知识图谱(2) -- 深入解读demo
一. 流程
1. 安装pymysql,mysql
pip install pymysql2. 爬取数据
执行 crawler.movie_crawler.py
3. 利用D2RQ生成mapping文件
generate-mapping -u root -o kg_demo_movie_mapping.ttl jdbc:mysql:///kg_demo_movie这里需要对生成的mapping进行一定的修改,请参考大佬专栏 。
4. 利用D2RQ生成nt文件
这里的nt文件就是存放所有RDF数据的文件了。
.\dump-rdf.bat -o kg_demo_movie.nt .\kg_demo_movie_mapping.ttl5. 建立protege
根据大佬专栏教程建立owl文件,也就是所谓的本体文件,确定数据与数据之间的关系。
6. 书写fuseki_conf.ttl
这里还是根据大佬的专栏进行书写,(没错,很不负责任地说,这是一篇基于大佬专栏的笔记),但是大佬专栏写的ttl文件可能并不能适应于你下载的fuseki版本,所以需要进行两处修改。
1. 将 ja:baseModel<#tdbGraph>; 修改为 ja:MemoryModel<#tdbGraph>
2. 注释掉 ja:content 这一行,等服务开启后,通过http://localhost:3030/登陆页面,手动上传ontology.ttl文件(本体文件,也就是用Protege生成的文件)即可。7. 上传nt数据
登陆服务器后,选择对应的知识图谱,然后选择上传数据的选项,将之前生成的RDF文件上传到服务器上。
8. 运行python代码
执行 kg_demo_movie/KB_query/query_main.py 进行知识图查询
到这里,比较麻烦的操作就算是完成了,最后剩下的编码细节将会在下一节讲,不过将不再使用本demo,选择使用一个较为简单的demo来做记录。
二. 可能遇到的问题
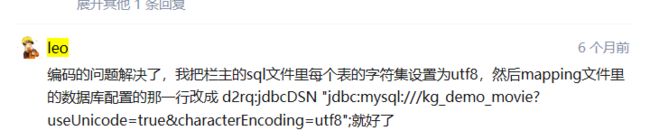
1. pymysql编码问题
在利用原demo进行流程测试过程中,发现出现编码不匹配问题,大概就是爬取的数据是UTF8格式的,然后数据库存的确实unicode格式。后来找了很多资料,终于解决关于python中pymysql数据编码的问题。
2. 安装mysql的问题。
这里建议直接用pip安装mysql,省心省力。
pip install MySQL-python3. 使用D2RQ生成默认的mapping文件。
需要在原教程的命令中加入-p 123456 作为链接数据库的密码。
4. 使用D2RQ的时候,需要对生成的mapping文件适当地修改。
这里的话,还是按照大佬的教程走,然后参照大佬的方式进行修改就行,这个步骤有点小繁琐吧,因为数据库如果更新了, 相应地就需要对这个文件进行更新,这是一件比较麻烦的事情,后续会看看怎么改善这一步。
5. 使用D2RQ进行查询时,出现中文查询失败的情况,但是中文显示并没有问题,这是一个很奇怪的事情。
不过这并没有关系,因为总会有大佬提出解决方案。(做个小白真是太好了!: ))。
三. 参考资料
1. 知识图谱-给AI装个大脑