行为识别——论文整理(1)
谨以此片博客开启我的行为识别之路——养成记录的好习惯
参考1:https://github.com/Ewenwan/MVision/tree/master/CNN/Action_Recognition 以及无数博客大佬们。
参考2:https://zhuanlan.zhihu.com/p/33040925
文章目录
- 1、任务
- 1.1、数据集介绍
- 2、研究进展
- 2.1、传统方法
- 2.1.1 密度轨迹
- Action Recognition by Dense Trajectories(2011)
- Action recognition with improved trajectories(2013)
- 2.2、深度学习
- 2.2.1、Two-stream网络
- Two-Stream Convolutional Networks for Action Recognition in Videos(2014)
- Beyond Short Snippets: Deep Networks for Video Classification(2015)
- Convolutional Two-Stream Network Fusion for Video Action Recognition(2016)
- Temporal Segment Networks: Towards Good Practices for Deep Action Recognition(2016)
- Deep Local Video Feature for Action Recognition(2017)
- Temporal Relational Reasoning in Videos(2018)
- 2.2.2、3D网络
- Learning spatiotemporal features with 3d convolutional networks(2015)
- Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classificati(2017)
- Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks(2017)
- Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset(2017)
- 格式(2018)
1、任务
行为识别就是对时域预先分割好的序列判定其所属行为动作的类型,即“读懂行为”。注意行为识别和行为检测的区别,在实现应用中更容易遇到的是序列尚未在时域分割,需要同时对行为动作进行时域定位(分割)和类型判断,这类任务一般称为行为检测。
1.1、数据集介绍
快了…
2、研究进展
2.1、传统方法
2.1.1 密度轨迹
Action Recognition by Dense Trajectories(2011)
Action recognition with improved trajectories(2013)
iDT算法是行为识别领域中非常经典的一种算法,在深度学习应用于该领域前也是效果最好的算法。由INRIA的IEAR实验室于2013年发表于ICCV。 DT论文 iDT论文
内容:
DT算法利用光流场获取视频序列中的一些轨迹,沿着轨迹提取HOF、HOG、MBH和trajectory四种特征。最后利用FV(Fisher Vector)方法对特征进行编码,再基于编码结果训练SVM分类器。而iDT改进的地方在于其利用前后帧视频间的光流和SURF关键点进行匹配,从而消除/减弱相机运动带来的影响。
代码:
源码、第三方源码
模型:
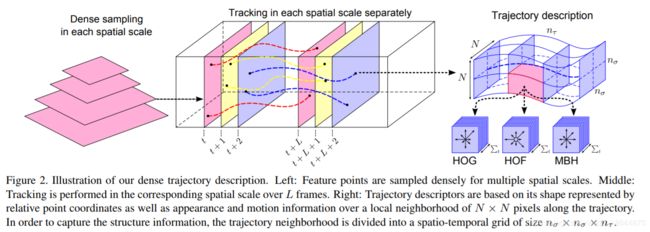
说明:
A. 利用光流场来获得视频序列中的一些轨迹;
a. 通过网格划分的方式在图片的多个尺度上分别密集采样特征点,滤除一些变换少的点;
b. 计算特征点邻域内的光流中值来得到特征点的运动速度,进而跟踪关键点;
B. 沿轨迹提取HOF,HOG,MBH,trajectory,4种特征
其中HOG基于灰度图计算,另外几个均基于稠密光流场计算。
a. HOG, 方向梯度直方图,分块后根据像素的梯度方向统计像素的梯度幅值。
b. HOF, 光流直方图,光流通过当前帧梯度矩阵和相邻帧时间上的灰度变换矩阵计算得
到,之后再对光流方向进行加权统计。
c. MBH,运动边界直方图,实质为光流梯度直方图。即分别在图像的x和y方向光流图像上计算HOG特征。
d. Trajectories, 轨迹特征,特征点在各个帧上位置点的差值,构成轨迹变化特征。
2.2、深度学习
2.2.1、Two-stream网络
Two-Stream Convolutional Networks for Action Recognition in Videos(2014)
