pyspark使用教程(一)
使用Pyspark教程,参考《Spark快速大数据分析》
1. Spark背景
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
2. Spark安装
https://mp.weixin.qq.com/s?__biz=MzI5MzIwNDI1MQ==&mid=2650120932&idx=5&sn=fa924c8677411661a31df945b330c028&chksm=f474ba90c303338678dcd26edd5707d667c4bbe4a93b1f4e33591892cd858fd2da8db988be38&mpshare=1&scene=23&srcid=0117k0pBqKT5ucoXacbBHMfW&client=tim&ADUIN=278793087&ADSESSION=1517886579&ADTAG=CLIENT.QQ.5537_.0&ADPUBNO=26752#rd
上述是windows,本公司用的是CDH搭建
3. 打开shell
进入Spark目录,
Python: bin/pyspark(bin\pyspark)
Scala:bin/spark-shell
3.1. 修改日志
方法一:sc.setLogLevel('WARN')
方法二:
如果觉得shell 中输出的日志信息过多而使人分心,可以调整日志的级别来控制输出的信
息量。你需要在conf 目录下创建一个名为log4j.properties 的文件来管理日志设置。Spark
开发者们已经在Spark 中加入了一个日志设置文件的模版,叫作log4j.properties.template。
要让日志看起来不那么啰嗦,可以先把这个日志设置模版文件复制一份到conf/log4j.
properties 来作为日志设置文件,接下来找到下面这一行:
log4j.rootCategory=INFO, console
然后通过下面的设定降低日志级别,只显示警告及更严重的信息:
log4j.rootCategory=WARN, console
3.2. 使用Ipython
使用IPython
IPython 是一个受许多Python 使用者喜爱的增强版Python shell,能够提供自
动补全等好用的功能。你可以在http://ipython.org 上找到安装说明。只要把
环境变量IPYTHON 的值设为1,你就可以使用IPython 了:
IPYTHON=1 ./bin/pyspark
要使用IPython Notebook,也就是Web 版的IPython,可以运行:
IPYTHON_OPTS="notebook" ./bin/pyspark
在Windows 上,像下面这样设置环境变量并运行命令行:
set IPYTHON=1
bin\pyspark
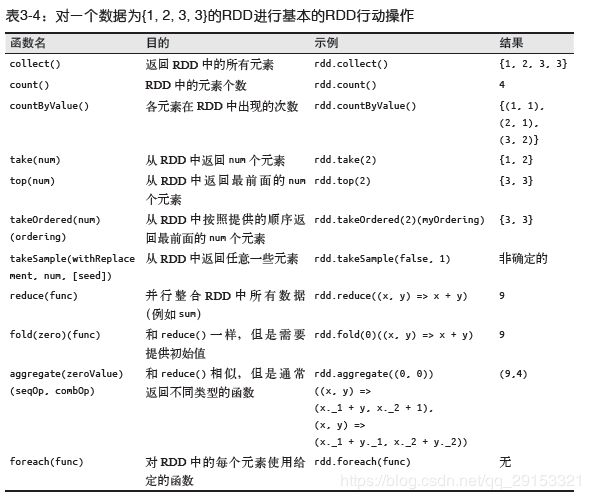
4. RDD编程
转化操作:转化为新的RDD:map/filter
行动操作:实际的计算:count/first
惰性求值 思想
存储内存,多次使用
pythonLines.persist
collect不能用在大规模数据上,用take。
flatMap() 和map() 的区别:flatMap()返回一个由各列表中的元素组成的RDD,而不是一个由列表组成的RDD。
4.1. 在Python 中初始化Spark
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)
4.2. 创建RDD
1.读取外部数据
lines = sc.textFile("README.md"),分别为file:///和hdfs://
2.parallelize() 方法
lines = sc.parallelize(list(range(100)))
4.3. RDD操作
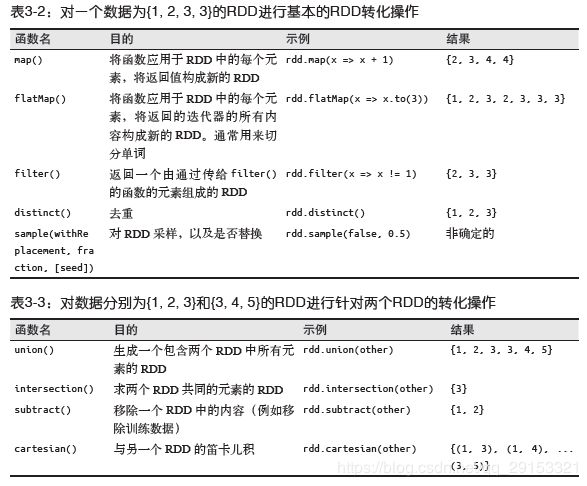
4.4. Pair RDD键值对操作
4.4.1. 创建键值对
在Python 中使用第一个单词作为键创建出一个pair RDD
pairs = lines.map(lambda x: (x.split(" ")[0], x))
4.4.2. Pair RDD操作




