Kafka精讲及常用开发代码,手动提交offset值
在公司的技术分享,

JMS
•JMS 是什么:JMS 是 Java 提供的一套技术规范
•JMS 干什么用:用来异构系统 集成通信,缓解系统瓶颈,提高系统的伸缩性增强系统用户体验, 使得系统模块化和组件化变得可行并更加灵活
•通过什么方式:生产消费者模式(生产者、服务器、消费者)
•JMS 核心组件
l Destination:消息发送的目的地,也就是前面说的Queue和Topic。
•l Message :从字面上就可以看出是被发送的消息。
•l Producer: 消息的生产者,要发送一个消息,必须通过这个生产者来发送。
•l MessageConsumer: 与生产者相对应,这是消息的消费者或接收者,通过它来接收一个消息。
•JMS 消息服务器 ActiveMQ
•ActiveMQ 是 Apache 出品,最流行的,能力强劲的开源消息总线。ActiveMQ 是一个完全支持 JMS1.1 和 J2EE 1.4 规范的。
•主要特点:
–l 多种语言和协议编写客户端。语言: Java, C, C++, C#, Ruby, Perl, Python, PHP。应用协议: OpenWire,Stomp REST,WS Notification,XMPP,AMQP
–l 完全支持 JMS1.1 和 J2EE 1.4 规范 (持久化,XA 消息,事务)
–l 对 Spring 的支持,ActiveMQ 可以很容易内嵌到使用 Spring 的系统里面去,而且也支持
–Spring2.0 的特性
–l 通过了常见 J2EE 服务器(如 Geronimo,JBoss 4, GlassFish,WebLogic)的测试,其中通过 JCA
–1.5 resource adaptors 的配置,可以让 ActiveMQ 可以自动的部署到任何兼容 J2EE 1.4 商业服
–务器上
–l 支持多种传送协议:in-VM,TCP,SSL,NIO,UDP,JGroups,JXTA
–l 支持通过JDBC和journal提供高速的消息持久化
–l 从设计上保证了高性能的集群,客户端-服务器,点对点
–l 支持Ajax
–l 支持与Axis的整合
•分布式消息中间件 Metamorphosis
•Metamorphosis (MetaQ) 是一个高性能、高可用、可扩展的分布式消息中间件,类似于 LinkedIn 的 Kafka,具有消息存储顺序写、吞吐量大和支持本地和 XA 事务等特性,适用于大吞吐量、顺序消 息、广播和日志数据传输等场景,在淘宝和支付宝有着广泛的应用,现已开源。
•主要特点:
•l 生产者、服务器和消费者都可分布 l 消息存储顺序写
l 性能极高,吞吐量大
l 支持消息顺序
•l 支持本地和XA事务
l 客户端 pull,随机读,利用 sendfile 系统调用,zero-copy ,批量拉数据 l 支持消费端事务
l 支持消息广播模式
l 支持异步发送消息
l 支持http协议
l 支持消息重试和recover
l 数据迁移、扩容对用户透明
l 消费状态保存在客户端
l 支持同步和异步复制两种HA
l 支持 group commit
•分布式消息中间件 RocketMQ
•RocketMQ 是一款分布式、队列模型的消息中间件,具有以下特点: l 能够保证严格的消息顺序
l 提供丰富的消息拉取模式
l 高效的订阅者水平扩展能力
•l 实时的消息订阅机制
l 亿级消息堆积能力
l Metaq3.0 版本改名,产品名称改为 RocketMQ