提出Two-stream时空双流网络 论文
内容
首先计算连续两帧间的稠密光流,然后将携带了场景和目标信息的视频帧和携带相机和目标运动信息的光流分别训练CNN模型,两个网络分别对动作进行类别的判断,最后对两流的softmax分数采用平均或者SVM来计算。
代码
未公开
模型

实验
UCF101-88.0%,HMDB51-59.4%
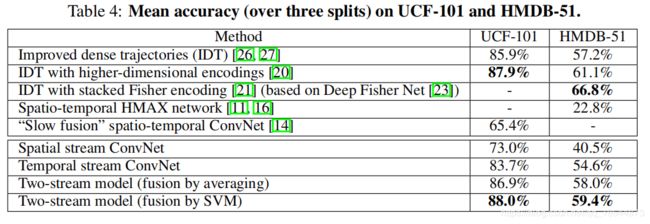
备注
时间流采用密集光流
Beyond Short Snippets: Deep Networks for Video Classification(2015)
论文
内容
论文中讨论了两种方法:
1)提取每一帧的深度卷积特征,再使用不同的pooling层结构(见备注)进行特征融合,得到最终输出。
2)使用LSTM提取视频序列上的全局信息,再加softmax层得到最终分类。
代码
未公开
模型
实验
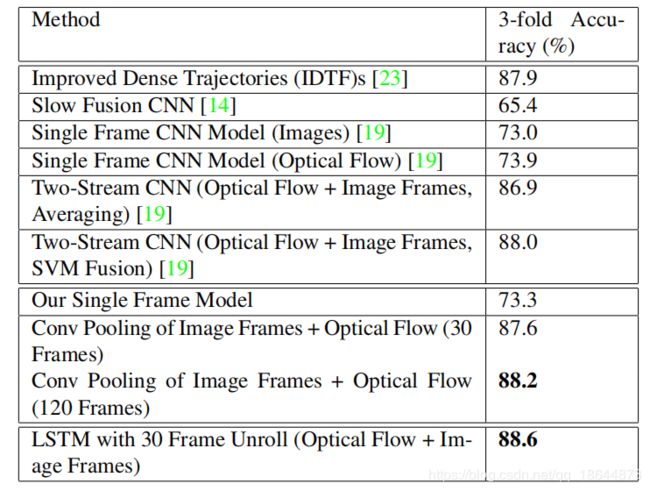
备注
1、对比了Conv Pooling、Late Pooling、Slow Pooling、Local Pooling、Time-Domain Convolution和GoogLeNet Conv Pooling等融合方法。实验表明,上述方法效果都较差,说明一个时间域的卷积层对于在高级特征上学习时间关系是无效的,进而使用LSTM从时间序列中学习。
2、没有光流时,在UCF-101可以达到82.6%,加上光流后达到88.6%。
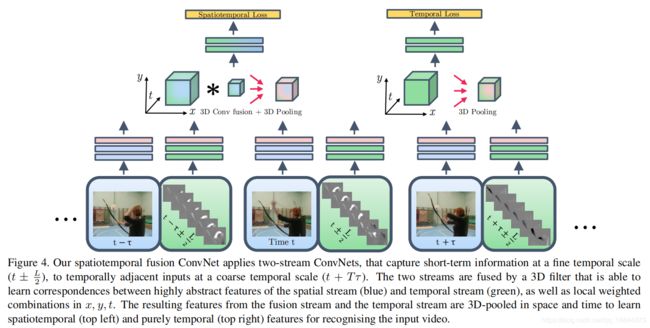
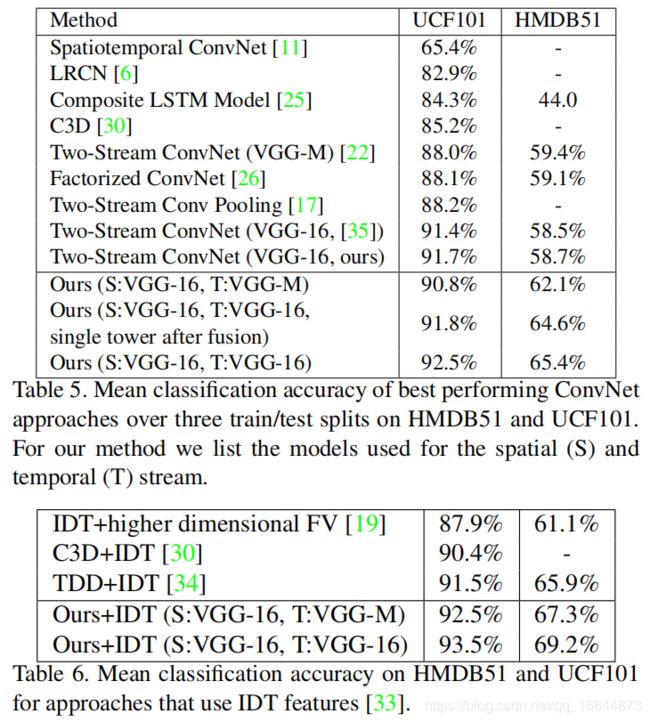
Convolutional Two-Stream Network Fusion for Video Action Recognition(2016)
论文
内容
在原双流基础上做了改进,原双流网络时间和空间流在最后一步融合,结果取平均或SVM计算。本文将双流网络都换成VGG-16网络,最后用一个卷积层融合双流网络。
代码
源码(caffe)、第三方源码(matlab)
模型
实验
备注
1、时间融合后使用单个流在UCF-101上可以达到91.8%,保持两个流可以达到92.5%。前者参数要少很多。