4.5. 数据保存
sqlDF.coalesce(2).write.parquet("hdfs:///5min/","overwrite")
#sqlDF.rdd.repartition(1).saveAsTextFile("hdfs:///test/cz")
5. 累加器和广播变量
共享变量:累加器用来对信息进行聚合,而广播变量用来高效分发较大的对象。
加法操作Spark 的一种累加器类型整型(Accumulator[Int])。Spark 还直接支持Double、Long 和Float 型的累加器。
# 创建用来验证呼号的累加器
validSignCount = sc.accumulator(0)
invalidSignCount = sc.accumulator(0)
def validateSign(sign):
global validSignCount, invalidSignCount
if re.match(r"\A\d?[a-zA-Z]{1,2}\d{1,4}[a-zA-Z]{1,3}\Z", sign):
validSignCount += 1
return True
else:
invalidSignCount += 1
return False
# 对与每个呼号的联系次数进行计数
validSigns = callSigns.filter(validateSign)
contactCount = validSigns.map(lambda sign: (sign, 1)).reduceByKey(lambda (x, y): x
+ y)
# 强制求值计算计数
contactCount.count()
if invalidSignCount.value < 0.1 * validSignCount.value:
contactCount.saveAsTextFile(outputDir + "/contactCount")
else:
print "Too many errors: %d in %d" % (invalidSignCount.value, validSignCount.value)
broadcast

5. 集群运行
5.1. Spark运行架构

5.2. 使用spark-submit提交

使用独立集群模式提交Java应用
$ ./bin/spark-submit \
--master spark://hostname:7077 \
--deploy-mode cluster \
--class com.databricks.examples.SparkExample \
--name "Example Program" \
--jars dep1.jar,dep2.jar,dep3.jar \
--total-executor-cores 300 \
--executor-memory 10g \
myApp.jar "options" "to your application" "go here"
# 使用YARN客户端模式提交Python应用
$ export HADOP_CONF_DIR=/opt/hadoop/conf
$ ./bin/spark-submit \
--master yarn \
--py-files somelib-1.2.egg,otherlib-4.4.zip,other-file.py \
--deploy-mode client \
--name "Example Program" \
--queue exampleQueue \
--num-executors 40 \
--executor-memory 10g \
my_script.py "options" "to your application" "go here"
5.3. Spark独立集群启动方式
(1) 将编译好的Spark 复制到所有机器的一个相同的目录下,比如/home/yourname/spark。
(2) 设置好从主节点机器到其他机器的SSH 无密码登陆。这需要在所有机器上有相同的用
户账号,并在主节点上通过ssh-keygen 生成SSH 私钥,然后将这个私钥放到所有工作
节点的.ssh/authorized_keys 文件中。如果你之前没有设置过这种配置,你可以使用如下
命令:
# 在主节点上:运行ssh-keygen并接受默认选项
$ ssh-keygen -t dsa
Enter file in which to save the key (/home/you/.ssh/id_dsa): [回车]
Enter passphrase (empty for no passphrase): [空]
Enter same passphrase again: [空]
# 在工作节点上:
# 把主节点的~/.ssh/id_dsa.pub文件复制到工作节点上,然后使用:
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
$ chmod 644 ~/.ssh/authorized_keys
(3) 编辑主节点的conf/slaves 文件并填上所有工作节点的主机名。
(4) 在主节点上运行sbin/start-all.sh(要在主节点上运行而不是在工作节点上)以启动集群。
如果全部启动成功,你不会得到需要密码的提示符,而且可以在http://masternode:8080
看到集群管理器的网页用户界面,上面显示着所有的工作节点。
(5) 要停止集群,在主节点上运行bin/stop-all.sh。