Python进阶笔记(五)迭代器和生成器
5.1 迭代协议
迭代协议:
迭代器是访问集合类元素的一种方式,一般是用来遍历数据;
- for循环也可以遍历数据,能完成for循环是因为背后的迭代器在产生作用;
- 迭代器和以下标的访问方式不一样,迭代器是不能返回的;
迭代器只能一条一条返回,而且迭代器提供了一种惰性(或者理解为延迟)的访问数据的方式,生成器背后也是迭代器,其可以让我们在访问数据时才会计算或者获取数据;
下标的访问方式的原理是__getitem__;
python中的list,可迭代的类型,背后都是实现了迭代协议的,而迭代协议实际上就是__iter__方法,和之前讲的一样,在for循环遍历时,会优先寻找iter方法,如果没有,才去运行getitem方法。
from collections.abc import Iterable, Iterator
可迭代类型和迭代器
Iterator迭代器;
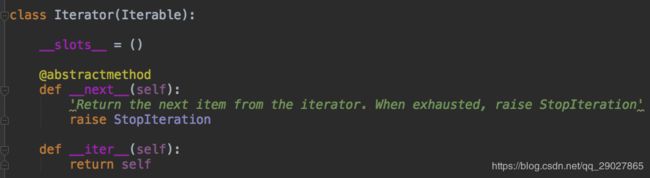
__iter__用来返回迭代器,__next__用来返回下一个数据;
由此看到,迭代器的核心还是在__next__上,只实现__iter__方法就是可迭代类型,如果要实现迭代器,就要实现__iter__和__next__两个方法。
# 判断list是一个Iterable还是一个Iterator
from collections.abc import Iterable, Iterator
a = [1,2]
print (isinstance(a, Iterable))
print (isinstance(a, Iterator))
# 可以看到list可迭代但并不是一个迭代器,将迭代器转化为迭代类型
iter_rator = iter(a)
print (isinstance(iter_rator, Iterator))
5.2 什么是迭代器和可迭代对象
class Company(object):
def __init__(self, employee_list):
self.employee = employee_list
def __getitem__(self, item):
return self.employee[item]
if __name__ == "__main__":
company = Company(["tom", "bob", "jane"])
for item in company:
print(item)
# 在调用for循环时,实际上是会调用iter()方法:iter(company),
# 虽然在Company类中并未实现__iter__的魔法函数,但是这个内置的方法会寻找有没有定义iter函数,如果没有的话,会首先创建默认的迭代器,迭代器会利用__getitem__方法来进行遍历;
魔法函数__iter__方法必须返回Iterator;
from collections.abc import Iterator
class Company(object):
def __init__(self, employee_list):
self.employee = employee_list
def __iter__(self):
return MyIterator(self.employee)
class Company(object):
def __init__(self, employee_list):
self.employee = employee_list
def __iter__(self):
return MyIterator(self.employee)
#自定义一个迭代器
class MyIterator(Iterator):
def __init__(self, employee_list):
self.iter_list = employee_list
self.index = 0
def __next__(self):
#真正返回迭代值的逻辑
#迭代器不支持切片,不会产生一个索引值,因此需要在init下定义index
try:
word = self.iter_list[self.index]
except IndexError:
raise StopIteration
self.index += 1
return word
if __name__ == "__main__":
company = Company(["tom", "bob", "jane"])
my_itor = iter(company)
while True:
try:
print(next(my_itor))
except StopIteration:
pass
实际上,我们也可以在可迭代对象中直接实现__next__方法,但在编程规范中,当我们要去遍历一个数据结构时,我们一定要新建另外一种迭代器,然后将可迭代类型返回给迭代器,再用迭代器去维护index内部的一些变量。而不要在可迭代类型中直接去实现__next__方法,这样就可以将业务功能分开–迭代器的专门迭代器去维护,迭代类型的处理好自己功能。
5.3 生成器函数的使用
生成器函数是指函数里只要有yield关键字;
- 只要有yield就不是普通的函数;
- 不是普通的函数的意思是,生成器函数实际上是返回生成器对象;
py编译字节码的时候产生对象,python在运行之前,会将代码变为字节码,编译的时候就发现函数是个yield,所以其就会生成一个对象。然后这个对象,怎么才能访问到其中的值呢?
