KNN(K近邻算法)
一、KNN基本知识
KNN算法 -------- 做分类(二分类、多分类)、也可以做回归
===================================
KNN的三要素:
K值的影响:
1. K值过小,可能会导致过拟合
2. K值过大,可能会导致欠拟合
距离的计算方式:
一般使用欧氏距离(欧几里得距离);
决策函数的选择:
在分类模型中,主要使用多数表决法或者加权多数表决法;在回归 模型中,主要使用平均值法或者加权平均值法。KNN算法知识脉络:
-1. KNN算法是什么?KNN算法的基本原理是什么?
-2. 损失函数是什么?
-3. KNN伪代码怎么写的?基于Python实现KNN分类算法(多数投票的分类算法)
-4. 你觉得有哪些因素可能影响KNN算法模型效果呢?你觉得KNN算法有什么缺点?怎么来解决?
-5. 什么是KD树?KD树的创建策略?KD树的查找方式?1. KNN算法是什么?KNN算法的基本原理是什么?
KNN是有监督学习的K近邻的机器学习算法,K值得是最近的K个样本的意思;它的思想是 ‘近朱者赤近墨者黑’,若果空间中
某些样本具有相近的特征属性(样本距离比较近),我们可以认为它们的目标属性Y是相近的。我们可以用已有的最近K个样本
的目标属性来预测(分类:加权多票表决,回归:加权均值)待测样本的目标属性。
2. 损失函数是什么?
KNN算法没有损失函数
3. KNN伪代码怎么写的?基于Python实现KNN分类算法(多数投票的分类算法)
pass
4. 你觉得有哪些因素可能影响KNN算法模型效果呢?你觉得KNN算法有什么优缺点?怎么解决?
该算法适用于对样本容量比较大的类域进行自动分类。
4.1 你觉得有哪些因素可能影响KNN算法模型效果呢?
① KNN三要素的选择:
K值的选择、距离计算方式、决策函数决策方式
② 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少),较少样本类别预测较差
4.2 你觉得KNN算法有什么优缺点?
4.2.1 KNN算法的优点:
① 思想简单,理论成熟,即可以做分类也可以做回归
② 可以天然解决多分类问题
③ 可以用非线性数据分类,即数据与数据存在交叉时效果也不错。
④ 训练时间复杂度为比SVM低
⑤ 准确度高,对异常点不敏感
4.2.1 你觉得KNN算法有什么优缺点?怎么解决?
① KNN算法的计算量很大(每次预测都需要计算所有的距离)
解决方案:KD树
② 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少),较少样本类别预测较差
解决方案:特征工程解决数据不均衡的方法(上下采样 ...)
③ 需要大量的内存;
5. 什么是KD树?KD树的创建策略?KD树的查找方式?
5.1 KD树是一个树状的数据结构,他是为了解决KNN算法样本数量过大时,计算距离最近K个样本速度过慢的问题。
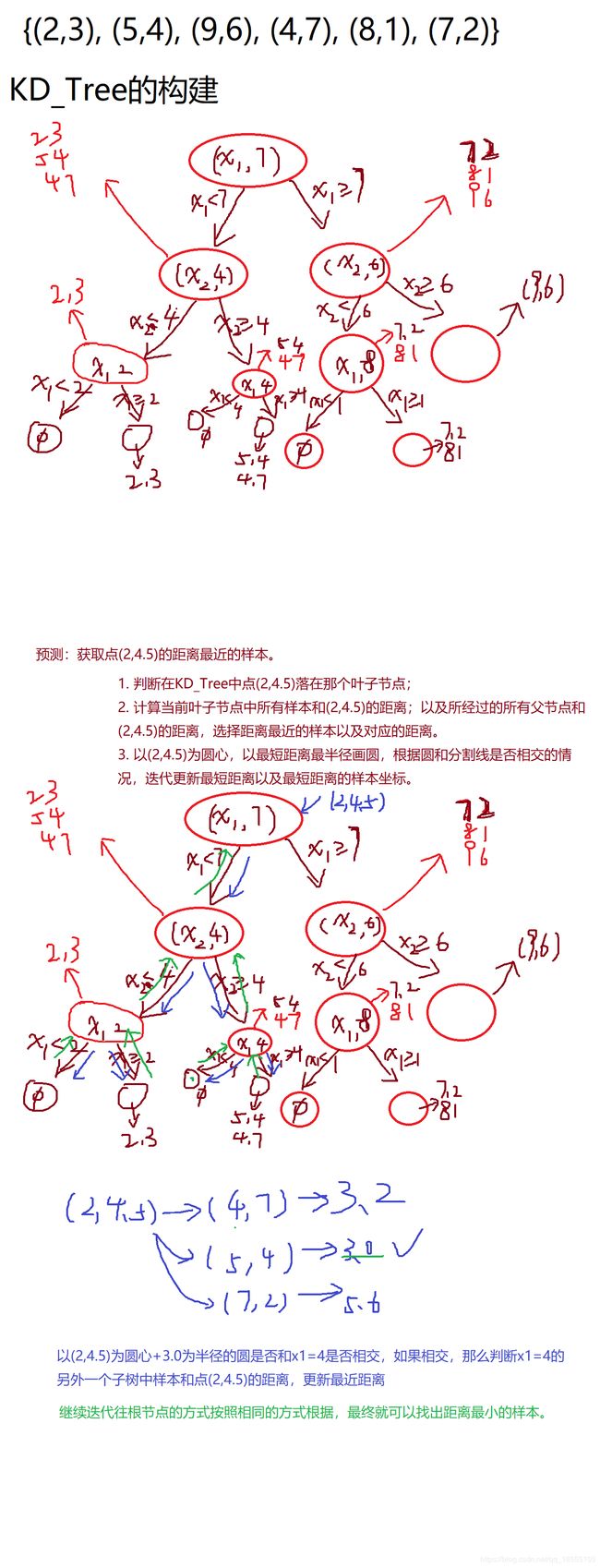
5.2 KD Tree构建方式:
KD树采用从m个样本的n维特征中,分别计算n个特征取值的方差,用方差最大 的第k维特征nk作为根节点。对于这个特征,选择取
值的中位数nkv作为样本的划分点,对于小于该值的样本划分到左子树,对于大于等于该值的样本划分到右子 树,对左右子树采用
同样的方式找方差最大的特征作为根节点,递归即可产生 KD树。
5.3 KD树的查找方式
pass
二、 KNN算法
1、KNN算法的基本原理

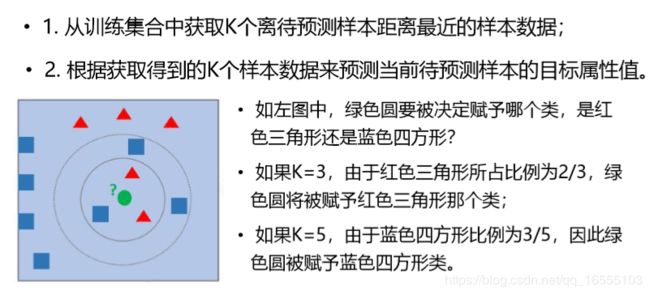
2、KNN三要素

3、KNN分类预测规则

4、KNN回归预测规则

5、KNN算法实现方式

三、KD树
1、KD树的目的:KD树是KNN算法为了快速求取K近邻样本的一种算法。
2、KD数的使用场景:用于样本数量比较大时,KKN算法快速计算距离最近K个样本的手段。
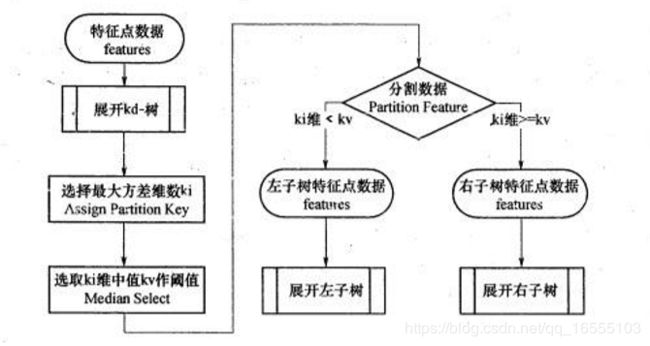
3、KD Tree构建方式:
KD树采用从m个样本的n维特征中,分别计算n个特征取值的方差,用方差最大 的第k维特征nk作为根节点。对于这个特征,选择取
值的中位数nkv作为样本的划分点,对于小于该值的样本划分到左子树,对于大于等于该值的样本划分到右子 树,对左右子树采用
同样的方式找方差最大的特征作为根节点,递归即可产生 KD树。
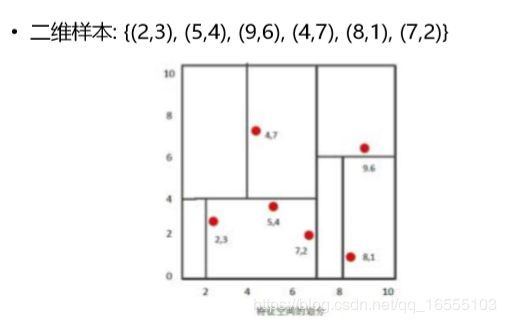
- 例:
