Python 常见170道面试题解析(更新中...)
文章目录
- 基础
- 语言特性
- 编码规范
- 数据类型
- 字符串
- 列表
- 字典
- 综合
- 操作类题目
- 高级特性
- 正则表达式
- 其他内容
- 算法和数据结构
- 爬虫相关
- 网络编程
- 并发
- Git 面试题
基础
1.列出 5 个常用 Python 标准库?
- os:与操作系统相关联的函数,path 的 join()、split()、exists();mkdir()、listdir()、rename()、system() 等
- sys:通常用于命令行参数
- re:正则匹配,match、search、findall、sub、split、complie 等
- math:数学运算,三角函数(sin, cos, tan…)、向上向下取整(ceil, floor)、开方(sqrt) 等
- random:随机模块,random、randint、randrange 等
- calendar:日历模块
- time:时间模块,时间戳
time.time、线程休眠time.sleep()等 - datetime:处理日期时间
2.Python 内建数据类型有哪些?
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
3.简述 with 方法打开处理文件帮我我们做了什么?
打开文件在进行读写的时候可能会出现一些异常状况,如果按照常规的 f.open 写法,我们需要 try, except, finally… 做异常判断,并且文件最终不管遇到什么情况,都要执行 finally f.close() 关闭文件,with 方法帮我们实现了 finally 中 f.close()
4.列出 Python 中可变数据类型和不可变数据类型,为什么?
可变数据类型更改后地址不发生改变,不可变数据类型更改后地址发生改变
可变:
- 列表 (list)
- 字典 (dict)
- 集合 (set)
不可变:
- 数字 (int, float)
- 布尔 (bool)
- 字符串 (str)
- 集合 (set)
5.Python 获取当前日期?
import datetime
now_time = datetime.datetime.now()
# 或者
import time
now_time = time.localtime(time.time())
6.统计字符串每个单词出现的次数
(1)setdefault()的方法判断
message = 'It was a bright cold day in April, and the clocks were striking thirteen.'
count = {}
for character in message:
count.setdefault(character, 0) # 方法调用确保了键存在于 count 字典中(默认值是 0)
count[character] = count[character] + 1
print(count)
(2)传统方法
count = {}
for i in message:
if i not in count:
count[i] = 1
else:
count[i] += 1
print(count)
(3)Counter方法
from collections import Counter
count= Counter(message)
print(count)
7.用 Python 删除文件和用 linux 命令删除文件方法
- Python:
os.remove(path) - Linux:
rm -f path
8.写一段自定义异常代码
# 你随便输入一句话 看我喜不喜欢 不喜欢我就抛出异常
# 自定义异常类
class UnlikeError(BaseException):
def __init__(self,msg,text):
self.msg = msg
self.text = text
# 函数中可能抛出异常
def hello():
text = input("输入一段话:")
if text == "你真帅":
print("你说得对!")
else:
raise UnlikeError("你再看看...","另一个参数")
# 捕获异常
try:
hello()
# 获取异常对象
except UnlikeError as e:
print(e.text)
9.举例说明异常模块中 try, except, else, finally… 的相关意义
- try, except, else… :没有捕获到异常,则执行 else 语句
- try, except, finally… :不管是否捕获到异常,都执行 finally 语句
try:
num = 100
print(num)
except NameError as errorMsg:
print('产生错误了:%s'% errorMsg)
else:
print('没有捕捉到异常,则执行该语句')
try:
num = 100
print(num)
except NameError as errorMsg:
print('产生错误了:%s'% errorMsg)
finally:
print('不管是否捕捉到异常,都执行该语句')
运行结果如下:
100
没有捕捉到异常,则执行该语句
100
不管是否捕捉到异常,都执行该语句
10.遇到 bug 如何处理
- 使用 debug 模式调试
- 使用 try, except, else… 或 try, except, finally… 捕捉异常
语言特性
1.谈谈对 Python 和其他语言的区别
Python 是一门语法简洁优美,功能强大无比,应用领域非常广泛,具有强大完备的第三方库,他是一门强类型的可移植、可扩展,可嵌入的解释型编程语言,属于动态语言。
-
语言特点
简洁、优雅,省略了各种大括号和分号,还有一些关键字、类型说明 -
语言类型
解释型语言,运行的时候是逐行解释并运行,所以调试代码很方便,开发效率高 -
第三方库
python 是开源的,并且 python 的最近几年发展迅猛,应用领域很多。比如:Web、运维、自动化测试、爬虫、数据分析、人工智能;Python 具有非常完备的第三方库。 -
缺点就是 Python 的执行速度不够快
python 是一门解释型语言,所以它的速度相较于 C/C++ 这种编译型语言会慢一些,但是并不影响使用
因为现在的硬件配置都非常的高,基本没什么影响,除非是一些实时性比较强的程序可能会受到一些影响,但是也是有解决办法的,可以嵌入 C/C++代码
2.简述解释型和编译型编程语言
-
解释型语言编写的程序不需要编译,在执行的时候,专门有一个解释器能够将我们写的代码翻译成机器语言,每个语句都是执行的时候才翻译。这样解释型语言每执行一次就要翻译一次,效率比较低。
-
编译型语言写的程序执行之前,需要一个专门的编译过程,通过编译系统,把源高级程序编译成为机器语言文件,翻译只做了一次,运行时不需要翻译,所以编译型语言的程序执行效率高,但也不能一概而论,部分解释型语言的解释器通过在运行时动态优化代码,甚至能够使解释型语言的性能超过编译型语言。
3.Python 的解释器种类以及相关特点?
- CPython
C语言开发的,使用最广的解释器 - IPython
基于 CPython 之上的一个交互式计时器,交互方式增强,功能和 CPython 一样 - PyPy
目标是执行效率,采用 JIT 技术,对 python 代码进行动态编译,提高执行效率 - JPython
运行在 Java 上的解释器,直接把 python 代码编译成 Java 字节码执行 - IronPython
运行在微软 .NET 平台上的解释器,把 python 编译成. NET 的字节码
4.说说你知道的 Python3 和 Python2 之间的区别?
- print 在 Python3 中是函数必须加括号;Python2 中 print 为 class。
- Python2 中使用 xrange;Python3 使用 range。
- Python2 中默认的字符串类型默认是 ASCII;Python3 中默认的字符串类型是 Unicode。
- Python2 中1/2的结果是整型 (0);Python3 中是浮点类型 (0.5),不再区分 int 和 long。
- Python2 中声明元类:
_metaclass_ = MetaClass;
Python3 中声明元类:class newclass(metaclass = MetaClass): pass
详细了解可参考这篇文章:点此跳转
5.Python3 和 Python2 中 int 和 long 区别?
