MapTask并行度和切片机制
一. MapTask
并行度决定机制
maptask
的并行度决定
map
阶段的任务处理并发度,进而影响到整个
job
的处理速度
那么,
mapTask
并行实例是否越多越好呢?其并行度又是如何决定呢?
1.1 mapTask
并行度的决定机制
一个
job
的
map
阶段并行度由客户端在提交
job
时决定
而客户端对
map
阶段并行度的规划的基本逻辑为:
将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多个
split
),然后
每一个
split
分配一个
mapTask
并行实例处理
(
3
)注意:
block
是
HDFS
上物理上存储的存储的数据,切片是对数据逻辑上的划分。两者之间没有关系。即使
hdfs
上是
128M
存储,
Mapreduce
也会切片,只是默认切片也是
128M
。也可以非
128M
切片,如
100M
,多余的部门由框架内部处理和其他结点进行拼接切片。因为切片决定了给其分配
mapTask
进程数量。
(
4
)在
HDFS
上
,map
默认运算切片大小是
128M
,但如果是本地运行的话,
maP
默认切片大小是
32M.
。
maptask
和
reducetask
其实都框架下的一个类。
这段逻辑及形成的切片规划描述文件,
由
FileInputFormat
实现类的
getSplits()
方法
完成,其过程如下图:
 二:InputFormat
数据切片机制
二:InputFormat
数据切片机制
主要有两个方法:getsplit(),客户端用来切片。
creatRecordReader()MR用来读数据
1.FileInputFormat
切片机制(在提交yarn前已完成,客户端完成)
注解:
FileInputFormat
继承与
InputFormat
类,都是
mapreduce
包下的类。
归其管理
其余的常用类,如
TextInputFormat
和
CombinInputFormat
都是
FileInputFormat
的子类。
1、切片定义在InputFormat类中的getSplit()方法
2、FileInputFormat中默认的切片机制:
1.简单地按照文件的内容长度进行切片
2.切片大小,默认等于block大小(这样如果有很多小文件时,就会产生很多切片,造成很多个maptask,降低系统性能)
3.切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
2.切片大小,默认等于block大小(这样如果有很多小文件时,就会产生很多切片,造成很多个maptask,降低系统性能)
3.切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
比如待处理数据有两个文件:
|
file1.txt 320M
file2.txt 10M
|
经过
FileInputFormat
的切片机制运算后,形成的切片信息如下:
|
file1.txt.split1-- 0~128
file1.txt.split2-- 128~256
file1.txt.split3-- 256~320
file2.txt.split1-- 0~10M
|
3
、
FileInputFormat
中切片的大小的参数配置
2
.
FileInputFormat
源码解析
(input.getSplits(job))从job.waitforComplecation开始断点,直到提交到yarn上。
(
1
)
找到你数据存储的目录。(可以是目录,多个文件同时进行统计,然后将统计结果装载到一个文件或者多个文件里。。也可以单独统计分析
1
个文件。)
(
2
)
开始遍历处理(规划切片)目录下的每一个文件
(
3
)遍历第一个文件
ss.txt
a)
获取文件大小
fs.sizeOf(ss.txt);
b)
计算切片大小
computeSliteSiz
e(Math.max(minSize,Math.min(maxSize,blocksize)))=blocksize=128M
c)
开始切,形成第
1
个切片:
ss.txt—0:128M
第
2
个切片
ss.txt—128:256M
第
3
个切片
ss.txt—256M:300M
(
每次切片时,都要判断切完剩下的部分是否大于块的
1.1
倍,
不大于
1.1
倍就划分一块切片
)当然类中方法也会判断,如果是压缩文件之类的,是不会切片的。报异常。
d)
将切片信息写到一个切片规划文件中
f)
整个切片的核心过程在
getSplit()
方法中完成。(是
FileInputFormat
类中的方法)
(
4
)
提交切片规划文件到
yarn
上,
yarn
上的
MrAppMaster
就可以根据切片规划文件计算开启
maptask
个数。
3.通过分析源码,在
FileInputFormat
中,计算切片大小的逻辑:
Math.max(minSize, Math.min(maxSize, blockSize));
切片主要由这几个值来运算决定
FileInputFormat
中默认的切片机制:
(1)简单地按照文件的内容长度进行切片
(2)切片大小,默认等于block大小
(3)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
(2)切片大小,默认等于block大小
(3)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
比如待处理数据有两个文件:
|
file1.txt 320M
file2.txt 10M
|
经过
FileInputFormat
的切片机制运算后,形成的切片信息如下:
|
file1.txt.split1-- 0~128
file1.txt.split2-- 128~256
file1.txt.split3-- 256~320
file2.txt.split1-- 0~10M
|
4
)
FileInputFormat
切片大小的参数配置
(
1
)通过分析源码,在
FileInputFormat
中,计算切片大小的逻辑:
Math.max(minSize, Math.min(maxSize, blockSize));
切片主要由这几个值来运算决定
mapreduce.input.fileinputformat.split.minsize=1
默认值为
1
mapreduce.input.fileinputformat.split.maxsize= Long.MAXValue
默认值
Long.MAXValue
因此,
默认情况下,切片大小
=blocksize
。
maxsize
(切片最大值):参数如果调得比
blocksize
小,则会让切片变小,而且就等于配置的这个参数的值。
minsize
(切片最小值):参数调的比
blockSize
大,则可以让切片变得比
blocksize
还大。
5
)获取切片信息
API
:
FileSplit
是
inputSplit
的子类。
|
//
根据文件类型获取切片信息
FileSplit inputSplit = (FileSplit) context.getInputSplit();
//
获取切片的文件名称
String name = inputSplit.getPath().getName();
//
获取的是被切片文件名:
|
选择并发数的影响因素:
1- 运算节点的硬件配置
2- 运算任务的类型:CPU密集型还是IO密集型
3- 运算任务的数据量
map并行度的经验之谈
1.如果硬件配置为
2*12core + 64G
,恰当的
map
并行度是大约每个节点
20-100
个
map
,
最好每个
map
的执行时间至少一分钟。
2.