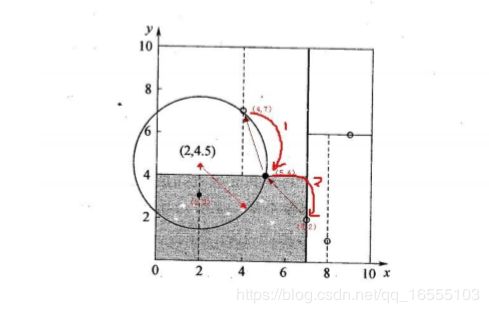
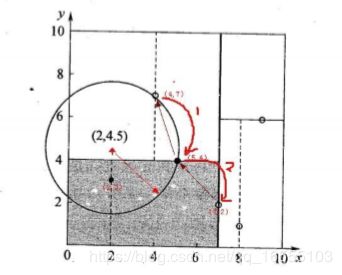
(2)KD tree查找最近邻
• 当我们生成KD树以后,就可以去预测测试集里面的样本目标点了。对于 一个目标点,我们首先在KD树里面找到包含目标点的叶子节
点。以目标 点为圆心,以目标点到叶子节点中样本实例的最短距离为半径,得到一 个超球体,最近邻的点一定在这个超球体内
部。然后返回叶子节点的父 节点,检查另一个子节点包含的超矩形体是否和超球体相交,如果相交 就到这个子节点寻找是否有
更加近的近邻,有的话就更新最近邻。如果不 相交那就简单了,我们直接返回父节点的父节点,在另一个子树继续搜 索最近邻。
当回溯到根节点时,算法结束,此时保存的最近邻节点就是 最终的最近邻。
• 找到所属的叶子节点后,以目标点为圆心,以目标点到最近样本 点(一般为当前叶子节点中的其它训练数据或者刚刚经过的父节点)
为半径画圆,从最近样本点往根节点进行遍历,如果这个圆和分 割节点的分割线有交线,那么就考虑分割点的另外一个子树。如
果在遍历过程中,找到距离比刚开始的样本距离近的样本,那就 进行更新操作。
• 一直迭代遍历到根节点上,结束循环找到最终的最小距离的样本。
- KD tree查找最近邻的图解
四、KNN的伪代码 与 sklearn 代码
1、基于python的伪代码
KNN伪代码:(将执行过程转换为代码的执行方式<代码+注释的形式>)
-1. 简单来写
def fit(self, X, Y, k=3):
self.X_train = X
self.Y_train = Y
self.k = k
def predict(self, X):
result = []
# 遍历所有的待预测样本,产生预测值,并将预测值保持到result临时集合中
for x in X:
# a. 计算当前样本x到训练数据集中的所有样本的距离
# 并返回样本的下标和距离组成的集合,eg,[(距离1,样本1下标), (距离2, 样本2下标).....]
all_distinces = self.calc_distinces(x)
# b. 按照距离的远近对样本做一个排序的操作(升序)
sort(all_distinces, key=lambda t: t[0])
# c. 获取距离最近的K个样本对应的距离和下标组成的集合
top_k_distinces = all_distinces[:self.k]
# d. 从最近的样本距离、下标集合中获取样本下标
top_k_indexs = list(map(lambda t:t[1], top_k_distinces))
# e. 获取K个邻居样本对应的目标属性Y
tmp_y = self.Y[top_k_indexs]
# f. 统计一下临时集合tmp_y中各个类别取值出现的数量
label_2_count_dict = self.calc_label_2_count(tmp_y)
# g. 将字典转换为数组
label_2_count_list = list(label_2_count_dict.items())
# h. 对数据按照出现次数做一个排序(升序)
sort(label_2_count_list, lambda t:t[1])
# i. 获取出现次数最多的那个类别作为预测值
tmp_label = label_2_count_list[-1][0]
# j. 将预测值添加到集合中
result.append(tmp_label)
return result
------------------------------ 简化版伪代码 ---------------------------------------------
def fit(self, X, Y, k=3):
self.X_train = X
self.Y_train = Y
self.k = k
def predict(self, X):
result = []
# 遍历所有的待预测样本,产生预测值,并将预测值保持到result临时集合中
for x in X:
# a. 获取和当前样本最相似的K个邻近样本的下标值
top_k_indexs = self.fetch_nearst_neighbors(x)
# b. 获取K个邻居样本对应的目标属性Y
tmp_y = self.Y[top_k_indexs]