Python2 有 int 和 long 类型。int 类型最大值不能超过 sys.maxint,而且这个最大值是平台相关的。可以通过在数字的末尾附上一个L来定义长整型,显然,它比 int 类型表示的数字范围更大。在 Python3 里,只有一种整数类型 int,大多数情况下,和 Python2中的长整型类似。
6.xrange 和 range 的区别?
python3 中不存在 python2 的 xrange();python3 的 range 就是 python2 的 xrange。
- 在 python2 中,range 返回一个列表,即 range(3) 返回 [0,1,2],
而 xrange 返回一个 xrange 对象,即 xrange(3) 返回 iterator 对象,它与 Java 迭代器类似,并在需要时生成数字。 - 如果我们需要多次迭代相同的序列,我们更喜欢 range(),因为 range 提供了一个静态列表。而 xrange() 每次重建序列。
- xrange() 不支持切片和其他列表方法。
- xrange() 的优点是,当任务迭代大范围时,它可以节省内存。
- 在 python3 中,范围函数现在执行 xrange 在 python 2 中的功能,因此为了保持代码的可移植性,我们可能希望坚持使用范围。所以 python 3 的范围函数是来自 python 2 的 xrange。
编码规范
7.什么是 PEP8?
PEP 是 Python Enhancement Proposal 的缩写,翻译过来就是 Python 增强建议书;
PEP8 是 python 的一种编码规范,具体如下:
- 缩进。4个空格的缩进(编辑器都可以完成此功能),不使用 tab,更不能混合使用 tab 和空格。
- 每行最大长度79,换行可以使用反斜杠,最好使用圆括号。换行点要在操作符的后边敲回车。
- 类和 top-level 函数定义之间空两行;类中的方法定义之间空一行;函数内逻辑无关段落之间空一行;其他地方尽量不要再空行。
- 模块导入的顺序:按标准、三方和自己编写顺序依次导入,之间空一行。
- 不要在一句 import 中多个库,比如
import os, sys不推荐 - 避免不必要的空格
- 注释必须要有
- 函数命名要遵循规范
- 尽可能使用 ‘is’ ‘is not’ 取代 ‘==’,比如
if x is not None要优于if x。 - 使用基于类的异常,每个模块或包都有自己的异常类,此异常类继承自 Exception。
- 异常中 try 的代码尽可能少。
8.了解 Python 之禅么?
适当回答几条即可:点此跳转
9.了解 docstring 么?
-
DocStrings 文档字符串是一个重要工具,用于解释文档程序,帮助你的程序文档更加简单易懂。
我们可以在函数体的第一行使用一对三个单引号 ‘’’ 或者一对三个双引号 “”" 来定义文档字符串。
你可以使用__doc__(注意双下划线)调用函数中的文档字符串属性。 -
DocStrings 文档字符串使用惯例:它的首行简述函数功能,第二行空行,第三行为函数的具体描述。
10.了解类型注解么?
用 : 类型 的形式指定函数的参数类型,用 -> 类型 的形式指定函数的返回值类型。
例如:
def add(x:int, y:int) -> int:
return x + y
然后特别要强调的是,Python 解释器并不会因为这些注解而提供额外的校验,没有任何的类型检查工作。也就是说,这些类型注解加不加,对你的代码来说没有任何影响
详细了解可参考:点此跳转
11.例举你知道 Python 对象的命名规范,例如方法或者类等?
适当回答几条即可:点此跳转
12.Python 中的注释有几种?
- 单行注释:
# - 多行注释:
""" """
13.如何优雅的给一个函数加注释?
函数注释通常在 def 语句下方,第一行表示函数用法,接下来对函数接受的参数进行解释,最后对函数的返回值进行注释,方便他人理解函数的用法
详细了解可参考这篇文章:点此跳转
14.如何给变量加注释?
- 单行注释:
# - 多行注释:
""" """
15.Python 代码缩进中是否支持 Tab 键和空格混用。
需要统一使用 tab 或统一使用空格,不能混用
Python 是一门用空格缩进来区分代码层次的语言,其实 Python 并没有强制要求你用 Tab 缩进或者用空格缩进,甚至空格按几个都没有强制要求,但在 PEP8 中建议了使用4个空格作为缩进
16.是否可以在一句 import 中导入多个库?
可以是可以,但是不推荐。因为一次导入多个模块可读性不是很好,所以一行导入一个模块会比较好。同样的尽量少用 from modulename import *,因为判断某个函数或者属性的来源有些困难,不方便调试,可读性也降低了。
17.在给 py 文件命名的时候需要注意什么?
给文件命名的时候不要和标准库库的一些模块重复,比如 abc。 另外要名字要有意义,不建议数字开头或者中文命名。
18.例举几个规范 Python 代码风格的工具:
- pylint
- flake8
- YAPF,谷歌开发的代码规范工具
- Black,依赖 Python3.6+ 的第三方库,可以直接将原代码变为符合 PEP8 标准的代码
数据类型
字符串
19.列举 Python 中的基本数据类型?
- 整型 int
- 浮点型 float
- 布尔型 bool
- 字符串 str
20.如何区别可变数据类型和不可变数据类型?
可变数据类型更改后地址不发生改变,不可变数据类型更改后地址发生改变
21.将 “hello world” 转换为首字母大写 "Hello World"
strA = 'hello world'
print(strA.title())
# 或
print(strA.capitalize())
22.如何检测字符串中只含有数字?
使用 isdigit() 函数,返回一个 True 或 False
23.将字符串"ilovechina"进行反转
- 使用切片:
"ilovechina"[::-1] - 使用
reversed()方法:''.join(reversed('ilovechina'))
注意:
- reverse() :函数用于反向列表中元素,仅适用于列表
- reversed():函数是返回序列 seq 的反向访问的迭代子。参数可以是列表,元组,字符串
24.Python 中的字符串格式化方式你知道哪些?
- 使用 % 号
'Hey %s, there is a 0x%x error!' % (name, errno)
'Hey %(name)s, there is a 0x%(errno)x error!' % {"name": name, "errno": errno } - 使用 format()
'Hello, {}'.format(name)
'Hey {name}, there is a 0x{errno:x} error!'.format(name=name, errno=errno) - 字符串插值/f-Strings(Python 3.6+)
f'Hello, {name}!'
25.有一个字符串开头和末尾都有空格,比如“ adabdw ”,要求写一个函数把这个字符串的前后空格都去掉。
- 使用 replace() 方法
" adabdw ".replace(" ", "")将空格替换为空 - 使用切片
" adabdw "[1:7]
26.获取字符串”123456“最后的两个字符。
"123456"[4:] 或者 "123456"[-2:]
27.一个编码为 GBK 的字符串 S,要将其转成 UTF-8 编码的字符串,应如何操作?
a= "S".encode("gbk").decode("utf-8",'ignore')
print(a)
28
(1).s="info:xiaoZhang 33 shandong",用正则切分字符串输出 ["info", "xiaoZhang", "33", "shandong"]
(2).a = "你好 中国 ",去除多余空格只留一个空格。
- 使用 replace() 方法
"你好 中国 ".replace(" ", "")将空格替换为空
29
(1).怎样将字符串转换为小写
strA = "ARHststh"
print(strA.lower())
(2).单引号、双引号、三引号的区别?
