项目并让使用者能够通过网络请求向爬虫发出指令的应用程序。使用它我们可以非常方便地上传,控制爬虫和查看运行日志
可以参考Scrapyd官方文档
它便捷的功能、丰富的组件、强大的异步处理能力以及良好的技术生态,让它在爬虫界所向披靡。无论是爬虫萌新、还是纵横沙场的爬虫老司机,Scrapy都将是你职业道路上的必经之路
scrapyd跟Scrapy启动爬虫的方式其实是一样的,不同的是它提供一个JSON Web服务监听的请求。我们可以从任何一台可以连接到服务器的电脑发送请求安排爬虫运行,或者停止运行运行的爬虫。
我们可以使用它提供的API上传新爬虫而不必登录到服务器上进行操作,也可以使用API灵活的管理我们的爬虫
2. Scrapyd安装与启动
首先我们需要使用pip安装它:
pip install scrapyd
使用scrapyd命令启动服务

如上图可以看到默认情况下scrapyd回监听0.0.0.0:6800端口,在浏览器内访问http://localhost:6800/即可看到以下页面:

Jobs是爬虫运行状态及运行记录的主要观察页面,我们可以点击到Jobs里面看到是这样的:
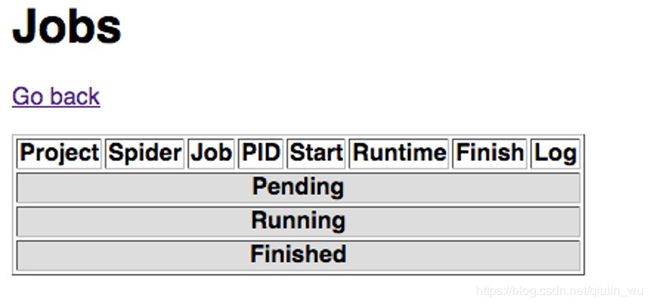
Jobs的状态分别是:
- Pending(等待中)
- Running(工作中)
- Finished(已完结)
我们可以看到,Jobs页面中包含了爬虫的运行记录、项目名称、爬虫名称、jobID、进程 ID、启动时间、运行时长、结束时间以及日志链接。根据以上信息,我们可以对爬虫的状态做个大致的了解
3. Scrapyd源码文件剖析
安装好之后,我们来到安装包下看看它的源代码目录结构是怎样的,象征性的去了解一下,下图是scrapyd下的所有文件:

通过官方文档及Github上的资料显示,了解到各个文件跟目录的大致作用,我们来看一看它们都各自承担着什么样的角色:
- scripts文件内含一个可运行文件scrapyd_run.py,这个文件是整个项目的启动文件
- init.py - scrapyd启动前的配置
- tests - 用于测试scrapyd功能的代码集
- app.py - Scrapyd应用配置文件读取并进行设置
- config.py - Scrapyd配置及相关设置
- default_scrapyd.conf - scrapyd配置文件
- eggstorage.py - 项目打包设置及版本生成
- eggutils.py - 项目打包
- environ.py - 项目打包目录读取
- interfaces.py - 处理和存储项目包的检索以及爬虫队列
- launcher.py - 执行爬虫运行、记录状态以及进程池相关
- poller.py - 队列相关
- runner.py - 任务具体执行
- scheduler.py - 任务及项目的状态与记录更新
- script.py - 用于执行Scrapy传递的命令
- spiderqueue.py - 爬虫队列相关
- sqllite.py - sqllite数据库相关
- txapp.py - 通过Twisted启动scrapyd
- utils.py - 爬虫队列、项目列表及SON 视图
- webservice.py - JSON视图以及 scrapyd 中提供的所有API
- website.py - Web视图、Home、Jobs等页面及功能
启动项目文件位于scrapyd/script目录下scrapyd_run.py,它通过载入指定txapp.py文件来启动scrapyd项目服务,scrapyd_run.py的实现代码如下:

argv是一个列表,列表的第一个元素是scrapyd_run.py的启动文件路径,而另一个元素则是文件txapp.py的路径,-n、-y参数又是什么意思呢?它们分别是:
- -n 代表不以守护进程模式启动
- -y 代表从Python文件中读取应用程序
txapp.py文件则通过调用get_application来获取scrapyd配置并通过RUN命令启动服务,负责初始化scrapyd的txapp.py代码如下:

txapp.py文件它从scrapyd项目中导入get_application方法,具体实现代码如下:
from scrapy.utils.misc import load_object
from scrapyd.config import Config
def get_application(config=None):
if config is None:
config = Config()
apppath = config.get('application', 'scrapyd.app.application')
appfunc = load_object(apppath)
return appfunc(config)
HTML视图类都写在scrapyd目录下的website.py文件中,里面有三个类:Root、Home、Jobs
我们可以看到Root类有两个方法:
- __init__方法
- update_projects方法
还有四个属性:
- launcher
- scheduler
- eggstorage
- poller
同样在__init__方法中,先读取日志与Item的目录:
logsdir = config.get('logs_dir')
itemsdir = config.get('items_dir')
当项目变动,比如增删projects,就会通过update_projects()方法进行更新:
def update_projects(self):
self.poller.update_projects()
self.scheduler.update_projects()
@property
def poller(self):
return self.app.getComponent(IPoller)
@property
def scheduler(self):
return self.app.getComponent(ISpiderScheduler)
Scrapyd的其他一些基础配置,比如读取配置文件并且将其赋值给变量:
self.debug = config.getboolean('debug', False)
self.runner = config.get('runner')
services = config.items('services', ())
我们可以看到Home类也是两个方法:
- __init__方法
- render_GET方法
Home类继承自resource.Resource,并且重写了__init__方法,以定义一个 Web 可访问资源:
def __init__(self, root, local_items):
resource.Resource.__init__(self)
self.root = root
self.local_items = local_items
另外Jobs类的话主要负责scrapyd首页爬虫运行状态展示、日志记录以及取消爬虫运行,当我们访问http://localhost:6800/jobs/时看到的界面,就是Jobs类
4. Srapyd API源码剖析
JSON API作为scrapyd使用最广泛并且最灵活的部分,它是scrapyd的核心功能。假如没有这些API的话,将在爬虫项目管理方面将变得困难,毕竟Web视图太简陋了一些
API 相关代码在webservice.py文件中
listspiders.json
class ListSpiders(WsResource):
def render_GET(self, txrequest):
args = native_stringify_dict(copy(txrequest.args), keys_only=False)
project = args['project'][0]
version = args.get('_version', [''])[0]
spiders = get_spider_list(project, runner=self.root.runner, version=version)
return {"node_name": self.root.nodename, "status": "ok", "spiders": spiders}
这个JSON API的类它干了什么?我们来捋一捋:
- 它主要继承
WsResource - 使用
render_GET来渲染数据 - 通过
native_stringify_dict方法获取请求时携带的参数 - 根据传递的爬虫项目名称获取 project 对象以及版本 Version
- 通过
get_spider_list方法以及对应参数获取爬虫名称列表 - 将爬虫列表的响应结果以 json格式返回
WsResource类的实现代码:
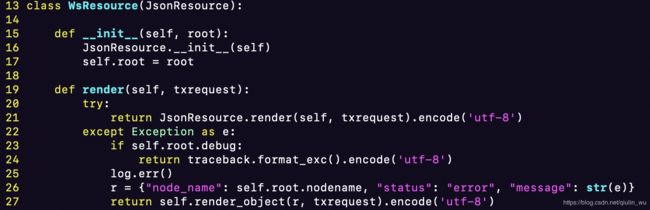
JsonResource类的实现代码:
WsResource继承自JsonResource,是大多数 API 的父类,它默认返回JSON数据JsonResource以及WsResource它们都是通过重写render以实现返回 JSON类型数据
我们可以通过自定义视图类重写render方法实现视图
render_GET方法现实现代码:
def render_GET(self, txrequest):
vars = {
'projects': ', '.join(self.root.scheduler.list_projects())
}
s = """
Scrapyd
Scrapyd
Available projects: %(projects)s
- Jobs
"""
% vars
if self.local_items:
s += 'Items '
s += """
Logs
Documentation
How to schedule a spider?
To schedule a spider you need to use the API (this web UI is only for
monitoring)
Example using curl:
curl http://localhost:6800/schedule.json -d project=default -d spider=somespider