# c. 计算K个样本中各个类别出现的概率,并获取概率最大的类别作为预测值
tmp_label = self.fetch_max_proba_label(tmp_y)
# d. 将预测值添加到集合中
result.append(tmp_label)
return result2、基于python的代码实现 KNN
数据:
======================= 基于python的KNN算法的伪代码 =====================================
#_*_coding:utf-8_*_
# 刘康
import warnings,os,re
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
class Knn_code():
def __init__(self):
pass
def fit(self,X,Y,k):
'''
初始化样本
:param X: 已知特征属性矩阵 X
:param Y: 已知目标矩阵 Y
:param k: KNN算法k值
:return:
'''
self.X=X
self.Y=Y
self.k =k
def calc_distance(self,once):
'''
计算每一个待测样本与一直样本的距离的字典(key是已知样本的下标,value是与该样本的距离)
'''
distance_dict = {}
for index in range(X.shape[0]):
once_distance = np.sqrt(sum((X[index] - once)**2))
distance_dict[index] = once_distance
# print(distance_dict)
return distance_dict
def calc_label_counts_dict(self,label):
'''
计算每个标签类型的数量,返回一个字典(key是每一个标签类型,value是该类型的数目)
'''
counts_dict = dict(pd.Series(label).value_counts())
# print(counts,type(counts)) # Series 可以直接转化为字典
return counts_dict
def predict(self,X_predict):
'''
对给定数据进行数据类型预测
:param X_predict: 待预测 的样本的特征属性 矩阵X
:return:
'''
result = []
# 遍历所有的待预测样本,预测所有样本的类型,并保存带result列表中
for once in X_predict:
#计算被遍历单个样本与已知样本之间的距离字典(key是每个样本的索引,values与每个样本的距离)
distance_dict = self.calc_distance(once)
#将上述距离字典根据值进行升序排序,得到元组格式,即前k个是距离待测样本距离最近的k个样本
distance_list = list(sorted(distance_dict.items(),key=lambda x:x[1]))
# print(distance_list)
#利用上诉元组键值对获取k个最近样本的索引列表
index_list = list(map(lambda t:t[0],distance_list))[:self.k]
# 根据上述索引取出对应样本的目标属性
label_Y = self.Y[index_list]
# print(label_Y)
# 统计k个最近样本目标属性出现类别次数的字典
Y_count_dict = self.calc_label_counts_dict(label_Y)
# 将字典根据值的大小排序,返回列表
Y_count_list = list(sorted(Y_count_dict.items(),key = lambda t:t[1]))
# 获取上述列表最后一个元素中的类型
Y_type = Y_count_list[-1][0]
# print(Y_type)
# 将改样本的类型预测保存
result.append(Y_type)
return np.array(result)
if __name__ == '__main__':
df_data = pd.read_csv('./iris.data',sep=',',header=None)
print(df_data.info(),df_data.head())
