深度学习视觉目标检测
###深度学习视觉目标检测
整体思路
一、先搭建视觉目标检测算法
二、根据实际的硬件平台和实现效果来优化算法。
深度学习
-
网络结构
卷积、池化、全连接
卷积(深度可分离卷积、空洞卷积、反卷积)
backbone(vgg、resnet、mobileNet)
framework(SSD、YOLO)
-
非线性
如果没有非线性单元,不管多少层的神经网络都是简单的线性叠加。只有加入了非线性单元,才能以任意精度去拟合任意曲线。
sigmoid
f ( x ) = 1 1 + e − x f(x)=\frac{1}{1+e^{-x}} f(x)=1+e−x1

sigmoid导数
ϕ ( x ) = e − x ( 1 + e − x ) 2 \phi(x) = \frac{e^{-x}}{(1+e^{-x})^{2}} ϕ(x)=(1+e−x)2e−x
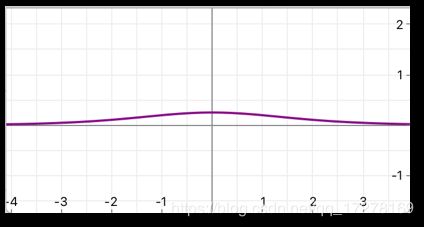
也叫做logistic函数,输出范围是(0,1),激活函数计算的时候计算量⼤大,反向传播求误差梯度的时候有除法。根据其导数图像来看,当x过大或者过⼩的时候,导数曲线的斜率趋近于0,也就是容易易造成“梯度消失了”
tanh
f ( x ) = t a n h ( x ) = e z − e − z e z + e − z f(x)=tanh(x)=\frac{e^z-e^{-z}}{e^z+e^{-z}} f(x)=tanh(x)=ez+e−zez−e−z
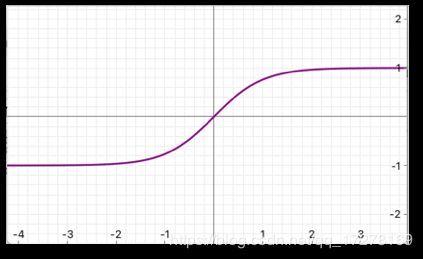
双曲正切函数,相比sigmoid,由于tanh是0均值的,所以在实际应用中会比sigmoid好一些
导数
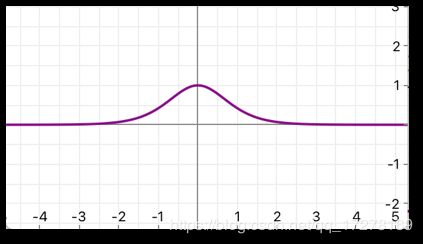
ReLU
f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)
x负半轴值为0,正半轴输出等于输⼊。这样的非线性单元计算量少,求导简单,还有一定的稀疏性,可以缓解一定过拟合。但是正因为其具有稀疏性,如果学习率设置的过大,会导致“神经元死亡”,这些神经元的梯度一直为0,再继续训练都不会更新其权值。

所以后面又有了PReLU,LReLU等一系列的变体PReLU
y i = m a x ( 0 , x i ) + α × m i n ( 0 , x i ) y_i=max(0,x_i)+\alpha\times min(0,x_i) yi=max(0,xi)+α×min(0,xi)
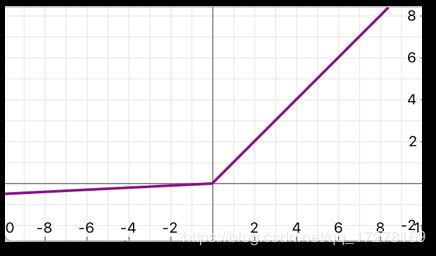
加入了一个α变量,此变量在训练中学习得到。当α为固定的非零较小数的时候等价于LeakyReLU,当α为0的时候,等价于ReLU。 -
损失函数
L2损失-常用来做回归问题
交叉熵损失-常用来做分类问题
FocalLoss-用来解决训练样本中类别不平衡和分类难度差异的问题
回归和分类的区别
回归输出值是连续的,分类输出值是离散的。例如区分一个瓜是西瓜还是南瓜,这就是分类问题。一个西瓜的甜度,0是一点都不甜,1是甜度最大,对西瓜做甜度值回归,得到的0.8分甜,这就是回归问题。
如果是细粒度分类,那就需要在损失函数中做文章了。例如车型识别、人脸识别。如果有一个目标是奥迪车,我想知道是奥迪Q3还是Q5或者是其他车型。这个时候就需要修改常规的损失函数。
-
求解器
SGD,小批量随机梯度下降
Momentum,动量法
Adadelta,对学习率进⾏行行⾃自适应约束
RMSprop,Adadelta的⼀一种发展,对于有预训练模型的训练,原始权值会改变比较小
对于稀疏数据,尽量量使⽤用学习率⾃自适应的优化⽅方法