三种引号都表示字符串
- 单引号表示的字符串里可包含双引号,当然不能包含单引号
- 双引号表示的字符串里可以包含单引号,字符串都只能有一行
- 三个引号能包含多行字符串,同时常常出现在函数的声明的下一行,来注释函数的功能,与众不同的地方在于,这个注释作为函数的一个默认属性,可以通过
函数名.__doc__来访问
列表
30.已知 AList = [1, 2, 3, 1, 2],对 AList 列表元素去重,写出具体过程。
AList = [1, 2, 3, 1, 2]
print(list(set(AList)))
31.如何实现 "1,2,3" 变成 [“1”,“2”,“3”]
32.给定两个 list,A 和 B,找出相同元素和不同元素
A=[1,2,3,4,5,6,7,8,9]
B=[1,3,5,7,9]
print('A、B中相同元素:')
print(set(A)&set(B))
print('A、B中不同元素:')
print(set(A)^set(B))
33.[[1, 2], [3, 4], [5, 6]] 一行代码展开该列表,得出 [1, 2, 3, 4, 5, 6]
1)利用推导式运行过程:for i in a ,每个 i 是 [1, 2], [3, 4], [5, 6], for j in i,每个 j 就是1, 2, 3, 4, 5, 6, 合并后就是结果
a=[[1,2],[3,4],[5,6]]
x=[j for i in a for j in i] #这个的解析过程是:从 a 中取出每一个值付给 i,然后从 i 中取出每一个值赋值给 j 然后输出 j 的结果
print(x) # [1, 2, 3, 4, 5, 6]
2)将列表转成 numpy 矩阵,通过 numpy 的flatten()方法
import numpy as np
b=np.array(a).flatten().tolist()
print(b)
3)j for i in a for j in i等于:
list=[]
for i in a:
for j in i:
list.append(j)
print(list)
34.合并列表 [1, 5, 7, 9] 和 [2, 2, 6, 8]
listA = [1, 5, 7, 9]
listB = [2, 2, 6, 8]
listA.extend(listB)
print(listA)
35.如何打乱一个列表的元素?
import random
a = [1, 2, 3, 4, 5]
random.shuffle(a)
print(a)
字典
36.字典操作中 del 和 pop 有什么区别
-
del() 函数无返回值
del dict删除字典 dict,但这会引发一个异常,因为用执行 del 操作后字典不再存在
del dict['Name']删除字典 dict 键 ‘Name’ -
pop() 函数有返回值,即删除的那个值
pop(key[,default])删除字典给定键 key 所对应的值,返回值为被删除的值。key 值必须给出。 否则,返回 default 值。
37.按照字典的内的年龄排序
d1 = [
{'name': 'alice', 'age':38},
{'name': 'bob', 'age':18},
{'name': 'carl', 'age':28},
]
使用 sort 排序:
d1.sort(key=lambda x: x['age'])
38.请合并下面两个字典 a = {“A”: 1, “B”: 2}, b = {“C”: 3, “D”: 4}
-
使用dict(a,**b)方法
a = {"A": 1, "B": 2} b = {"C": 3, "D": 4} print(dict(a, **b)) -
使用update()函数
a = {"A": 1, "B": 2} b = {"C": 3, "D": 4} c = {} c.update(a) c.update(b) print(c) -
遍历 key, value,转换成列表,再做加法,删除列表转换字典的方法 d.items()
e = dict(list(a.items()) + list(b.items())) print(e)
39.如何使用生成式的方式生成一个字典,写一段功能代码。
40.如何把元组 (“a”, “b”) 和元组 (1, 2),变为字典 {“a”: 1, “b”: 2}
print(dict(zip(("a", "b"), (1, 2))))
综合
41.Python 常用的数据结构的类型及其特性?
- 列表 list:线性;格式为 [123, “abc”];可以通过索引访问元素,对所有元素的访问叫做遍历
- 元组 tuple:线性;格式为 (123, “abc”),一个元素也需要逗号 (123, );和 list 很相似,但不能修改,只能查找 index、统计 count
- 字典 dict:非线性;格式为键值对 {“name”: “jack”, “age”: 18};无顺序,键不重复、值可以重复,根据键取值
- 集合 set:非线性;格式为 (123, “abc”);非线性、无顺序、不重复,可用来去重
42.如何交换字典 {“A”: 1,“B”: 2} 的键和值?
A: {1: 0, 2: 0, 3: 0}
B: {"a": 0, "b": 0, "c": 0}
C: {(1, 2): 0, (2, 3): 0}
D: {[1, 2]: 0, [2, 3]: 0}
43.Python 里面如何实现 tuple 和 list 的转换?
listA = [1, 2, 3]
tupleA = tuple(listA)
tupleB = (123, )
listB = list(tupleB)
44.我们知道对于列表可以使用切片操作进行部分元素的选择,那么如何对生成器类型的对象实现相同的功能呢?
使用自带的 itertools 库进行实现,具体实现方式 itertools.islice(生成器对象,起始位置,结束位置),即可实现切片功能
45.请将 [i for i in range(3)] 改成生成器
iter(range(3))
46.a=“hello” 和 b=“你好” 编码成 bytes 类型
a.encode()
b.encode()
47.下面的代码输出结果是什么?
a = (1, 2, 3, [4, 5, 6, 7], 8)
a[2] = 2
元组为不可变数据类型,所以会报错:TypeError: 'tuple' object does not support item assignment
48.下面的代码输出的结果是什么?
a = (1, 2, 3, [4, 5, 6, 7], 8)
a[3][0] = 2
print(a)
结果为:(1, 2, 3, [2, 5, 6, 7], 8)
操作类题目
49.Python 交换两个变量的值
a = 123
b = "abc"
a, b = b, a
print(a, b) # abc 123
50.在读文件操作的时候会使用 read、readline 或者 readlines,简述它们各自的作用
- read()方法:read([size])方法从文件当前位置起读取size个字节;若无参数size,则表示读取至文件结束为止,它范围为字符串对象
- readline()方法:该方法每次读出一行内容,所以,读取时占用内存小,比较适合大文件,该方法返回一个字符串对象。
- readlines()方法:读取整个文件所有行,保存在一个列表(list) 变量中,每行作为一个元素,但读取大文件会比较占内存
51.json 序列化时,可以处理的数据类型有哪些?如何定制支持 datetime 类型?
字符串、数字(整数和浮点数)、字典、列表、布尔值、None。使用 strftime 将 datetime 格式化为标准字符串类型即可
52.json 序列化时,默认遇到中文会转换成 unicode,如果想要保留中文怎么办?