# 清洗数据
df_data_label = df_data.iloc[:,-1]
df_data_label_list = np.unique(df_data_label)
# print(df_data_label_list)
label_transform_dict = dict(zip(df_data_label_list,range(len(df_data_label_list))))
# print(label_transform_dict)
label_list = [label_transform_dict[i] for i in df_data_label]
# print(label_list)
# 提取特征属性X 目标属性Y
X = np.array(df_data.iloc[:,:-1]) # 二维
Y = np.array(label_list) # 一维
knn = Knn_code()
knn.fit(X,Y,10)
# print(X)
# print('='*100)
# print(knn.Y)
# 带预测样本
X_test = np.array(df_data.iloc[:,:-1])
# print(X_test)
result_list = knn.predict(X_predict=X_test)
print('样本真实值结果是:{}'.format(Y))
print('样本预测的结果是:{}'.format(result_list))
3、基于sklearn库的KNN代码
(1)ROC曲线与AUC值
=============================== ROC曲线 与 AUC值 ======================================
import matplotlib.pyplot as plt
from sklearn import metrics
if __name__ == '__main__':
------------------ 实际的类别y
y_true = [0, 0, 1, 1, 0, 1, 0]
------------------ 决策函数值,或者是样本属于y=1的概率值
y_scoreProd = [0.2, 0.45, 0.55, 0.68, 0.51, 0.9, 0.1]
------------------ 计算fpr, tpr以及阈值
fpr, tpr, thresholds = metrics.roc_curve(y_true, y_scoreProd)
print("FPR的值:{}".format(fpr))
print("TPR的值:{}".format(tpr))
print("阈值:{}".format(thresholds))
auc = metrics.auc(x=fpr, y=tpr)
print("面积:{}".format(auc))
plt.plot([0, 0, 0, 1], [0, 1.0 / 3, 1.0, 1.0], 'r-o') ----------- 'r-o' 画出红线带点的图
plt.show()(2)sklearn库的KNN代码
========================== 基于sklearn 库的 KNN算法模型 ===========================
#_*_coding:utf-8_*_
import os,re,warnings
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import sklearn
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import f1_score,accuracy_score,precision_score,recall_score,
confusion_matrix,classification_report
# 1、加载数据
df_data = pd.read_csv('./iris.data',sep=',',header=None)
# print(df_data.info(),df_data.head())
# 2、清洗数据
df_label_Y = df_data.iloc[:,-1]
le = LabelEncoder()
le.fit(df_label_Y)
df_Y_trans = le.transform(df_label_Y) # 自动根据分类将标签进行编码 0,1,2,3 ......