2、将iDT方法的SVM评分与本文方法(softmax之前)预测进行平均,在UCF-101上取得93.5%,在HMDB-51取得69.2%。可以想象此方法的龟速。
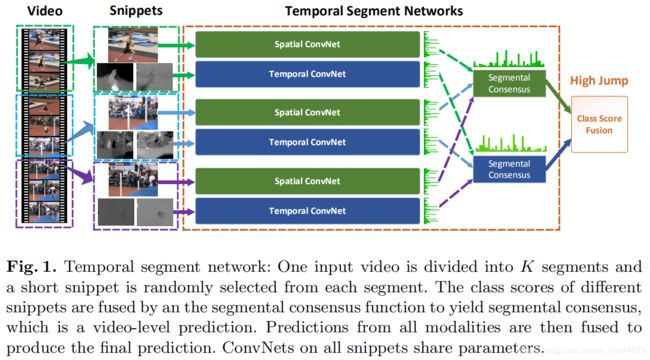
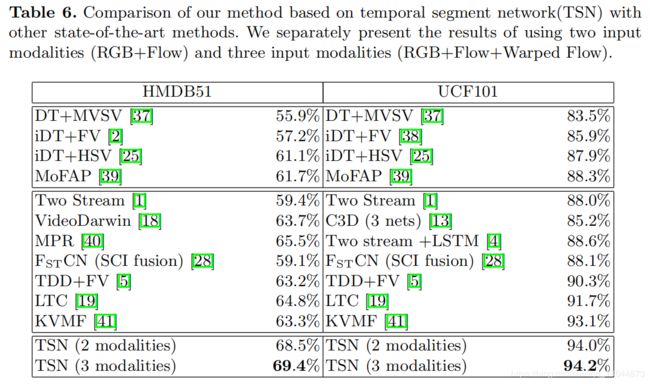
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition(2016)
TSN网络提出,适用于长时间视频的行为判断。 论文
内容
视频的连续帧之间存在冗余,采用较为稀疏的抽帧方法去除冗余信息,同时减少计算量,具体做法:将视频分成K个segments,从每个segment中随机地选择一个short snippet。将选择的snippets通过BN-Inception (Inception with Batch Normalization)构建的two-stream卷积神经网络得到不同snippets的class scores,最后将它们融合。
通过常规的数据增加技术、regularization;还有作者提到的cross-modality pre-training,dropout等方式来减少过拟合,来弥补数据量的问题。还研究RGB difference和warped optical flow对动作检测效果的影响。
代码
源码(caffe)
模型
![]()
图中绿色条形图代表score在类别上的分布,G是聚合函数(本文采用均值函数,就是对所有snippet的属于同一类别的得分做个均值),G函数输出的是Segmental Consensus的输出结果。最后,利用H函数(本文采用softmax函数)计算得分概率,得分最高的类别就是该video所属类别。
网络参数是共享的,即K个spatial convnet的参数是共享的,K个temporal convnet的参数也是共享的,实际用代码实现时只是不同的输入同一个网络。
实验
使用TVL1光流算法提取正常光流场和扭曲光流场
备注
1、cross-modality pre-training:通过线性变换将光流场离散到从0到255的区间,这使得光流场的范围和RGB图像相同。然后,修改RGB模型第一个卷积层的权重来处理光流场的输入。具体来说,就是对RGB通道上的权重进行平均,并根据时间网络输入的通道数量复制这个平均值。这一策略对时间网络中降低过拟合非常有效。