For more information about the API, see the Scrapyd documentation
""" % vars
return s.encode('utf-8')
- vars ---- 爬虫的项目列表
- s ---- 嵌入爬虫项目列表vars的html文本
- return ---- 最后将文本数据编码后呈现到页面
get_spider_list方法主要做了什么呢?让我们看看它的主要实现代码:
def get_spider_list(project, runner=None, pythonpath=None, version=''):
"""Return the spider list from the given project, using the given runner"""
if "cache" not in get_spider_list.__dict__:
get_spider_list.cache = UtilsCache()
try:
return get_spider_list.cache[project][version]
except KeyError:
pass
if runner is None:
runner = Config().get('runner')
env = os.environ.copy()
env['PYTHONIOENCODING'] = 'UTF-8'
env['SCRAPY_PROJECT'] = project
if pythonpath:
env['PYTHONPATH'] = pythonpath
if version:
env['SCRAPY_EGG_VERSION'] = version
pargs = [sys.executable, '-m', runner, 'list']
proc = Popen(pargs, stdout=PIPE, stderr=PIPE, env=env)
out, err = proc.communicate()
if proc.returncode:
msg = err or out or ''
msg = msg.decode('utf8')
raise RuntimeError(msg.encode('unicode_escape') if six.PY2 else msg)
# FIXME: can we reliably decode as UTF-8?
# scrapy list does `print(list)`
tmp = out.decode('utf-8').splitlines();
try:
project_cache = get_spider_list.cache[project]
project_cache[version] = tmp
except KeyError:
project_cache = {version: tmp}
get_spider_list.cache[project] = project_cache
return tmp
主要逻辑根据官方的注释分析第一点则是根据指定的爬虫名返回爬虫列表,第二点则是优先从爬虫缓存列表中读取记录,如果有则直接返回结果,如无则尝试从数据库中读取。最后更新整个项目缓存并将结果返回
优先从爬虫缓存列表中读取记录,如果有则直接返回结果:
return get_spider_list.cache[project][version]
尝试从数据库中读取代码为:
env['SCRAPY_PROJECT'] = project
pargs = [sys.executable, '-m', runner, 'list']
proc = Popen(pargs, stdout=PIPE, stderr=PIPE, env=env)
out, err = proc.communicate()
更新项目缓存并将结果返回代码为:
tmp = out.decode('utf-8').splitlines();
try:
project_cache = get_spider_list.cache[project]
project_cache[version] = tmp
except KeyError:
project_cache = {version: tmp}
get_spider_list.cache[project] = project_cache
return tmp
用get_spider_list方法获取爬虫名称的速度并不快,甚至可以说有点慢,所以才会使用缓存来提升读取速度。方法中out, err = proc.communicate()这句代码的运行时长约为1.2-2.7秒,通过断点调试发现,里面调用的其他方法中使用了while以及for循环,每个循环运行的时间并不长,但是多个循环叠加在一起的时间就变成了调试记录的时间了
5. 开启Scrapyd远程访问
scrapyd安装完以后默认是只允许本机访问的,意味着当你在云服务器上使用它时,如果不开启远程访问,那你在自己的电脑上是无法访问scrapyd的服务的
如果想要保证启动scrapyd服务并且让你可以在任何地方通过ip:6800访问服务,则需要在启动前修改scrapyd的配置文件,将bind_address从原来的127.0.0.1改为0.0.0.0
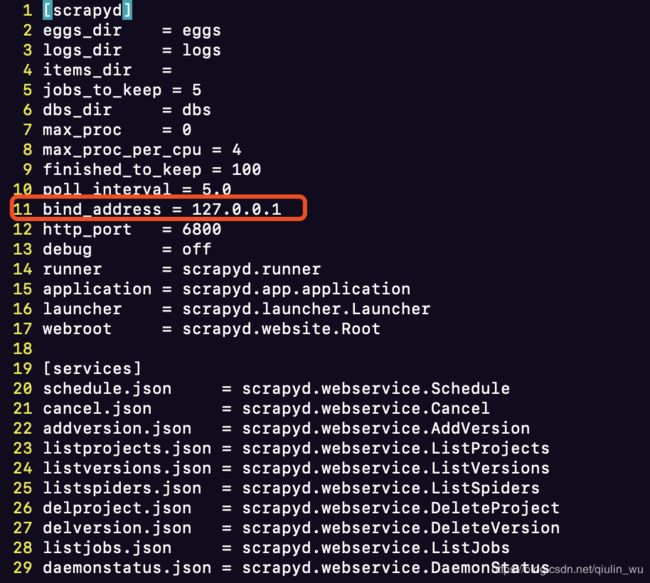
配置文件路径在Python环境中包的安装目录内,也就是/site-packages/scrapyd/下,有一个名为default_scrapyd.conf的文件,其中有个bind_address,将其修改为0.0.0.0后保存,然后在服务器上重启 Scrapyd 服务即可
6. 安装Scrapyd-client
我们安装完scrapyd以后,需要开始部署我们的爬虫工程,在这里将会使用scrapyd-client提供的scrapyd-deploy工具
pip install scrapyd-client
将scrapyd-deploy拷贝到爬虫工程目录下(scrapyd-deploy在python2.7/scrapyd-client目录下):