SGD通常训练收敛的时间会⽐比较⻓长,但是如果能够设置好初始化和学习率,训练效果会好⼀一些。
如果需要更更快的收敛,并且⽹网络很复杂很深的情况,使⽤用学习率⾃自适应算法会好⼀一些
Adadelta,RMSprop在相似的情况下表现差不不多 -
超参数
学习率
如果学习率设置较小,那么训练收敛速度会比较慢,如果学习率设置较高,训练也许会陷入局部极小值震荡,难以收敛。
batch_size
batch_size越大,对显存占用越多。在显存可用范围内尽量使用大的batch_size
训练模型评估
性能评估
计算mAP
多类别物体检测中,每一个类别都可以根据recall和precision绘制一条曲线,AP就是该曲线下下的面积,mAP就是多类别的平均值
时间评估
计算一次前向推理的时间
推理加速
如果算法的推理时间太长,不能达到实际的应用环境的要求,就需要对模型进行推理加速处理,也称为模型压缩。例如训练了一个复杂度比较高的网络,其检测性能还不错,想部署在tx2平台上,然后部署的时候发现根本运行不了实时速度,这个时候就需要对训练的这个模型进行压缩。
模型压缩能够有效降低参数冗余,从而减少存储占用、通信带宽和计算复杂度,有助于深度学习的应用部署,可以有效地降低其内存消耗和时间消耗。但是模型压缩之后肯定是会影响模型性能的,我们只能在精度下降程度在可接受范围内做模型压缩。
模型压缩分为以下几类:
1、结构或非结构剪枝
在网络结构上修改,降低其计算量,比较具有代表性的方法有
-
deep compression
《Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding》” ICLR2016最佳论文 韩松
-
channel pruning
《Channel Pruning for Accelerating Very Deep Neural Networks》
-
network slimming
《Learning Efficient Convolutional Networks through Network Slimming》
网络剪枝的典型过程包括三步:1)训练一个大的过参数化模型,2)根据某个标准修剪训练好的模型,3)微调修剪后的模型,以恢复损失的性能。
使用这类的方法时间消耗降低非常明显,但是性能也会随之降低。
今年10月,《Rethinking the Value of Network Pruning》这篇文章直接指出了“模型剪枝”是个“伪科学”。
一般来说,剪枝过程背后有两个共识:一,大家都认为首先训练一个大的过参数化模型很重要(Luo et al., 2017),因为这样会提供高性能模型(更强的表征和优化能力),而人们可以安全地删除冗余参数而不会对准确率造成显著损伤。因此,这种观点很普遍,人们认为该方法比从头开始直接训练更小的网络(一种常用的基线方法)更优秀。二,剪枝后的架构和相关的权重被认为是获得最终高效模型的关键。因此大多现有的剪枝技术选择微调剪枝后的模型,而不是从头开始训练它。剪枝后保留下来的权重通常被视为至关重要,因为准确地选择一组重要的权重并不容易。
在本研究中,我们认为上面提到的两种观点都未必正确。针对多个数据集及多个网络架构,我们对当前最优剪枝算法进行了大量实证评估,得出了两个令人惊讶的观察结果。首先,对于具备预定义目标网络架构的剪枝算法,从随机初始化直接训练小目标模型能实现与使用经典三步流程相同的性能。在这种情况下,我们不需要从训练大规模模型开始,而是可以直接从头训练剪枝后模型。其次,对于没有预定义目标网络的剪枝算法,从头开始训练剪枝后的模型也可以实现与微调相当甚至更好的性能。
这一观察结果表明,对于这些剪枝算法而言,重要的是获得的网络架构而不是保留的权重,尽管这些目标架构还是需要训练大模型才能获得。我们的结果和文献中结果的矛盾之处在于超参数的选择、数据增强策略和评估基线模型的计算力限制。