# print(df_Y_trans)
# 3、提取特征属性X 目标属性Y
X = df_data.iloc[:,:-1]
Y = df_Y_trans
# print(X,Y)
# 4、分割训练集与测试集
# 5、特征工程
# 6、构建KNN模型
'''
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights='uniform',
algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=1, **kwargs)
'''
KNN_model = KNeighborsClassifier(n_neighbors=10,weights='distance',algorithm='kd_tree')
# 7、训练模型
KNN_model.fit(X,Y)
# 8、模型评估、参数查看、可视化
Y_predict = KNN_model.predict(X)
print('KNN模型的正确率:{}'.format(KNN_model.score(X,Y)))
# print('KNN模型的召回率:{}'.format(recall_score(Y,Y_predict))) # 注意默认的 二分类不能计算多分类的召回率
print('KNN模型测试集的概率:{}'.format(KNN_model.predict_proba(X))) #返回的是一个 N * 类型数量列 的矩阵
'''
# kneighbors:从训练数据中获取样本X的邻近样本,获取n_neighbors参数多个样本,并且根据参数return_distance
决定是否返回距离值
# 当前参数的情况下,返回的是一个二元组,二元组的第一个元素是一个集合,集合中存储的是邻近样本的距离;
第二个元素还是一个集合,存储的是邻近样本的下标
kneighbors = algo.kneighbors(X=x_test, n_neighbors=9, return_distance=True)
'''
X_test = X.iloc[:3,:]
print(X_test.shape)
kneighbors = KNN_model.kneighbors(X=X_test,n_neighbors=3,return_distance=True)
print('KNN模型测试集的最近的k个样本的距离、下标:{}'.format(kneighbors)) #
print(kneighbors) # 返回的是一个索引值
'''
# kneighbors_graph, 对于X而言,从训练数据中获取距离最近的n_neighbors多个样本,将X和这些样本之间认为是可以连通的,
故将其值设置为1
# mode给定值的设置方式,connectivity表示设置为1,distance表示设置为距离值
# 返回对象表示的是X和训练数据中哪些样本是可以连通的
# 列的数目是训练数据特征向量的数目,行的数目是x_test的样本数目
kneighbors_graph(X=None, n_neighbors=None, mode='connectivity')
'''
kneighbors_graph = KNN_model.kneighbors_graph(X=X_test,n_neighbors=2,mode='distance')
print('连接矩阵为:{}'.format(kneighbors_graph))
'''
连接矩阵为: (0, 0) 0.0
(0, 17) 0.09999999999999998
(1, 1) 0.0 -------- 前三行是第一个样本的三个最近样本的链接情况,最前面是下标,后
面是距离
(1, 45) 0.14142135623730986
(2, 2) 0.0
(2, 47) 0.14142135623730978
'''
# 混淆矩阵
print('KNN模型的混淆矩阵为:{}'.format(confusion_matrix(Y,Y_predict)))
# 9、模型部署持久化
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report, confusion_matrix
from sklearn import metrics
if __name__ == '__main__':
# 1. 加载数据
df = pd.read_csv('../datas/iris.data', header=None, names=['A', 'B', 'C', 'D', 'E'])
# 删除一个类别的数据
df = df[df.E != 'Iris-setosa']
df.info()
"""
最终目的,是将X和Y转换为numpy数组的形式,并且值全部转换为数值型
-1. 因为需要获取X和Y,所以这里第一步从df中提取对应的X、Y, 并将X和Y转换为numpy数组
-2. 需要将Y中的字符串使用数字进行替换,eg:"Iris-setosa": 0, "Iris-versicolor": 1, "Iris-virginica": 2
"""
# 获取X和Y
columns = df.columns
X = np.array(df[columns[:-1]])
Y = np.array(df[columns[-1]])
# 使用LabelEncoder对Y进行编码
le = LabelEncoder()
le.fit(Y)
Y = le.transform(Y)
print("Y中的类别:{}".format(le.classes_))
# print("反转恢复:{}".format(le.inverse_transform([0, 1])))
# 2. 获取X的最后两列数据作为原始的特征属性X
# 按照索引获取所有行的最后两列的数据
X = X[:, -2:]