使用 json.dumps 函数时,添加参数 ensure_ascii=False,如果想显示的更美观,可以添加 indent=2 参数,会在每个 key 值前添加两个空格
53.有两个磁盘文件 A 和 B,各存放一行字母,要求把这两个文件中的信息合并(按字母顺序排列),输出到一个新文件 C 中。
读取两个文件,利用 split 函数将字符串切割成列表,再将两个列表合并,利用 sort 函数对合并后的列表进行排序,最后将列表内容拼接成字符串写入即可
54.如果当前的日期为 20190530,要求写一个函数输出 N 天后的日期,(比如 N 为 2,则输出 20190601)。
利用自带的 datetime 库即可实现
55.写一个函数,接收整数参数 n,返回一个函数,函数的功能是把函数的参数和 n 相乘并把结果返回。
def fun(n):
def fun1(n, arg):
return n * arg
return fun1(n)
56.下面代码会存在什么问题,如何改进?
def strappend(num):
str = "first"
for i in range(num):
str += str(i)
return str
会报类型错误:TypeError: 'str' object is not callable ,没有对 num 进行校验,num 应该为一整数,添加一个 type 类型校验
57.一行代码输出 1-100 之间的所有偶数。
print(list(i for i in range(1, 101) if i%2 == 0))
58.with 语句的作用,写一段代码?
常用于打开文本后的自动关闭,例如:
with open("file_name", 'w') as f:
...
59.python 字典和 json 字符串相互转化方法
使用 json 库:
- 字典 -> json:json.dumps(dict)
- json -> 字典:json.loads(json_file)
60.请写一个 Python 逻辑,计算一个文件中的大写字母数量
with open(file_name, 'r') as f:
count = 0
for i in f.read():
if i.isupper():
count += 1
print('大写字母数量为%d'%count)
61. 请写一段 Python连接 Mongo 数据库,然后的查询代码。
import pymongo
db_configs = {
'type': 'mongo',
'host': '地址',
'port': '端口',
'user': 'spider_data',
'passwd': '密码',
'db_name': 'spider_data'
}
class Mongo():
def __init__(self, db=db_configs["db_name"], username=db_configs["user"],
password=db_configs["passwd"]):
self.client = pymongo.MongoClient(f'mongodb://{db_configs["host"]}:db_configs["port"]')
self.username = username
self.password = password
if self.username and self.password:
self.db1 = self.client[db].authenticate(self.username, self.password)
self.db1 = self.client[db]
def find_data(self):
# 获取状态为 0 的数据
data = self.db1.test.find({"status": 0})
gen = (item for item in data)
return gen
if __name__ == '__main__':
m = Mongo()
print(m.find_data())
62.说一说 Redis 的基本类型。
- String
- Hash
- List
- Set
- ZSet
参考这篇文章:点此跳转
63. 请写一段 Python连接 Redis 数据库的代码。
import redis
class Database:
def __init__(self):
self.host = 'localhost'
self.port = 6379
def write(self,website,city,year,month,day,deal_number):
try:
key = '_'.join([website,city,str(year),str(month),str(day)])
val = deal_number
r = redis.StrictRedis(host=self.host,port=self.port)
r.set(key,val)
except Exception, exception:
print exception
def read(self,website,city,year,month,day):
try:
key = '_'.join([website,city,str(year),str(month),str(day)])
r = redis.StrictRedis(host=self.host,port=self.port)
value = r.get(key)
print value
return value
except Exception, exception:
print exception
if __name__ == '__main__':
db = Database()
db.write('meituan','beijing',2013,9,1,8000)
db.read('meituan','beijing',2013,9,1)
上面操作是先写入一条数据,然后再读取,如果写入或者读取数据太多,那么我们最好用批处理,这样效率会更高。
import redis
import datetime
class Database:
def __init__(self):
self.host = 'localhost'
self.port = 6379
self.write_pool = {}
def add_write(self,website,city,year,month,day,deal_number):
key = '_'.join([website,city,str(year),str(month),str(day)])
val = deal_number
self.write_pool[key] = val
def batch_write(self):
try:
r = redis.StrictRedis(host=self.host,port=self.port)
r.mset(self.write_pool)
except Exception, exception:
print exception
def add_data():
beg = datetime.datetime.now()
db = Database()
for i in range(1,10000):
db.add_write('meituan','beijing',2013,i,1,i)
db.batch_write()
end = datetime.datetime.now()
print end-beg
if __name__ == '__main__':
add_data()
参考这篇文章:点此跳转
64. 请写一段 Python 连接 MySQL 数据库的代码。
import MySQLdb
conn=MySQLdb.connect(host='127.0.0.1',port=3306,user='root',passwd='199331',db='test',charset='utf8')
cur=conn.cursor()
cur.execute("""
create table if not EXISTS user
(
userid int(11) PRIMARY KEY ,
username VARCHAR(20)
)
""")
for i in range(1,10):
cur.execute("insert into user(userid,username) values('%d','%s')" %(int(i),'name'+str(i)))
conn.commit()
cur.close()
conn.close()
65.了解 Redis 的事务么?
Redis 中的事务提供了一种将多个命令请求打包,然后一次性、顺序性执行多个命令的机制,并且在事务指向期间,服务器不会中断事务而改去执行其他客户端的命令请求,它会将事务中的所有命令都执行完毕,然后才去处理其他客户端的请求。
参考这篇文章:点此跳转
66.了解数据库的三范式么?
经过研究和对使用中问题的总结,对于设计数据库提出了一些规范,这些规范被称为范式 一般需要遵守下面3范式即可:
- 第一范式(1NF):强调的是列的原子性,即列不能够再分成其他几列。
- 第二范式(2NF):首先是 1NF,另外包含两部分内容,一是表必须有一个主键;二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。
- 第三范式(3NF):首先是 2NF,另外非主键列必须直接依赖于主键,不能存在传递依赖。即不能存在:非主键列 A 依赖于非主键列 B,非主键列 B 依赖于主键的情况。
参考这篇文章:点此跳转
67.了解分布式锁么?
多进程并发执行任务时,需要保证任务的有序性或者唯一性,所以就要用到分布式锁
- 同一时刻只能存在一个锁
- 需要解决意外死锁问题,也就是锁能超时自动释放
- 支持主动释放锁
68.用 Python 实现一个 Reids 的分布式锁的功能。
参考文章:点此跳转
69.写一段 Python 使用 Mongo 数据库创建索引的代码。
下面的代码给 user 的 user_name 字段创建唯一索引:
import pymongo
mongo = pymongo.Connection('localhost')
collection = mongo['database']['user']
collection.ensure_index('user_name', unique=True)
高级特性
70.函数装饰器有什么作用?请列举说明?
装饰器可以在不修改函数的情况下,对函数的功能进行补充,例如对函数接受的参数进行检查
更加详细的内容:点此跳转
71.Python 垃圾回收机制?
python 采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅的策略
最简单的,Python 每个变量上都有一个引用计数器,当引用计数器为0时,自动销毁变量。复杂一些的,例如存在互相引用的情况,这时 Python 依靠两个链表(标记-清除算法)进行垃圾回收。点击这里获得更详细的资料
72.魔法函数 __call__ 怎么使用?