2、量化
- fp16
- INT8
3、其他优化方法
-
知识蒸馏
蒸馏模型采用的是迁移学习,通过采用预先训练好的复杂模型的输出作为监督信号去训练另外一个简单的网络。我们一般认为越是复杂的网络具有越好的描述能力,就可以解决更复杂的问题。把复杂的模型称为teacher,简单的模型称为stuent,让teacher学好之后,利用teacher的输出来指导student的学习。这里面student的网络结构比较简单,经过teacher的指导训练比自己重头训练效果要好。
-
网络结构简化
mobileNet
shuffleNet
这一类的优化方法中就是对计算量比较大的卷积操作进行优化,例如mobileNet中主要的优化方法就是采用depthWise(深度可分离卷积)来代替Conv(传统卷积)。
-
权重矩阵低秩分解
-
tensorRT加速
-
TensorRT内部同时实现了网络结构优化和量化
-
实现INT8和FP16计算,减少推理计算量
-
解析网络模型将网络中无用的输出层消除以减小计算
-
对网络结构垂直整合,将目前主流神经网络的conv、BN、Relu三个层融合为了一个层
-
对网络结构水平组合,将输入为相同张量和执行相同操作的层融合一起
-
选取最适合的网络结构
我们的硬件平台是TX2,这款运算芯片包含有6核CPU(4个A57+2丹佛核心)加上PASCAL架构的256核GPU。
决定一个目标检测算法分为两部分
第一部分算法框架,例如SSD,YOLO,FasterRCNN等
第二部分主干网络,主干网络决定整体的计算量,例如VGG,resnet,mobileNet等
所以结合这两部分,可以衍生出很多种检测算法,例如VGG16-SSD,resnet101-SSD,resnet-FasterRCNN,mobileNet-SSD,mobileNet-YOLO等等
VGG网络常见的有16层和19层,以大运算量为主
resnet常见的有101,50,20,可把握程度比较高
mobileNet,分为两个版本V1和V2
限于tx2平台计算力的要求,不可能选择VGG网络,vgg-ssd在tx2上只能跑到6帧左右。
所以第一次尝试使用mobileNet-SSD,在tx2上运行大概35帧左右,检测精度还算不多。
第二次使用resnet20-SSD,在tx2上运行大概32帧左右,精度也还不错,比mobileNet稍微好一点。
tensorRT加速
| 算法 | caffe时间 | tensorRT时间 |
|---|---|---|
| mobileNet-SSD | 30ms | 20ms |
| resnet20-SSD | 32ms | 13ms |
mobileNet在tensorRT的优化下效果没有resnet的优化效果明显
原因:
因为CPU的卷积实现通常会用到im2col,也就是把feature map和卷积核排列成可以用矩阵相乘的形式,然后就会发现depth wise 1*1的卷积实现可以不⽤进行内存的重排,然后直接通过矩阵乘法得到结果,矩阵的乘法在CPU上优化已经很到位了,计算的并行程度很高,核心越多,速度越快。
mobileNet基于流线型架构在tensorRT网络结构可优化空间不太大,而resnet中的残差块在网络结构优化的空间会比较大。
所以mobileNet在tx2这种GPU平台上的性价比不高,更加适合于手机等以CPU为主的移动设备
最新算法的跟进
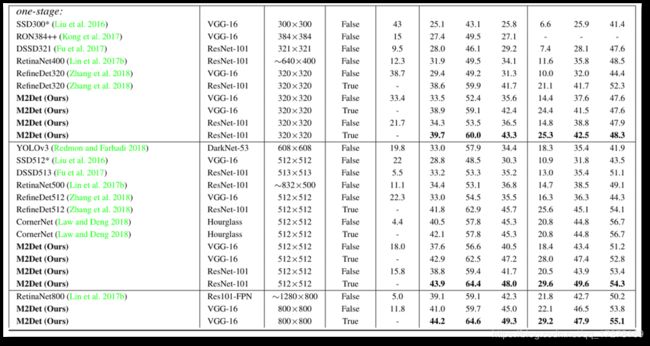
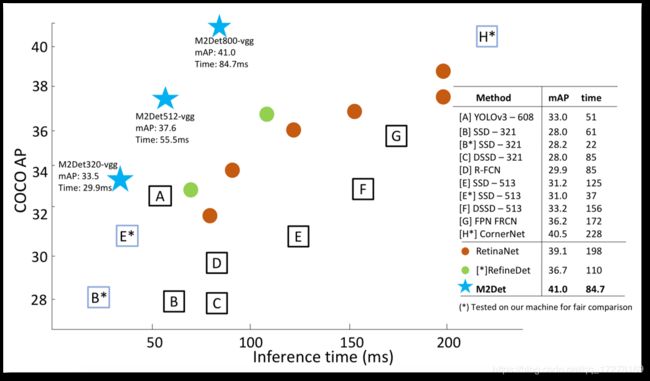
two stage
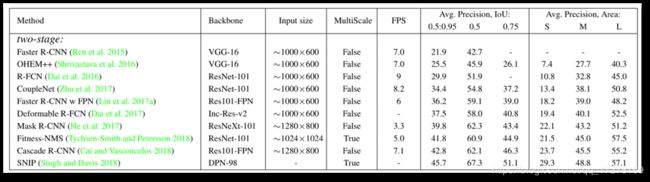
one stage