# print(X)
# 3. 构建模型
algo = KNeighborsClassifier(n_neighbors=9)
# 4. 模型训练
algo.fit(X, Y)
# 5. 看模型效果
Y_predict = algo.predict(X)
print("准确率:{}".format(algo.score(X, Y)))
print("训练数据上的分类报告:\n{}".format(classification_report(Y, Y_predict)))
# 更改阈值(我希望将所有有病的数据全部预测正确)
threshold = 0.77777778
# 获取所有的预测概率
test_predict_prob = algo.predict_proba(X)
# 获取下标为1的那一列概率
test_predict_prob = test_predict_prob[:, 1]
# 做一个布尔索引,将所有值大于等于阈值的区域设置为4.0,小于阈值的区域设置为2.0
test_predict_prob[test_predict_prob >= threshold] = 1
test_predict_prob[test_predict_prob < threshold] = 0
print("测试数据上的混淆矩阵:\n{}".format(confusion_matrix(Y, Y_predict)))
print("更改阈值后测试数据上的混淆矩阵:\n{}".format(confusion_matrix(Y, test_predict_prob)))
-------------------------- 多分类的情况不适合以下方法更改阈值、计算roc曲线,这里只谈论二分类更改阈值 ---------
# 需要计算一下AUC和ROC的值
# fpr、tpr和阈值 --> 需要实际值y和决策函数或者预测概率
test_predict_prob = algo.predict_proba(X)
print(test_predict_prob)
# 将类别y=1当做正例则获取预测为类别y=1的概率作为auc计算过程中的阈值列表对象
test_predict_prob = test_predict_prob[:, 1]
# 计算fpr、tpr和阈值
fpr, tpr, thresholds = metrics.roc_curve(Y, test_predict_prob)
# 计算AUC面积
auc = metrics.auc(x=fpr, y=tpr)
print("AUC面积:{}".format(auc))
print(thresholds)
plt.plot(fpr, tpr, 'r-o')
plt.show()============================ KNN多分类 ROC曲线与AUC值 ==================================
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report, confusion_matrix
from sklearn import metrics
if __name__ == '__main__':
# 1. 加载数据
df = pd.read_csv('../datas/iris.data', header=None, names=['A', 'B', 'C', 'D', 'E'])
df.info()
"""
最终目的,是将X和Y转换为numpy数组的形式,并且值全部转换为数值型
-1. 因为需要获取X和Y,所以这里第一步从df中提取对应的X、Y, 并将X和Y转换为numpy数组
-2. 需要将Y中的字符串使用数字进行替换,eg:"Iris-setosa": 0, "Iris-versicolor": 1, "Iris-virginica": 2
"""
# 获取X和Y
columns = df.columns
X = np.array(df[columns[:-1]])
Y = np.array(df[columns[-1]])
# 使用LabelEncoder对Y进行编码
le = LabelEncoder()
le.fit(Y)
Y = le.transform(Y)
print("Y中的类别:{}".format(le.classes_))
# print("反转恢复:{}".format(le.inverse_transform([0, 1])))
# 2. 获取X的最后两列数据作为原始的特征属性X
# 按照索引获取所有行的最后两列的数据
X = X[:, -2:]
# print(X)
# 3. 构建模型
algo = KNeighborsClassifier(n_neighbors=9)
# 4. 模型训练
algo.fit(X, Y)
# 5. 看模型效果
Y_predict = algo.predict(X)
print("准确率:{}".format(algo.score(X, Y)))
print("训练数据上的分类报告:\n{}".format(classification_report(Y, Y_predict)))
# 更改阈值(我希望将所有有病的数据全部预测正确)
threshold = 0.77777778
# 获取所有的预测概率
test_predict_prob = algo.predict_proba(X)
# 获取下标为1的那一列概率
test_predict_prob = test_predict_prob[:, 1]
# 做一个布尔索引,将所有值大于等于阈值的区域设置为4.0,小于阈值的区域设置为2.0
test_predict_prob[test_predict_prob >= threshold] = 1
test_predict_prob[test_predict_prob < threshold] = 0