__call__ 是将类创建为一个实例进行调用,多用在类装饰器中。可以将逻辑代码写在 __call__下,不需要实例化类也可直接使用其中的代码。
73.如何判断一个对象是函数还是方法?
可以使用 type() 函数进行判断,函数与方法本质上没有差别,仅仅通过是否与类进行绑定进行区分。绑定后通过类实例化进行调用则为方法,未绑定直接调用即为函数。
74.@classmethod 和 @staticmethod 用法和区别
- classmethod 必须实例化类以后才能使用,同时第一个参数由 self 变化为 cls
- staticmethod 称为静态方法类似于全局函数,不需要实例化也能调用。
75.Python 中的接口如何实现?
在类中提前设置好方法,利用 NotImplementedError 错误,当子类没有覆写方法的时候进行报错。也可使用 @abstractmethod 对需要覆写的方法进行装饰,任何没有覆写该方法的子类都会报错。
76.Python 中的反射了解么?
反射是用于在类中寻找值的一种方式,有以下几种用法:
- hasattr(class, key):在实例中寻找是否存在key名的函数或是变量返回布尔值。
- getattr(class, key, tips):获得实例中变量或是方法的内存地址,可传入第三个参数修改报错提示。
- setattr(class, name, function):将函数以 name 为名字传入类中,通过 class.name(class) 的方式进行调用,setattr(class, name, value) 传入变量及变量值,以 class.name 的形式调用。
- delattr(class, name):删除类中变量,不能删除函数。
77.metaclass 作用?以及应用场景?
metaclass 就是元类,元类是用来创建类的,也就是类的类
metaclass 即元类,metaclass 是类似创建类的模板,所有的类都是通过他来 create 的(调用new),这使得你可以自由的控制创建类的那个过程,实现你所需要的功能。 我们可以使用元类创建单例模式和实现 ORM 模式。
详细了解:点此跳转
78.hasattr() getattr() setattr()的用法
- hasattr(object,name):查询类中是否存在符合关键字的函数或者方法,返回布尔值。
- getattr(object, name, [default]):查询函数是否存在指定名字的变量或是方法,返回变量的值或者函数内存地址,若不存在报错或是返回 default 中的自定义内容。
79.请列举你知道的 Python 的魔法方法及用途。
__init__()构造函数:
初始化数据并快速创建对象
默认隐藏无参数,只能有一个构造函数
无返回值,只能创建对象时调用__del__()析构函数:对象死亡前调用 一般用于存储数据__str__:返回字符串,强调可读性__repr__:返回字符串,强调准确性__str__与__repr__:
都返回字符串,前者面向用户,后者面向程序员
如果两者同时存在,str会覆盖repr,优先执行__new__():可产生一个 “cls” 对应的实例,一定要有返回__eq__():判断是否相等__doc__:类的文档/多行注释__bases__:获得基类信息,结果为元组__dict__:获得对象属性的字典键值信息__class__:获得对象的类__name__:获得执行文件名字__file__:获得文件路径
80.如何知道一个 Python 对象的类型?
使用 type() 函数
81.Python 的传参是传值还是传址?
- 不可变参数用值传递,通过拷贝进行传递的
- 可变参数是引用传递的
82.Python 中的元类(metaclass)使用举例
可以使用元类实现一个单例模式,代码如下
class Singleton(type):
def __init__(self, *args, **kwargs):
print("in __init__")
self.__instance = None
super(Singleton, self).__init__(*args, **kwargs)
def __call__(self, *args, **kwargs):
print("in __call__")
if self.__instance is None:
self.__instance = super(Singleton, self).__call__(*args, **kwargs)
return self.__instance
class Foo(metaclass=Singleton):
pass # 在代码执行到这里的时候,元类中的__new__方法和__init__方法其实已经被执行了,而不是在 Foo 实例化的时候执行。且仅会执行一次。
foo1 = Foo()
foo2 = Foo()
print(foo1 is foo2)
83.简述 any() 和 all() 方法
any(object) 与 all(object) 区别:
- any 主要判断对象中是否全为空值(0、’’、None、Flase);若对象内全部为空值则返回 False,否则返回 True
- all 则是判断对象中是否存在空值;只要存在任一个空值则返回 False,否则返回 True
84.filter 方法求出列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
list(filter(lambda x:x if x%2 == 1 else None, a))
85.什么是猴子补丁?
在运行代码的过程中,对某个方法或者属性进行替换的行为称为猴子补丁。例如某个模块中有一个查询方法,开发中查询数据库中某个数据。在测试的过程中,不想查询该数据库了,则在测试代码中覆盖这个方法,这种行为称为猴子补丁。
具体内容可以参考:猴子补丁相关知识点
86.在 Python 中是如何管理内存的?
参考71题的垃圾回收方式,Python 主要靠引用计数、垃圾回收、内存池管理进行内存管理。
其中内存池较为复杂,这里给出博客链接,供大家参考:内存池图文解释。这篇博客讲的比较深,另外从内存池的设计方向展示了内存池的作用与设计原理,可以收藏了慢慢看。
87.当退出 Python 时是否释放所有内存分配?
不是的,循环引用其他对象或引用自全局命名空间的对象的模块,在 Python 退出时并非完全释放。另外,也不会释放 c 库保留的内存部分
正则表达式
88.
(1) 使用正则表达式匹配出 百度一下,你就知道
pattern = "(.*?) "
ma = pattern.match(<html><h1>www.baidu.com</html>)
print(ma.group(1))
(2) a=“张明 98 分”,用 re.sub,将 98 替换为 100。
re.sub('98', '100', a)
89.正则表达式匹配中 (.*) 和 (.*?) 匹配区别?
.*单个字符匹配任意次,即贪婪匹配.*?满足条件的情况只匹配一次,即最小匹配
90.写一段匹配邮箱的正则表达式
\w[-\w.+]*@([A-Za-z0-9][-A-Za-z0-9]+\.)+[A-Za-z]{2,14}
其他内容
91.解释一下 Python 中 pass 语句的作用?
- 空语句,什么也不做,表示占位
- 在特别的时候用来保证格式或是语义的完整性
92.简述你对 input()函数的理解
在 Python3 中,input() 函数接受一个标准输入数据,返回为 string 类型。不管我们输入的回答是什么,不管你输入的是整数,还是字符串,input() 函数的输入值(搜集到的回答),永远会被【强制性】地转换为【字符串】类型。(Python3 固定规则)
93.Python 中的 is 和 ==
- == :判断 值,比较两个对象是否相等
- is :判断 地址,比较两个引用是否指向了同一个对象(引用比较)
94.Python 中的作用域
作用域指的是函数名或者变量名的寻找顺序,
优先级从高到低分别为:局部作用域(子函数)>> 闭包函数外的函数中(父函数)>> 全局作用域(当前Python模块)>> 内建作用域(Python标准库)
95.三元运算写法和应用场景?