2、数据增强:传统的two-stream采用随记裁剪和水平翻转方式,本文提出两种新的方法,即角裁剪(corner cropping)和尺度抖动(scale-jittering)。
Deep Local Video Feature for Action Recognition(2017)
论文
内容
不是所有视频帧都包含有用信息,本文首先采用TSN提取局部特征。然后将局部特征聚合(本文采用最大池化方法)成全局特征,通过第二个分类阶段采用SVM分配视频级别的标签。
代码
未公开
模型
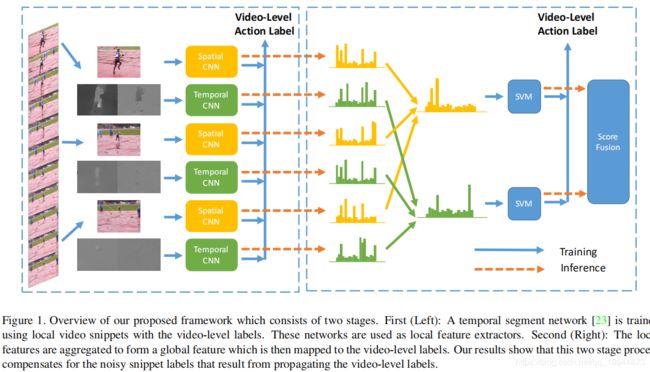
实验
备注
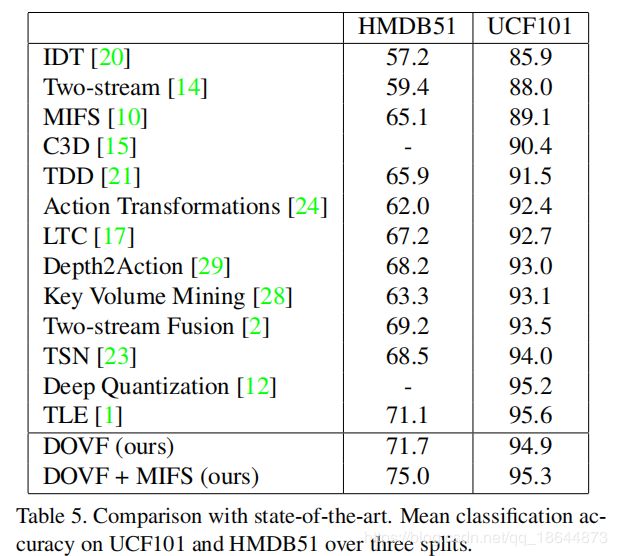
1、聚合( aggregation )方法:本文对比了Mean、Max、Mean_Std、BoW、VLAD和FV方法,实验表示最大池化Max效果最好。
2、采样:对每个视频每个clips稀疏采样15帧就就足够了。
Temporal Relational Reasoning in Videos(2018)
论文
内容
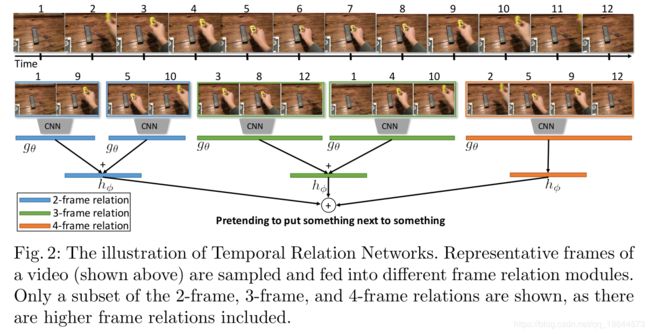
本文提出一种时间关系网络,用来在多个时间尺度上学习,将不同时间尺度的关系特征融合到一起,即可得到多时间尺度的时间关系
时间关系:给定一段视频V,选取n个有序的视频帧序列 f 1 , f 2 , … , f n {f_1,f_2,…,f_n} f1,f2,…,fn,则第 f i f_i fi和 f j f_j fj帧的关系定义如下:
T 2 ( V ) = h ϕ ( ∑ i < j g θ ( f i , f j ) ) T 3 ( V ) = h ϕ ′ ( ∑ i < j < k g θ ′ ( f i , f j , f k ) ) T_2(V)=h_\phi(\sum_{i<j} g_\theta(f_i,f_j)) \\ T_3(V)=h'_\phi(\sum_{i<j<k} g'_\theta(f_i,f_j,f_k)) T2(V)=hϕ(i<j∑gθ(fi,fj))T3(V)=hϕ′(i<j<k∑gθ′(fi,fj,fk))