Kafka核心组件

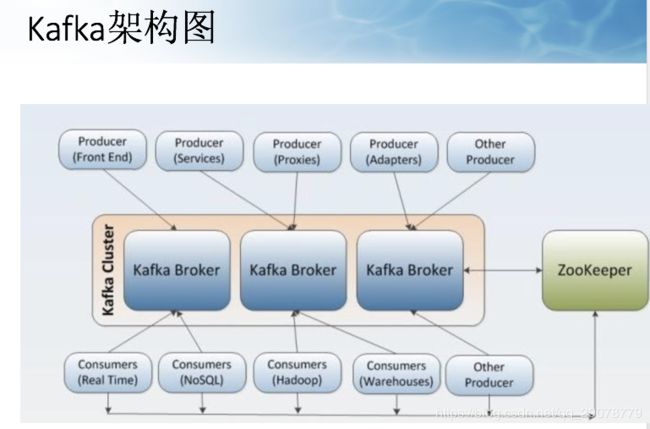
•Producer :消息生产者,就是向 kafka broker 发消息的客户端。
•
•Consumer :
•消息消费者,向 kafka broker 取消息的客户端
•
•Topic :名称。
•
•Consumer Group (CG):
•这是 kafka 用来实现一个 topic 消息的广播(发给所有的 consumer) 和单播(发给任意一个 consumer)的手段。
•
•一个 topic 可以有多个 CG。topic 的消息会复制(不 是真的复制,是概念上的)到所有的 CG,
•但每个 partion 只会把消息发给该 CG 中的一个 consumer。
•如果需要实现广播,只要每个 consumer 有一个独立的 CG 就可以了。要实现单播只 要所有的 consumer 在同一个 CG。用 CG 还可以将 consumer 进行自由的分组而不需要多次发送 消息到不同的 topic。
•
•Partition:
•为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
•partition 中的每条消息都会被分 配一个有序的 id(offset)。kafka 只保证按一个 partition 中的顺序将消息发给 consumer,不保 证一个 topic 的整体(多个 partition 间)的顺序。
•
•Offset:
•kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例 如你想找位于 2049 的位置,只要找到 2048.kafka 的文件即可。当然 the first offset 就是 00000000000.kafka
•
•Replication:
•Kafka 支持以 Partition 为单位对 Message 进行冗余备份,每个 Partition 都可以配 置至少 1 个 Replication(当仅 1 个 Replication 时即仅该 Partition 本身)。
•
•Leader:
•每个Replication集合中的Partition都会选出一个唯一的Leader,所有的读写请求都由 Leader 处理。
•其他 Replicas 从 Leader 处把数据更新同步到本地,过程类似大家熟悉的 MySQL 中的 Binlog 同步。
•每个 Cluster 当中会选举出一个 Broker 来担任 Controller,负责处理 Partition 的 Leader 选举,协调 Partition 迁移等工作。
•
•
•SR(In-SyncReplica):
•是Replicas的一个子集,表示目前Alive且与Leader能够“Catch-up”的 Replicas 集合。由于读写都是首先落到 Leader 上,所以一般来说通过同步机制从 Leader 上拉取 数据的Replica都会和Leader有一些延迟(包括了延迟时间和延迟条数两个维度),任意一个超过阈值都会把该 Replica 踢出 ISR。每个 Partition 都有它自己独立的 ISR。
•
•
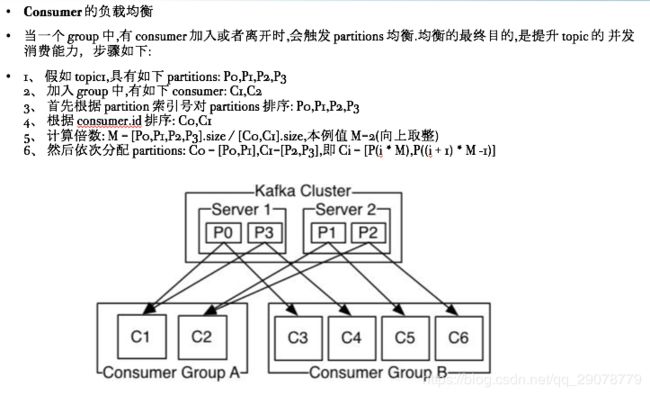
•Consumer 与 topic 关系
•本质上 kafka 只支持 Topic;
•
l 每个 group 中可以有多个 consumer,每个 consumer 属于一个 consumer group; 通常情况下,一个 group 中会包含多个 consumer,这样不仅可以提高 topic 中消息的并发消费能 力,而且还能提高"故障容错"性,如果 group 中的某个 consumer 失效那么其消费的 partitions 将会有 其他 consumer 自动接管。
•
l 对于Topic中的一条特定的消息,只会被订阅此Topic的每个group中的其中一个consumer消 费,此消息不会发送给一个 group 的多个 consumer; 那么一个 group 中所有的 consumer 将会交错的消费整个 Topic,每个 group 中 consumer 消息消 费互相独立,我们可以认为一个 group 是一个"订阅"者。
•
l 在kafka中,一个partition中的消息只会被group中的一个consumer消费(同一时刻);一个 Topic 中的每个 partions,只会被一个"订阅者"中的一个 consumer 消费,不过一个 consumer 可 以同时消费多个 partitions 中的消息。
•
l kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同
•时消费,否则将意味着某些 consumer 将无法得到消息。
•
•kafka 只能保证一个 partition 中的消息被某个 consumer 消费时是顺序的;事实上,从 Topic 角度来说,当有多个 partitions 时,消息仍不是全局有序的。
•
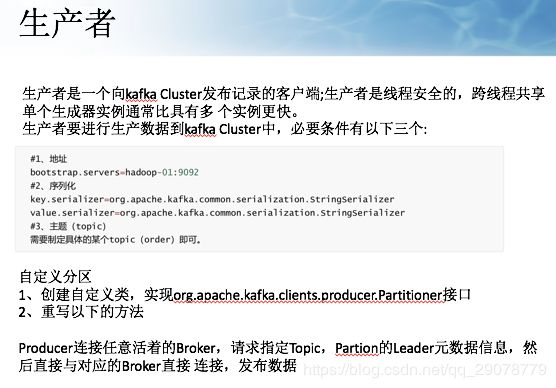
•Producer 客户端负责消息的分发
•l kafka集群中的任何一个broker都可以向producer提供metadata信息,这些metadata中包含"
•集群中存活的 servers 列表"/"partitions leader 列表"等信息;
•l 当 producer 获取到 metadata 信息之后, producer 将会和 Topic 下所有 partition leader 保持 socket 连接;
•l 消息由producer直接通过socket发送到broker,中间不会经过任何"路由层",事实上,消
•息被路由到哪个 partition 上由 producer 客户端决定;
•
•比如可以采用"random""key-hash""轮询等,如果一个 topic 中有多个 partitions,那么在 producer 端实现"消息均衡分发"是必要的。
l 在producer端的配置文件中,开发者可以指定partition路由的方式。
•Producer 消息发送的应答机制 设置发送数据是否需要服务端的反馈,有三个值 0,1,-1
•0: producer 不会等待 broker 发送 ack
1: 当 leader 接收到消息之后发送 ack
-1: 当所有的 follower 都同步消息成功后发送 ack
•request.required.acks=0



Kafka体验



kafka-Stream