形如 a= 'a' if b>1 else 'b',想用都能用,我个人感觉没有什么特定场景,属于一种偷懒写法。
96.了解 enumerate 么?
内置函数,用来枚举迭代器,返回结果为 (index, value),可以方便的获得迭代器的下标和值,也可以接受第三个参数,用于修改起始下标,
for index, value in enumerate(list, 1):
print(index, value)
则开始的下标从1开始。
97.列举 5 个 Python 中的标准模块
- os:与操作系统相关联的函数,path 的 join()、split()、exists();mkdir()、listdir()、rename()、system() 等
- sys:通常用于命令行参数
- re:正则匹配,match、search、findall、sub、split、complie 等
- math:数学运算,三角函数(sin, cos, tan…)、向上向下取整(ceil, floor)、开方(sqrt) 等
- random:随机模块,random、randint、randrange 等
- calendar:日历模块
- time:时间模块,时间戳
time.time、线程休眠time.sleep()等 - datetime:处理日期时间
98.如何在函数中设置一个全局变量
使用 global 关键字,例如 global a; a=a+1这样即可在函数中修改全局变量 a 的值。
99.pathlib 的用法举例
这个库是用来消除 windows 系统和 Linux 系统路径分隔符不同的问题,实际使用过程中个人感觉意义不大,有兴趣的可以看 官方文档 了解一下。
100.Python 中的异常处理,写一个简单的应用场景
对文件的读写经常因为编码问题报错,这里使用 try …except的方法进行一个简单处理:
try:
open('filename', 'r') as f:
f.readlines()
except:
print('error')
finally:
f.close()
参考资料
101.Python 中递归的最大次数,那如何突破呢?
默认最大递归次数为1000,通过以下代码进行修改:
import sys
sys.setrecursionlimit(10000) # set the maximum depth as 10000
根据系统不同还存在解释器上限,windows 下最大迭代次数约 4400次,linux 下最大迭代次数约为24900次
102.什么是面向对象的 mro
MRO(Method Resolution Order):方法解析顺序。指对象在继承或多次继承后,方法的解析顺序。详细的解析可以 看这里
103.isinstance 作用以及应用场景?
用于判断对象是否与已知对象类型一致,功能上类似 type() 函数,type 不能分别是否继承,isinstance 可以,具体解析 参考这里
104.什么是断言?应用场景?
断言也是一种异常处理的方式,可以判断关键字后方的表达式是否为真,若为真则继续执行,若为假则抛出异常。
常用于一些数据的检验。具体应用场景 参考这里
105.lambda 表达式格式以及应用场景?
labmda 又被称为匿名函数,用于一些简单的函数处理,例如:lambda x:x^2,这里将传入的 x 平方后返回,常常和循环结合在一起使用。
106.新式类和旧式类的区别
写法上不同,多重继承的属性搜索算法改变了,具体可以 参考这里
107.dir()是干什么用的?
显示对象的属性和方法。
108.一个包里有三个模块,demo1.py, demo2.py, demo3.py,但使用 from tools import * 导入模块时,如何保证只有 demo1、demo3 被导入了。
from tools import demo1, demo3
109.列举 5 个 Python 中的异常类型以及其含义
- AttributeError 对象没有这个属性
- NotImplementedError 尚未实现的方法
- StopIteration 迭代器没有更多的值
- TypeError 对类型无效的操作
- IndentationError 缩进错误
参考资料
110.copy 和 deepcopy 的区别是什么?
深拷贝:
- 将原对象的“ 值/元素 ”赋给新对象,新对象中元素的地址与原对象的 地址不同
- 是对原对象 所有层次 的拷贝(递归)
- 与原对象没有任何关系,如果原对象发生变化,深拷贝后的新对象 不会发生改变
浅拷贝:
- 将原对象的 引用 赋给新对象,新对象中元素的地址与原对象的 地址相同
- 是对原对象 顶层 的拷贝(表面一层)
- 由于只拷贝了表面一层,当原对象中的嵌套对象发生改变时,新对象也 会发生改变
111.代码中经常遇到的 *args, **kwargs 含义及用法。
- *args:元组参数,参数格式化存储在一个元组中,长度没有限制,必须位于普通参数和默认参数之后。
- **kwargs:字典参数,参数格式化存储在一个字典中,必须位于参数列表的最后面。
112.Python 中会有函数或成员变量包含单下划线前缀和结尾,和双下划线前缀结尾,区别是什么?
单下划线前缀表示是私有变量或函数,按照约定不能直接调用,双下划线前缀代表类的私有方法,只有类自身可以访问,子类也不行。双下划线前缀结尾代表特殊方法,除了 Python 规定的函数以外,尽量不要使用。
113.w、a+、wb 文件写入模式的区别
- r : 读取文件,若文件不存在则会报错
- w: 写入文件,若文件不存在则会先创建再写入,会覆盖原文件
- a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾
- rb,wb:分别于 r, w 类似,但是用于读写二进制文件
- r+ : 可读、可写,文件不存在也会报错,写操作时会覆盖
- w+ : 可读,可写,文件不存在先创建,会覆盖
- a+ :可读、可写,文件不存在先创建,不会覆盖,追加在末尾
114.举例 sort 和 sorted 的区别
- sort 是应用在 list 上的方法,sorted 可以对 所有可迭代的对象 进行排序操作。
- list 的 sort 方法返回的是 对已经存在的列表进行操作,而内建函数 sorted 方法 返回的是一个新的 list,而不是在原来的基础上进行的操作。
115.什么是负索引?
Python 中的序列索引可以是正也可以是负。如果是正索引,0是序列中的第一个索引,1是第二个索引。如果是负索引,(-1)是最后一个索引而(-2)是倒数第二个索引。
116.pprint 模块是干什么的?
提供了打印出任何Python数据结构类和方法
详细了解请参考:点此跳转
117.解释一下 Python 中的赋值运算符
等号左边为变量名,右边为值,将右边的值赋给左边的变量。右边如果是表达式,会将结果赋予左边的变量。赋值运算符有(=,+=,-=,//=,%=,*=,/=)。具体看这里
118.解释一下 Python 中的逻辑运算符
- and:和
- or:或
- not:非
具体看这里
119.讲讲 Python 中的位运算符
- &:1 1为1,其他为0
- |:0 0为0,其他为1
- ~:按位取反,看符号位,求补码,加一
- ^:相等为0,不等为1
>>:右移位,数值变小<<:左移位,数值变大
具体看这里
120.在 Python 中如何使用多进制数字?
在数字前添加前缀,0b 或 0B 前缀表示二进制数,前缀 0o 或 0O 表示8进制数,前缀 0x 或者 0X 表示16进制数。
121.怎样声明多个变量并赋值?
a, b = 1, 2
算法和数据结构
122.已知:
AList = [1, 2, 3]
BSet = {1, 2, 3}
(1) 从 AList 和 BSet 中 查找 4,最坏时间复杂度那个大?(2) 从 AList 和 BSet 中 插入 4,最坏时间复杂度那个大?