生成器对象实际上是实现了迭代器协议,再通过next找到第二个yield,故可以使用for循环来遍历其中的值。
正是因为yield是返回一个生成器的对象,为我们通过yield生成器,去实现协程,以及延迟求值提供了可能;
# 斐波拉起函数:
def fib(index):
if index <= 2:
return 1
else:
return fib(index-1) + fib(index-2)
# 希望能返回一个列表
def fib2(index):
re_list = []
n,a,b = 0,0,1
while n但是这样做会造成一个问题,如果index很大,list就会非常的消耗内存,如果使用yield,则不会消耗,因为它只有在进来的时候才会产生值。
#生成器产生的斐波拉契
def gen_fib(index):
n,a,b = 0,0,1
while n生成器函数会将每个数据都yield出来,它会知道什么时候把值yield出来。
5.4 py如何实现生成器
- python中函数的工作原理
def foo():
bar()
def bar():
pass
python的解释器,即python.exe,运行脚本时即通过解释器运行。这个脚本其实上是用c语言来写的,解释器会用一个叫做PyEvalFrameEx(c函数)去执行foo函数,首先会创建一个栈帧(stackframe),然后在栈帧的上下文中去运行字节码,这个字节码全局是唯一的;当foo调用子函数bar,其又会创建一个栈帧,然后将函数的控制权交给栈帧对象,这个栈帧会把bar的字节码运行。
栈帧不是关键,关键是所有的栈帧都是分配在堆内存上,堆内存即你不释放它,它就一直会在内存中;这就决定了栈帧可以独立于调用者存在,即此时调用bar的foo函数,即使退出也没关系,指针依然指着bar函数。
python中一切皆对象,栈帧对象,字节码对象;
import dis
print(dis.dis(foo))
-----------------------------
8 0 LOAD_GLOBAL 0 (bar)
2 CALL_FUNCTION 0
4 POP_TOP
6 LOAD_CONST 0 (None)
8 RETURN_VALUE
None
import inspect
frame = None
def foo():
bar()
def bar():
global frame
frame = inspect.currentframe()
foo()
# 栈帧
print(frame.f_code.co_name)
# 拿到调用它的一个栈帧
caller_frame = frame.f_back
print(caller_frame.f_code.co_name)
-------------------------------------------------
bar
foo
和静态语言的不同是,静态语言调用函数是一个栈的形式,函数调用完成整个栈会全部销毁,而py是放在堆上的。所以函数的调用是一个递归的现象的,在调用foo函数时,会创建一个栈帧,在调用子程序时,又会创建一个栈帧。
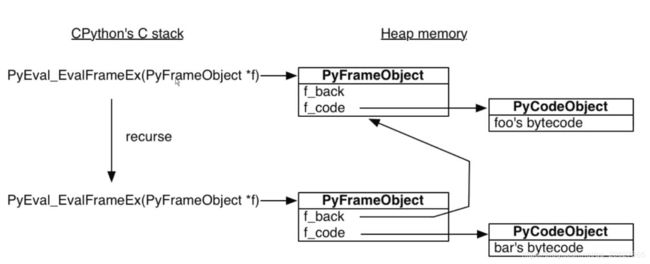
左边是cpython,即python解释器,其首先创建了一个Frameobject,这个战争对象中有f_back和f_code,f_code指向的是foo的字节码,在foo中调用了bar,同上一样,bar里也会创建f_back和f_code,这里的f_back指向其调用者。
生成器对象正是利用了python函数调用的过程,利用了其栈帧对象是分配在堆内存上的特性。所以生成器才有实现的可能。
# 生成器函数是可以像函数一样return一个值的
def gen_func():
yield 1
name = "bobby"
yield 2
age = 30
return "imooc"
python在生成器函数定义时,会找到一个yield关键词,将其标记为生成器对象。
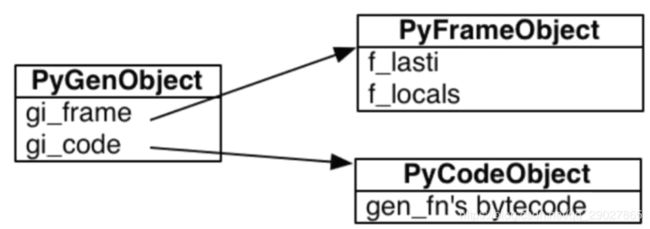
生成器对象在FrameObject和CodeObject上又加了一层,叫GenObject;
当每一次都生成器做调用时,其会运行到yield就停止,停止了后,FrameObject就会记录最近执行代码的最后一个位置,以及一个locals变量。
生成器对象也是分配在堆内存当中,所以其可以独立于调用者存在。只要我们拿到生成器对象,我们就可以控制它继续往前走。我们可以在任何地方拿到生成器对象,都可以去恢复,暂停它。而这,构成了协程的理论基础。
def gen_func():
yield 1
name = "bobby"
yield 2
age = 30
return "imooc"
import dis
gen = gen_func()
print (dis.dis(gen))
print(gen.gi_frame.f_lasti)
print(gen.gi_frame.f_locals)
next(gen)
print(gen.gi_frame.f_lasti)
print(gen.gi_frame.f_locals)
next(gen)
print(gen.gi_frame.f_lasti)
print(gen.gi_frame.f_locals)
5.5 生成器应用
-
UserList中的应用
UserList在以python的方式来解释list是如何做到的(因为list本身是用c语言写的),Userlist可以让我们来继承list。
我们看下其实现的__iter__方法:
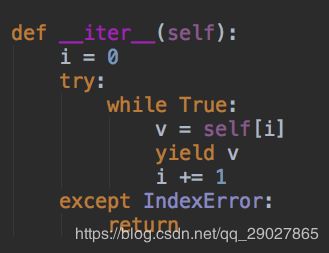
i记录了数组里的位置,由next方法每次调用来循环。 -
生成器表达式读取大文件
有一个文件,大概500个g,我们需要将这个文件一行一行的读取出来,然后把它写入到我们数据库当中。
开始的思路我们可以使用open来打开,接着再for line in f来一行一行读取,但是如果文件只有一行,而通过分隔符来进行分行时,再用list的方法显然有些麻烦,而且内存中放不下这么大的数据。
我们知道了read函数,默认的read()方法是可以一次性的将文件读取,但是如果我们的参数是2,那么我们就会每次读取两个字符,那么有一个想法就是,每次都读取一些字符,因为下一次再读取时,是第一次读取完的偏移量,直至将文件读完。
def myreadlines(f, newline):
# 定义缓存
buf = ""
while True:
# 查看缓存中的数据是否包含了分隔符
while newline in buf:
pos = buf.index(newline)
yield buf[:pos]
# 为了避免把两行数据读到了一个buf里
buf = buf[pos + len(newline):]
chunk = f.read(4096)
# 对文件的边缘条件做判断
if not chunk:
#说明已经读到了文件结尾
yield buf
break
buf += chunk
with open("input.txt") as f:
for line in myreadlines(f, "{|}"):
print (line)