print("测试数据上的混淆矩阵:\n{}".format(confusion_matrix(Y, Y_predict)))
print("更改阈值后测试数据上的混淆矩阵:\n{}".format(confusion_matrix(Y, test_predict_prob)))
# 需要计算一下AUC和ROC的值
# 分别计算AUC的值
test_predict_prob = algo.predict_proba(X)
print(test_predict_prob)
print(Y)
# TODO: 三段代码合并,也就是说要求不允许直接出现0 1 2这三个数字
# 对于第一个类别的AUC值的计算(y=0)
# 构建计算fpr和tpr的时候的实际值,将原始数据中所有类别为0的设置为1,其他类别设置为0
y1_true = (Y == 0).astype(np.int)
y1_score = test_predict_prob[:, 0]
fpr1, tpr1, _ = metrics.roc_curve(y1_true, y1_score)
auc1 = metrics.auc(fpr1, tpr1)
print("类别1的AUC值:{}".format(auc1))
# 对于第二个类别的AUC值的计算(y=1)
# 构建计算fpr和tpr的时候的实际值,将原始数据中所有类别为1的设置为1,其他类别设置为0
y2_true = (Y == 1).astype(np.int)
y2_score = test_predict_prob[:, 1]
fpr2, tpr2, _ = metrics.roc_curve(y2_true, y2_score)
auc2 = metrics.auc(fpr2, tpr2)
print("类别2的AUC值:{}".format(auc2))
# 对于第三个类别的AUC值的计算(y=2)
# 构建计算fpr和tpr的时候的实际值,将原始数据中所有类别为2的设置为1,其他类别设置为0
y3_true = (Y == 2).astype(np.int)
y3_score = test_predict_prob[:, 2]
fpr3, tpr3, _ = metrics.roc_curve(y3_true, y3_score)
auc3 = metrics.auc(fpr3, tpr3)
plt.plot(fpr1, tpr1, 'r-o')
plt.plot(fpr2, tpr2, 'g-o')
plt.plot(fpr3, tpr3, 'b-o')
plt.show()
================================= 一起计算 ROC与AUC值 ===================================
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, Y_train)
# b. 模型效果输出
## 将正确的数据转换为矩阵形式
y_test_hot = label_binarize(Y_test,classes=(1,2,3)) ---------- 该方法的重点
## 得到预测属于某个类别的概率值
knn_y_score = knn.predict_proba(X_test)
## 计算roc的值
knn_fpr, knn_tpr, knn_threasholds = metrics.roc_curve(y_test_hot.ravel(),knn_y_score.ravel())
## 计算auc的值
knn_auc = metrics.auc(knn_fpr, knn_tpr)
print ("KNN算法准确率:", knn.score(X_train, Y_train))
print ("KNN算法AUC值:", knn_auc)
# c. 模型预测
knn_y_predict = knn.predict(X_test)四、KNN算法相关API
sklearn.neighborsneighbors.NearestNeighbors([n_neighbors,...]) 用于实现邻居搜索的无监督学习者。
neighbors.KNeighborsClassifier([...]) 实现k近邻投票的分类器。
neighbors.RadiusNeighborsClassifier([...]) 在给定半径内的邻居之间实施投票的分类器
neighbors.KNeighborsRegressor([n_neighbors,...]) 基于k-最近邻居的回归。
neighbors.RadiusNeighborsRegressor([radius,...]) 基于固定半径内的邻居的回归。
neighbors.NearestCentroid([公制,......]) 最近的质心分类器。
neighbors.BallTree BallTree用于快速广义的N点问题
neighbors.KDTree KDTree用于快速广义N点问题
neighbors.LSHForest([n_estimators,radius,...]) 使用LSH林执行近似最近邻搜索。
neighbors.DistanceMetric DistanceMetric类
neighbors.KernelDensity([带宽,......]) 核密度估计
neighbors.kneighbors_graph(X,n_neighbors [,...]) 计算X中点的k-邻居的(加权)图
neighbors.radius_neighbors_graph(X,半径) 计算X中点的邻居(加权)图
1、 KNN
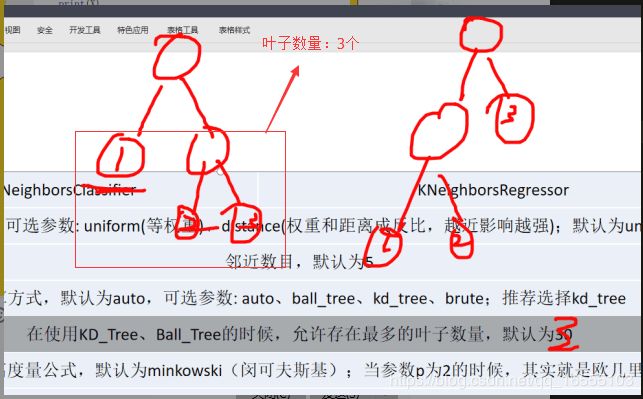
(1)KNN分类
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights='uniform',
algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=1,
**kwargs)
'''
n_neighbors=5, ------- K 值
weights='uniform' ------- 权重的计算方式
'uniform':均匀的权重。每个社区的所有积分均等。
'distance':权重点距离的倒数。在这种情况下,查询点的较近邻居将比远离的邻居具有更大的影响力。
[callable]:一个用户定义的函数,它接受一个距离数组,并返回一个包含权重的相同形状的数组。
algorithm : {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, optional ----- 默认即可
leaf_size=30
p=2, metric='minkowski' -------- 默认即可
'''
属性:
NO
方法:
1、fit(X, y) Fit the model using X as training data and y as target values
2、get_params([deep]) Get parameters for this estimator.
3、kneighbors([X, n_neighbors, return_distance]) 找到一个点的K邻居。
'''
# kneighbors:从训练数据中获取样本X的邻近样本,获取n_neighbors参数多个样本,并且根据参数return_distance
决定是否返回距离值
# 当前参数的情况下,返回的是一个二元组,二元组的第一个元素是一个集合,集合中存储的是邻近样本的距离;
第二个元素还是一个集合,存储的是邻近样本的下标
kneighbors = algo.kneighbors(X=x_test, n_neighbors=9, return_distance=True)
'''
4、kneighbors_graph = KNN_model.kneighbors_graph(X=X_test,n_neighbors=2,mode='distance')
print('连接矩
阵为:{}'.format(kneighbors_graph)) 计算X中点的k-邻居的(加权)图
'''
# kneighbors_graph, 对于X而言,从训练数据中获取距离最近的n_neighbors多个样本,将X和这些样本之间认为是
可以连通的,故将其值设置为1
# mode给定值的设置方式,connectivity表示设置为1,distance表示设置为距离值
# 返回对象表示的是X和训练数据中哪些样本是可以连通的
# 列的数目是训练数据特征向量的数目,行的数目是x_test的样本数目
kneighbors_graph(X=None, n_neighbors=None, mode='connectivity')
例:
连接矩阵为: (0, 0) 0.0
(0, 17) 0.09999999999999998
(1, 1) 0.0 -------- 前三行是第一个样本的三个最近样本的链接情况,最前面是下标,后
面是距离
(1, 45) 0.14142135623730986
(2, 2) 0.0
(2, 47) 0.14142135623730978
'''
5、predict(X) Predict the class labels for the provided data
6、predict_proba(X) Return probability estimates for the test data X.
7、score(X, y[, sample_weight]) Returns the mean accuracy on the given test data and labels.
8、set_params(\*\*params) Set the parameters of this estimator.
(2)KNN回归
class sklearn.neighbors.KNeighborsRegressor(n_neighbors=5, weights='uniform',
algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=1,
**kwargs)2、KDtree
sklearn.neighbors.KDTree
KDTree(X, leaf_size=40, metric=’minkowski’, **kwargs)
方法:
query(X, k=1, return_distance=True, dualtree=False, breadth_first=False) ---- 返回是索引与距离from sklearn.neighbors import KDTree
from sklearn.datasets import make_blobs
data,label = make_blobs(n_samples=100,n_features=3,centers=2,shuffle=True,random_state=28)
# print(data,label)
kdtree = KDTree(data,leaf_size=30)
X_test = [[-8.48575193e+00 ,-5.60369601e+00 , 8.30169601e-01]]
tmp = kdtree.query(X_test,k=5,return_distance=True)
print(tmp)
结果:
(array([[11.09321128, 11.11411761, 11.28784938, 11.29144955, 11.4498738 ]]), array([[34, 19, 14, 72,
75]], dtype=int64))