机器学习-Python实践Day1(鸢尾花项目)
1、机器学习中的Hello World(鸢尾花分类)
- 1.1、项目步骤流程:
- 1.1.1、导入数据
- 1.1.2、概述数据
- 1.1.3、数据可视化
- 单变量图表
- 多变量图表
- 1.1.4、评估算法
- 1.1.5、实施预测
程序代码我将在Anaconda3的Jupyter Notebook中运行。
鸢尾花数据集,大家可以到以下链接下载:
http://archive.ics.uci.edu/ml/machine-learning-databases/iris/
1.1、项目步骤流程:
- 导入数据
- 概述数据
- 数据可视化
- 评估算法
- 实施预测
1.1.1、导入数据
# 导入类库
import pandas as pd
import matplotlib.pyplot as plt
# 导入数据集
filename='iris.data.csv'
name=['separ-length','separ-width','petal-length','petal-width','class']
dataset=pd.read_csv(filename,names=name)
1.1.2、概述数据
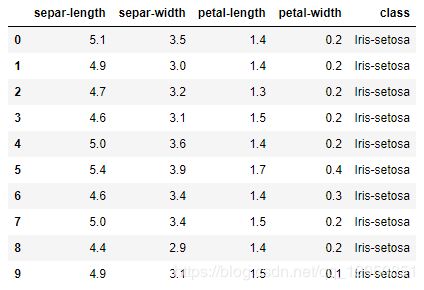
# 查看前十行数据
dataset.head(10)
# 查看数据维度
print('数据维度: 行%s,列%s' %dataset.shape)
数据维度: 行150,列5
# count --行数
# mean --中位数
# std --标准差
# min --最小值
# 25% --第一位四分位数
# 50% --第二位四分位数
# 75% --第三位四分位数
# max --最大值
dataset.describe()

# 查看数据维度
print(dataset.groupby('class').size())
1.1.3、数据可视化
通过图表来查看数据特征的分布情况和数据不同特征之间关系
- 使用单变量图表可以更好地理解每一个特征属性
- 多变量图表用于理解不同特征属性之间的关系
单变量图表
#箱线图
dataset.plot(kind='box',subplots=True,layout=(2,2),sharex=False,sharey=False)
plt.show()

# 直方图
dataset.hist()
plt.show()

多变量图表
from pandas.plotting import scatter_matrix
scatter_matrix(dataset)
plt.show()

1.1.4、评估算法
①切分数据集
from sklearn.model_selection import train_test_split
# 切分特征和标签
# 其中X为特征集数据,Y为标签集数据
# X=dataset.values[:,0:4]
# Y=dataset.values[:,4]
X=dataset.iloc[:,0:4].values
Y=dataset.iloc[:,4].values
# 切分评估训练数据集
X_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=0.2,random_state=33)
参数test_size=0.2表示80%的数据集用来训练,20%的数据集用来验证评估。
参数random_state用于设置随机数种子,确保每次使用相同的数据集
X_train,Y_train用于训练算法创建模型,X_test,Y_test用于验证评估模型。
②创建模型
# 创建模型
# 逻辑回归(LR)
# 线性判别分析(LDA)
# K近邻(KNN)
# 分类与回归树(CART)
# 贝叶斯分类器(NB)
# 支持向量机(SVM)
models={}
models['LR']=LogisticRegression()
models['LDA']=LinearDiscriminantAnalysis()
models['KNN']=KNeighborsClassifier()
models['CART']=DecisionTreeClassifier()
models['NB']=GaussianNB()
models['SVM']=SVC()
③评估模型
results=[]
for key in models:
# 这里采用10折交叉验证来评估模型,关于10折交叉验证,后续将会详细介绍。
kfold=KFold(n_splits=10,random_state=33)
cv_results=cross_val_score(models[key],X_train,Y_train,cv=kfold,scoring='accuracy')
results.append(cv_results)
print('%s:%f(%f)'%(key,cv_results.mean(),cv_results.std()))
LR:0.941667(0.098953)
LDA:0.975000(0.053359)
KNN:0.975000(0.038188)
CART:0.958333(0.076830)
NB:0.958333(0.055902)
SVM:0.975000(0.053359)
可以看出来SVM的评分最高。
接下来可以通过箱线图来查看评估结果。
fig=plt.figure()
fig.suptitle('Algorithm Comparison')
ax=fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(models.keys())
plt.show()

1.1.5、实施预测
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
svm=SVC()
svm.fit(X_train,Y_train)
y_pred=svm.predict(X_test)
print("准确度:",accuracy_score(Y_test,y_pred))
print("混淆矩阵:",confusion_matrix(Y_test,y_pred))
print("分类数值:",classification_report(Y_test,y_pred))
准确度: 0.9333333333333333
混淆矩阵: [[ 8 0 0]
[ 0 8 0]
[ 0 2 12]]
分类数值: precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 8
Iris-versicolor 0.80 1.00 0.89 8
Iris-virginica 1.00 0.86 0.92 14
avg / total 0.95 0.93 0.93 30