如果
job
的每个
map
或者
reduce task
的运行时间都只有
30-40
秒钟,那么就减少该
job
的
map
或者
reduce
数,每一个
task(map|reduce)
的
setup
和加入到调度器中进行调度,这个中间的过程可能都要花费几秒钟,所以如果每个
task
都非常快就跑完了,就会在
task
的开始和结束的时候浪费太多的时间。
配置
task
的
JVM
重用可以改善该问题:1
(
mapred.job.reuse.jvm.num.tasks
,
默认是
1
,表示一个
JVM
上最多可以顺序执行的
task
数目(属于同一个
Job
)是
1
。也就是说一个
task
启一个
JVM
)
注释:
JVM
重用技术不是指同一
Job
的两个或两个以上的
task
可以同时运行于同一
JVM
上,而是排队按顺序执行
3.如果
input
的文件非常的大,比如
1TB
,可以
考虑将
hdfs
上的每个
block size
设大,比如设成
256MB
或者
512MB
2.ReduceTask并行度的决定
reducetask的并行度同样影响整个job的执行并发度和执行效率,但与
maptask的并发数由切片数决定不同,Reducetask数量的决定是可以直接手动设置,默认值为1.
//默认值是1,手动设置为4
job.setNumReduceTasks(4);
如果数据分布不均匀,就有可能在reduce阶段产生数据倾斜
注意: reducetask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个reducetask
尽量不要运行太多的reduce task。对大多数job来说,最好rduce的个数最多和集群中的reduce持平,或者比集群的 reduce slots小。这个对于小集群而言,尤其重要。
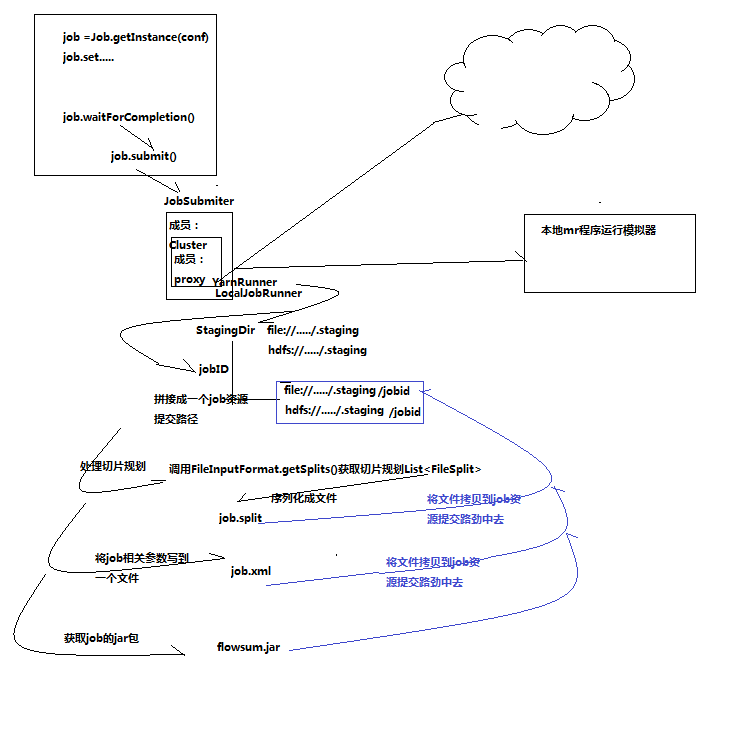
1)job提交流程源码详解
waitForCompletion()
submit();
// 1建立连接
connect();
// 1)创建提交job的代理
new Cluster(getConfiguration());
// (1)判断是本地yarn还是远程
initialize(jobTrackAddr, conf);
// 2 提交job
submitter.submitJobInternal(Job.this, cluster)
// 1)创建给集群提交数据的Stag路径
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
// 2)获取jobid ,并创建job路径
JobID jobId = submitClient.getNewJobID();
// 3)拷贝jar包到集群
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir);
// 4)计算切片,生成切片规划文件
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// 5)向Stag路径写xml配置文件
writeConf(conf, submitJobFile);
conf.writeXml(out);
// 6)提交job,返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());