(1) 对于查找,列表和集合的最坏时间复杂度都是 O(n),所以一样的。 (2) 列表操作插入的最坏时间复杂度为 O(n),集合为 O(1),所以 Alist 大。 set 是哈希表所以操作的复杂度基本上都是 O(1)。
123.用 Python 实现一个二分查找的函数
def binary_search(arr, target):
n = len(arr)
left = 0
right = n-1
while left <= right :
mid = (left + right)//2
if arr[mid] < target:
left = mid + 1
elif arr[mid] > target:
right = mid - 1
else:
print(f"index:{mid},value:{arr[mid]}")
return True
return False
if __name__ == '__main__':
l = [1,3,4,5,6,7,8]
binary_search(l,8)
124.Python 单例模式的实现方法
实现单例模式的方法有多种,之前再说元类的时候用 call 方法实现了一个单例模式,另外 Python 的模块就是一个天然的单例模式,这里我们使用 new 关键字来实现一个单例模式。
"""
通过 new 函数实现简单的单例模式。
"""
class Book:
def __new__(cls, title):
if not hasattr(cls,"_ins"):
cls._ins = super().__new__(cls)
print('in __new__')
return cls._ins
参考这篇文章:点此跳转
125.使用 Python 实现一个斐波那契数列
斐波那契数列:数列从第 3 项开始,每一项都等于前两项之和。
def fibonacci(num):
"""
获取指定位数的列表
:param num:
:return:
"""
a, b = 0, 1
l = []
for i in range(num):
a, b = b, a + b
l.append(b)
return l
if __name__ == '__main__':
print(fibonacci(10))
详细了解可查看这篇文章:点此跳转
126.找出列表中的重复数字
准备一个空列表,循环目标列表里的元素,不重复的丢进新列表里,查到重复的就把下标和值打印出来。
127.找出列表中的单个数字
遍历列表,找到相等的输出下标和值。
128.写一个冒泡排序
listA = [3,7,2,9,8,5]
for i in range(len(listA)-1): # 0 1 2 3 4
for j in range(len(listA)-1-i):
if listA[j] > listA[j+1]:
listA[j],listA[j+1] = listA[j+1],listA[j]
print(listA)
运行结果为:
[2, 3, 5, 7, 8, 9]
129.写一个快速排序
listA = [4, 3, 9, 6, 5, 8]
for i in range(len(listA) - 1): # 0 1 2 3 4
# 选择一个值!!!
x = i
for j in range(i + 1, len(listA)):
if listA[x] > listA[j]:
x = j
listA[i], listA[x] = listA[x], listA[i]
print(listA)
print("结果!", listA)
运行结果为:
结果: [3, 4, 5, 6, 8, 9]
130.写一个拓扑排序
from collections import defaultdict
class Graph:
def __init__(self,vertices):
self.graph = defaultdict(list)
self.V = vertices
def addEdge(self,u,v):
self.graph[u].append(v)
def topologicalSortUtil(self,v,visited,stack):
visited[v] = True
for i in self.graph[v]:
if visited[i] == False:
self.topologicalSortUtil(i,visited,stack)
stack.insert(0,v)
def topologicalSort(self):
visited = [False]*self.V
stack =[]
for i in range(self.V):
if visited[i] == False:
self.topologicalSortUtil(i,visited,stack)
print (stack)
g= Graph(6)
g.addEdge(5, 2);
g.addEdge(5, 0);
g.addEdge(4, 0);
g.addEdge(4, 1);
g.addEdge(2, 3);
g.addEdge(3, 1);
print ("拓扑排序结果:")
g.topologicalSort()
运行结果为:
拓扑排序结果:
[5, 4, 2, 3, 1, 0]
详细了解:点此跳转
131.Python 实现一个二进制计算
132.有一组“+”和“-”符号,要求将“+”排到左边,“-”排到右边,写出具体的实现方法。
133.单链表反转
134.交叉链表求交点
135.用队列实现栈
136.找出数据流的中位数
137.二叉搜索树中第 K 小的元素
爬虫相关
138.在 requests 模块中,requests.content 和 requests.text 什么区别
requests.content 是二进制字符串,requests.text 返回的是普通字符串。
139.简要写一下 lxml 模块的使用方法框架
使用 etree 对 html 文件进行解析,获取对应的 tag 和属性。
140.说一说 scrapy 的工作流程
-
首先 Spiders(爬虫)将需要发送请求的 url(requests) 经 ScrapyEngine(引擎)交给 Scheduler(调度器)。
-
Scheduler(排序,入队)处理后,经 ScrapyEngine,DownloaderMiddlewares (可选,主要有User_Agent, Proxy代理) 交给 Downloader。
-
Downloader 向互联网发送请求,并接收下载响应(response)。将响应(response)经ScrapyEngine,SpiderMiddlewares (可选)交给 Spiders。
-
Spiders 处理 response,提取数据并将数据经 ScrapyEngine 交给 ItemPipeline 保存(可以是本地,可以是数据库)。
-
提取 url 重新经 ScrapyEngine 交给 Scheduler 进行下一个循环。直到无 Url 请求程序停止结束。
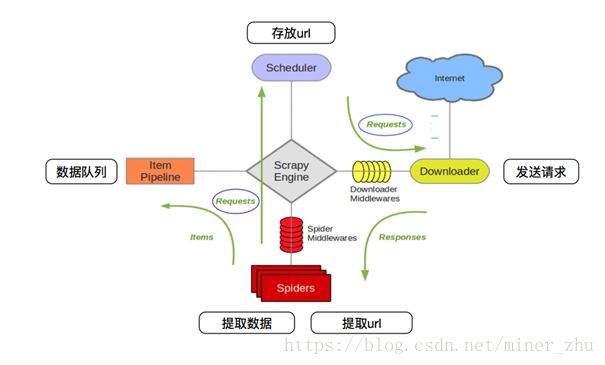
141.scrapy 的去重原理
- scrapy 本身自带有一个中间件;
- scrapy 源码中可以找到一个 dupefilters.py 去重器;
- 需要将 dont_filter 设置为 False 开启去重,默认是 False 去重,改为 True, 就是没有开启去重;
- 对于每一个 url 的请求,调度器都会根据请求得相关信息加密得到一个指纹信息,并且将指纹信息和 set() 集合中的指纹信息进行比对,如果 set() 集合中已经存在这个数据,就不在将这个 Request 放入队列中;
- 如果 set() 集合中没有存在这个加密后的数据,就将这个 Request 对象放入队列中,等待被调度。
142.scrapy 中间件有几种类,你用过哪些中间件
scrapy 的中间件理论上有三种 (Schduler Middleware, Spider Middleware, Downloader Middleware), 在应用上一般有以下两种:
-
爬虫中间件 Spider Middleware
主要功能是在爬虫运行过程中进行一些处理 -
下载器中间件 Downloader Middleware
主要功能在请求到网页后,页面被下载时进行一些处理
143.你写爬虫的时候都遇到过什么?反爬虫措施,你是怎么解决的?