7. 修改Scrapy项目配置
在打包开始部署爬虫工程前,我们需要对Scrapy项目进行配置。在 Scrapy工程目录下,找到根目录的 .cfg 文件(通常是 scrapy.cfg)并用编辑器打开
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.org/en/latest/deploy.html
[settings]
default = qiche.settings
[deploy:qicheCrawler]
url = http://127.0.0.1:6800/
project = qiche
我们演示使用的项目为qiche
配置文件分为Settings级和Deploy级。Settings中指定了项目所用的配置文件,而Deploy中指定项目打包的设置
- URL - 指定部署的目标地址
- Project - 指定打包的项目
- Deploy - 指定项目别名(随意取如上:qicheCrawler)
8. 部署爬虫工程到Scrapyd
而后我们开始使用命令打包部署我们的爬虫项目,在爬虫项目的根目录(.cfg同级目录)下使用命令:
$ scrapyd-deploy qicheCrawler -p qiche
可以看到成功部署了我们的爬虫工程:

我们再次刷新一下scrapyd页面可以看到上传的爬虫项目:
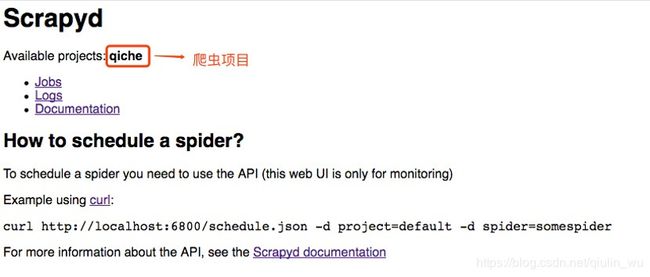
9. 通过API指令启动爬虫
scrapyd为使用者提供了Web与JSON 两种访问方式,其中web用于监视运行进程和爬虫日志、json用于向爬虫发送操作指令,比如几个常用的JSON API方法:
- schedule.json(启动爬虫)
- cancel.json(取消爬虫)
- listjobs.json(获取爬虫列表)
- delproject.json(删除爬虫项目)
现在我们上传了爬虫项目以后,开始使用API指令取启动我们的爬虫任务,发布job命令:
$ curl http://localhost:6800/schedule.json -d project=myproject -d spider=somespider
注意:确认当前系统是否有curl这个工具
返回信息如下则代表爬虫任务启动成功:
{"status": "ok", "jobid": "02cd5af5e13911e7980a0026bb56acca"}
10. 通过Python代码启动爬虫
既然它是通过网络请求来发送指令,我们可以使用requests来模拟请求的发起,新建 sendtask.py 文件并敲写代码:
#! coding: utf-8
import requests
url = "http://localhost:6800/schedule.json"
params = {"project": "qiche", "spider": "dealer"}
res = requests.post(url, data=params)
print(res.text)
通过命令python sendtask.py运行得到返回结果:
{"status": "ok", "jobid": "02cd5af5e13911e7980a0026bb56acca"}
11. 查看Scrapyd中爬虫效果
现在我们去页面刷新一下,看看我们启动的爬虫任务是否已经在运行状态中,以下两张图片是我在以前的项目文档找到的,现拿现用所以时间请忽略掉,效果都是一样的:

点击Log查看job执行情况及日志:

至此!我们的整个爬虫项目就部署完成了,我个人其实感觉原生的这个功能确实有点鸡肋了,但是话又说回来,现在很多爬虫平台内的任务部署、管理用它的还是很多因为对任务管理的API接口还是很便捷的,另外视图类我们也可以通过重写来定制自己的Web视图
12. 致谢
好了,到这里又到了跟大家说再见的时候了。我只是一个会写爬虫的段子手而已,一个希望有朝一日能够实现财富自由,能够早日荣归故里的游子罢了。希望我的文章能带给您知识,带给您帮助,带给您欢笑!同时也谢谢您能抽出宝贵的时间阅读,创作不易,如果您喜欢的话,点个赞再走吧。您的支持是我创作的动力,希望今后能带给大家更多优质的文章