其中函数 h ϕ h_\phi hϕ和 g θ g_\theta gθ用于融合不同帧的特征,这里使用了简单的多层感知机(MLP)来实现。这里i和j的选取是随机的。将该2-frame的关系概念可以拓展到N-frame。使用复合函数 M T N ( V ) = T 2 ( V ) + T 3 ( V ) . . . + T N ( V ) MT_N(V)=T_2(V)+T_3(V)...+T_N(V) MTN(V)=T2(V)+T3(V)...+TN(V)融合不同尺度的视频帧关系。
获取TRN的代表帧序列:首先,计算视频中等距帧的特征,然后随机组合他们生成不同的帧关系元组并将它们传递给到TRNs中,最后使用不同TRNs的响应对关系元组排序。
代码
源码(pytorch)
模型
实验
目前可以用来做时间关系推理的数据集有Something-Something, Jester和Charades。其中Something-Something是最近提出的数据集,主要是用于人-物体交互动作识别,里面有174类。
备注
无
2.2.2、3D网络
Learning spatiotemporal features with 3d convolutional networks(2015)
C3D提出 论文
内容
本文提出3D ConvNets在大规模视频数据集训练来学习视频的时空特征,并经过实验选取了最佳的卷积核的尺寸3x3x3。使用C3D可以同时对外观和运动信息进行建模,在各种视频分析任务上都优于2D卷积网络的特征。
代码
源码(caffe)、预训练模型
模型


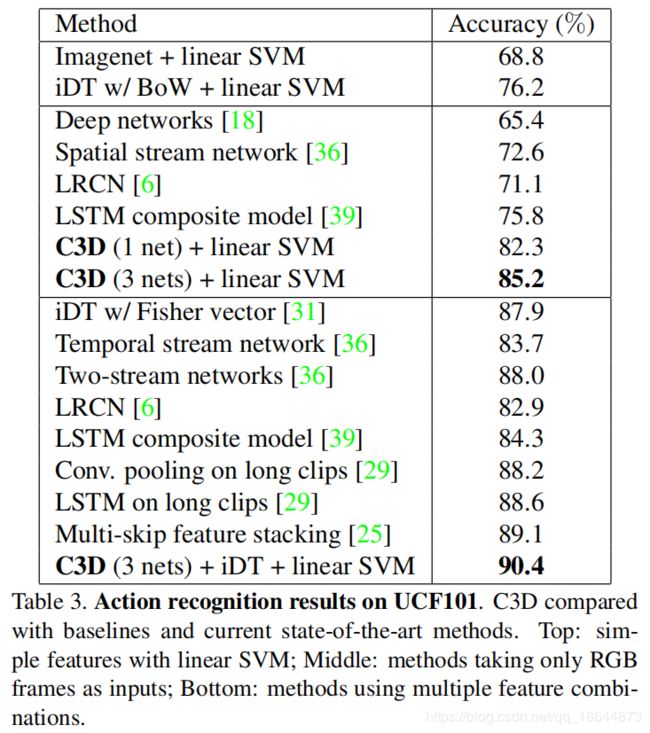
实验
备注
1、处理速度:若将一段16帧的视频作为一个输入,那么C3D每秒可以处理约42个输入(显卡为1080, batch size选为50),而图中的fps达到了313.9,也就是每秒可以平均处理313.9帧,可见C3D的速度还是非常快的。
Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classificati(2017)
T3D 论文
内容
本文最大的贡献就是该迁移方法的提出。本文引入一种新的时域层temporal layer给可变时域卷积核深度建模,此层叫做temporal transition layer(TTL) ,将这个新的temporal layer嵌入到我们提出的3D CNN,此网络叫做Temporal 3D ConvNets(T3D)。本文将DenseNet 结构从2D扩展到3D中。另一个贡献是将知识预先训练好的2D CNN转移到随记初始化的3D CNN以实现稳定的权值初始化。