限制访问次数,检验浏览器头,异步加载,验证码,限制 IP 。
限制访问速度的加延时,浏览器头加 headers 参数,异步加载抓包找访问地址,验证码接打码平台或者用自动化框架过,IP 用代理。
144.为什么会用到代理?
很多网站限制 IP 访问的速度和次数,导致大规模采集的时候影响速度,也可能因为多次访问被封禁 IP,所以用代理的方式绕过。
145.代理失效了怎么处理?
一般尝试三次,失败了重新丢回队列中,换个代理地址继续用。
146.列出你知道 header 的内容以及信息
- user-agent:浏览器头信息
- refer:表示从哪个网页跳转的
147.说一说打开浏览器访问 百度一下,你就知道 获取到结果,整个流程。
先向 DNS 服务器查询对应 IP ,浏览器访问 IP ,网站响应若是 HTTPS 的验证一下证书,然后 TCP 三次握手开始传数据。
148.爬取速度过快出现了验证码怎么处理
- 设置延时
- 使用打码平台
- 尝试登录后爬取
- 挂代理多 IP 爬。
149.scrapy 和 scrapy-redis 有什么区别?为什么选择 redis 数据库?
-
scrapy 是一个 python爬虫框架,爬取效率极高,具有高度定制性,但是不支持分布式;
而 scrapy-redis 是一套基于 redis 数据库、运行在 scrapy 框架之上的组件,可以让 scrapy 支持分布式策略,Slaver 端共享 Master 端 redis 数据库里的 item 队列、请求队列和请求指纹集合。 -
为什么选择 redis 数据库,因为 redis 支持主从同步,而且数据都是缓存在内存中的,所以基于 redis 的分布式爬虫,对请求和数据的高频读取效率非常高。
150.分布式爬虫主要解决什么问题
- IP
- 带宽
- CPU
- IO
151.写爬虫是用多进程好?还是多线程好? 为什么?
限制爬虫的两方面,一个是网络请求速度,这个通过线程来提升。另一个是硬盘读写,这个用多进程解决。
IO 密集型代码(文件处理、网络爬虫等),多线程能够有效提升效率(单线程下有 IO 操作会进行 IO 等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费 CPU 的资源,从而能提升程序执行效率)。在实际的数据采集过程中,既考虑网速和响应的问题,也需要考虑自身机器的硬件情况,来设置多进程或多线程
152.解析网页的解析器使用最多的是哪几个
- BeautifulSoup4
- xpath (lxml 库)
- 正则表达式
153.需要登录的网页,如何解决同时限制 ip, cookie, session(其中有一些是动态生成的)在不使用动态爬取的情况下?
自动化框架
154.验证码的解决(简单的:对图像做处理后可以得到的,困难的:验证码是点击,拖动等动态进行的?)
简单的图像识别,困难的自动化框架,再不行接打码平台。
155.使用最多的数据库(mysql,mongodb,redis 等),对他的理解?
参考这篇文章:点此跳转
网络编程
156.TCP 和 UDP 的区别?
-
连接方面区别
TCP 面向连接(如打电话要先拨号建立连接)。
UDP 是无连接的,即发送数据之前不需要建立连接。 -
安全方面的区别
TCP 提供可靠的服务,通过 TCP 连接传送的数据,无差错,不丢失,不重复,且按序到达。
UDP 尽最大努力交付,即不保证可靠交付。 -
传输效率的区别
TCP 传输效率相对较低。
UDP 传输效率高,适用于对高速传输和实时性有较高的通信或广播通信。 -
连接对象数量的区别
TCP 连接只能是点到点、一对一的。
UDP 支持一对一,一对多,多对一和多对多的交互通信。
157.简要介绍三次握手和四次挥手
参考这篇文章:点此跳转
158.什么是粘包? socket 中造成粘包的原因是什么? 哪些情况会发生粘包现象?
并发
159.举例说明 conccurent.future 的中线程池的用法
160.说一说多线程,多进程和协程的区别。
参考这篇文章:点此跳转
161.简述 GIL
技术进步,CPU从原来的单核变为了多核,为了防止程序在多线程操作的时候同时执行,加了一个GIL锁,保证在同一时刻只能有一个线程在运行程序。
参考这篇文章:点此跳转
162.进程之间如何通信
一种是采用队列 Queue 的方式,多用于多进程通信。通过 put 和 get 方法向队列中放入值和取出值实现通信。Pipe 常于两个进程间通信,利用 send 和 recv 发送和接收变量。
参考这篇文章:点此跳转
163.IO 多路复用的作用?
节约资源,一个进程监听多个文件的状态,利用轮询代替一对一监控。
参考这篇文章:点此跳转
164.select、poll、epoll 模型的区别?
- select 利用系统自身调度系统,生成一个数组,将监控的文件描述符都放进去,进行遍历监控,文件就绪时传递给程序进行处理。
- poll 和 select 类似,但由于select 类型是数组,存在上限,而 poll 使用链表,没有上限,同时效率比起 select 更高。
- epoll 改进了前两种方式,利用回调函数的方法,将就绪的文件描述符添加进一个数组中,只对这个数组进行遍历。
参考这篇文章:点此跳转
165.什么是并发和并行?
- 并发就是多个线程轮流执行
- 并行就是多个线程同时执行。
166.一个线程 1 让线程 2 去调用一个函数怎么实现?
167.解释什么是异步非阻塞?
发送方发送数据后不等回复就继续做自己的事,接收方接到数据后一边进行数据处理一边做自己的事,处理结束后将结果传回给发送方。这样的方式称为异步非阻塞,同理有同步阻塞/非阻塞,异步阻塞/非阻塞。
参考这篇文章:点此跳转
168.threading.local 的作用
用于保存一个全局变量,这个变量只能在当前的线程中进行访问。
Git 面试题
169.说说你知道的 git 命令
-
初始化
git init -
添加到暂存盘
git add . -
提交
git commit -m "提示信息" -
查看信息
git log -
查看相关历史信息
git reflog -
测试工作区操作
git checkout --文件名 -
回退版本
git reset --hard 版本id -
查看分支
git branch -
创建分支
git branch -
切换分支
git checkout -
创建+切换分支
git checkout -b -
合并某分支到当前分支
git merge -
删除分支
git branch -d -
添加远程仓库
git remote add origin [email protected]:xxx/xxx.git -
推送本地代码到远程
git push -u origin master -f
170.git 如何查看某次提交修改的内容
- 首先,需要通过
git log打印所有 commit 记录 - 找到你想查看的哪次 commit 的 commitid。
- 查看修改:
git show commitId - 查看某次 commit 中具体某个文件的修改:
git show commitId fileName