代码
源码(pytorch)
模型
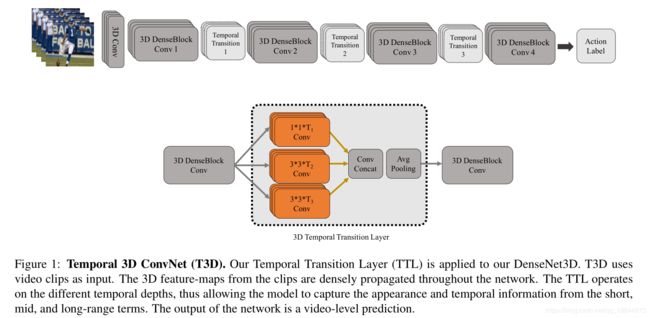
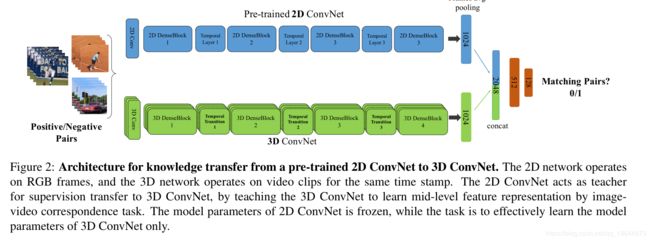
实验
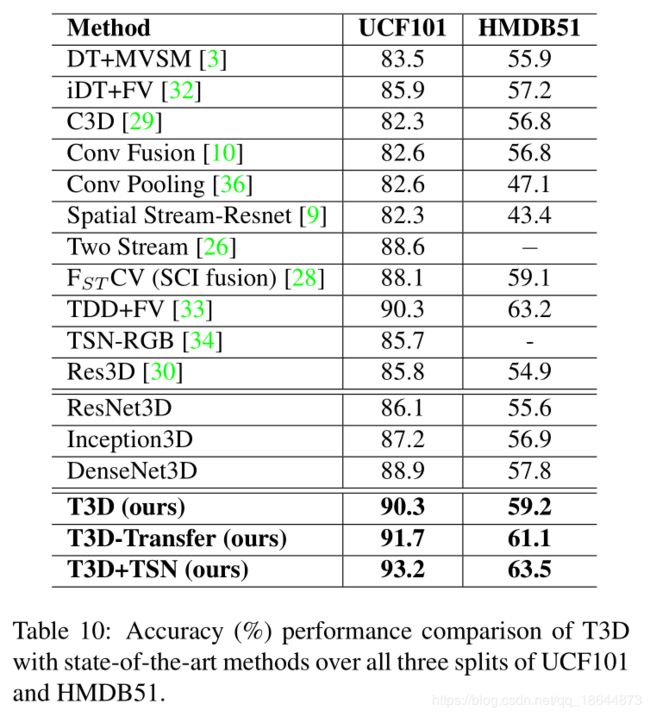
备注
无
Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks(2017)
P3D 论文
内容
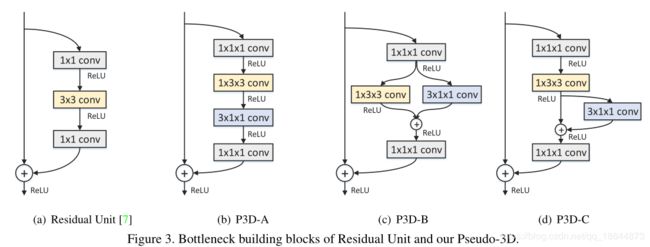
提出Pseudo-3D Residual Net (P3D ResNet),将1*3*3卷积和3*1*1卷积替代3*3*3卷积(前者用来获取spatial维度的特征,实际上和2D的卷积没什么差别,后者用来获取temporal维度的特征,因为倒数第三维是帧的数量),很大程度上减少计算量。
代码
源码(caffe)、第三方源码(pytorch)
模型
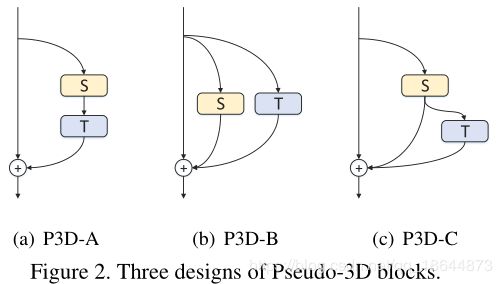

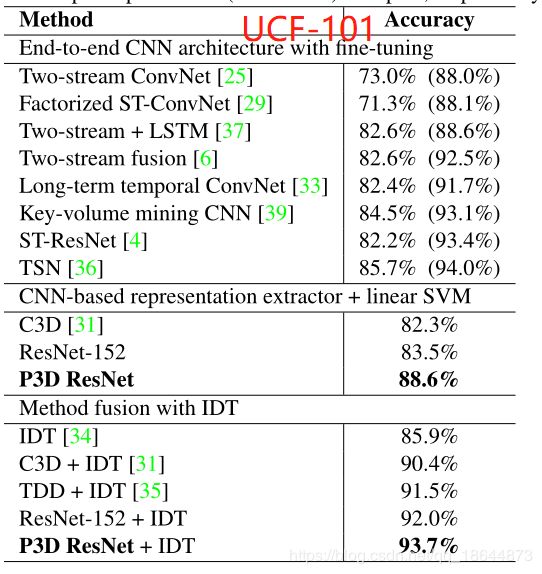
实验
备注
无
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset(2017)
I3D 论文
内容
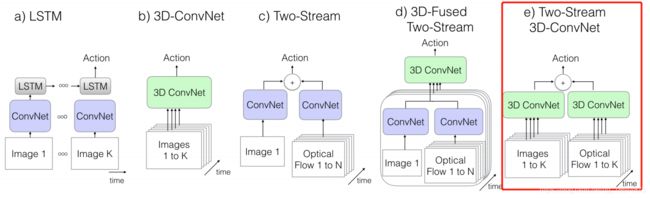
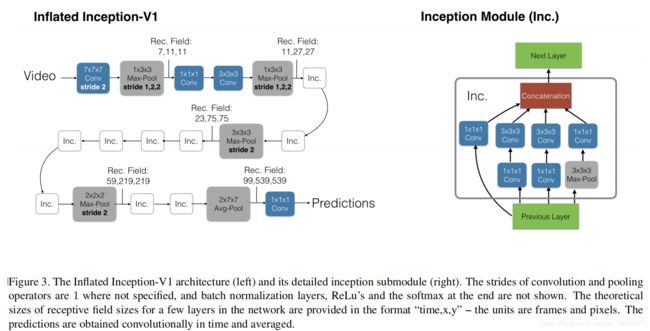
本文介绍了一个新的分类网络:膨胀3D卷积神经网络(I3D),即将卷积层和池化层推广到3D情况。发布了在新数据集Kinetics上训练的BN Inception-v1 I3D models,通过迁移学习到UCF-101和HMDB-51上,取得惊人的精度。
代码
源码(tensorflow)
模型
实验
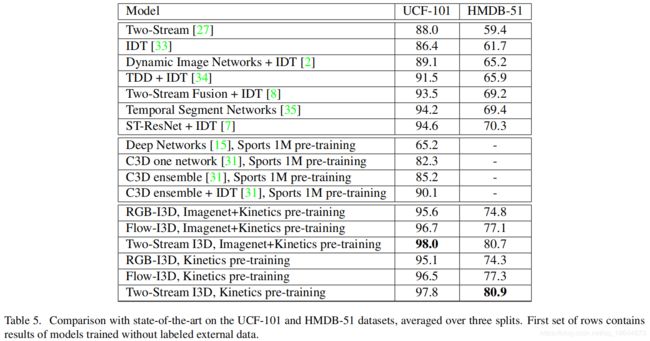
备注
1、Kinetics数据集:包含大量数据,有400个动作分类,每个分类有超过400个实例,来源于YouTube,更有挑战性。具体细节查看文献 The Kinetics Human Action Video Dataset。Kinetics-600下载地址。
格式(2018)
内容
代码
模型
实验
备注