opencv实战3: CascadeClassifier+Haar特征进行人脸检测
1、级联分类器CascadeClassifier
OpenCV官方文档:https://docs.opencv.org/3.4.3/d5/d54/group__objdetect.html
分类器: 判别某个事物是否属于某种分类的器件,两种结果:是、否 。
级联分类器: 可以理解为将N个单类的分类器串联起来。如果一个事物能属于这一系列串联起来的的所有分类器,则最终结果就是 是,若有一项不符,则判定为否。
比如人脸,它有很多属性,我们将每个属性做一成个分类器,如果一个模型符合了我们定义的人脸的所有属性,则我们人为这个模型就是一个人脸。那么这些属性是指什么呢? 比如人脸需要有两条眉毛,两只眼睛,一个鼻子,一张嘴,一个大概U形状的下巴或者是轮廓等等。
CascadeClassifier为OpenCV下用来做目标检测的级联分类器的一个类。该类中封装的目标检测机制,简而言之是滑动窗口机制+级联分类器的方式
级联分类器检测类CascadeClassifier,在2.4.5版本中使用Adaboost的方法+LBP、HOG、HAAR进行目标检测,加载的是使用traincascade进行训练的分类器
源码定义:
class CV_EXPORTS_W CascadeClassifier
{
public:
CV_WRAP CascadeClassifier();
CV_WRAP CascadeClassifier(const String& filename); //从文件中加载级联分类器
~CascadeClassifier();
CV_WRAP bool empty() const; //检测级联分类器是否被加载
CV_WRAP bool load( const String& filename ); //从文件中加载级联分类器
CV_WRAP bool read( const FileNode& node ); //从FileStorage节点读取分类器
/** 检测输入图像中不同大小的对象。检测到的对象以矩形列表的形式返回。
参数:
image: 包含检测对象的图像的CV_8U类型矩阵
objects: 矩形的向量,其中每个矩形包含被检测的对象,矩形可以部分位于原始图像之外
scaleFactor: 指定在每个图像缩放时的缩放比例
minNeighbors:指定每个候选矩形需要保留多少个相邻矩形
flags:含义与函数cvHaarDetectObjects中的旧级联相同。它不用于新的级联
minSize:对象最小大小,小于该值的对象被忽略。
maxSize:最大可能的对象大小,大于这个值的对象被忽略
*/
CV_WRAP void detectMultiScale( InputArray image,
CV_OUT std::vector& objects,
double scaleFactor = 1.1,
int minNeighbors = 3, int flags = 0,
Size minSize = Size(),
Size maxSize = Size() );
/**
detectMultiScale重载函数
参数:
image:包含检测对象的图像的CV_8U类型矩阵
objects: 矩形的向量,其中每个矩形包含被检测的对象,矩形可以部分位于原始图像之外
numDetections: 对应对象的检测编号向量。一个物体被探测到的次数是相邻的被积极分类的矩形的数量,这些矩形被连接在一起形成物体
scaleFactor: 指定在每个图像缩放时的缩放比例
minNeighbors:指定每个候选矩形需要保留多少个相邻矩形
flags:含义与函数cvHaarDetectObjects中的旧级联相同。它不用于新的级联
minSize:对象最小大小,小于该值的对象被忽略。
maxSize:最大可能的对象大小,大于这个值的对象被忽略
*/
CV_WRAP_AS(detectMultiScale2) void detectMultiScale( InputArray image,
CV_OUT std::vector& objects,
CV_OUT std::vector& numDetections,
double scaleFactor=1.1,
int minNeighbors=3, int flags=0,
Size minSize=Size(),
Size maxSize=Size() );
/*
detectMultiScale重载函数,此函数允许您检索分类的最终阶段决策确定性
为此,需要将' outputRejectLevels '设置为true,并提供' rejectLevels '和' levelWeights '参数。
对于每一个结果检测,‘levelWeights’将在最后阶段包含分类的确定性。这个值可以用来区分强分类和弱分类。 */
CV_WRAP_AS(detectMultiScale3) void detectMultiScale( InputArray image,
CV_OUT std::vector& objects,
CV_OUT std::vector& rejectLevels,
CV_OUT std::vector& levelWeights,
double scaleFactor = 1.1,
int minNeighbors = 3, int flags = 0,
Size minSize = Size(),
Size maxSize = Size(),
bool outputRejectLevels = false );
具体使用示例代码
Mat img;
vector weights;
vector levels;
vector detections;
CascadeClassifier model("/path/to/your/model.xml");
model.detectMultiScale(img, detections, levels, weights, 1.1, 3, 0, Size(), Size(), true);
cerr << "Detection " << detections[0] << " with weight " << weights[0] << endl;
}; from: https://blog.csdn.net/u012819339/article/details/82493699
关于更多CascadeClassifier类:https://blog.csdn.net/xidianzhimeng/article/details/41851569
2、支持的特征
opencv目前仅支持三种特征的训练检测, HAAR、LBP、HOG,opencv的这个训练算法是基于adaboost而来的??
对于Haar、LBP和HOG:
1) Haar:从OpenCV1.0以来,一直都是只有用haar特征的级联分类器训练和检测(检测函数称为cvHaarDetectObjects,训练得到的也是特征和node放在一起的xml),在之后当CascadeClassifier出现并统一三种特征到同一种机制和数据结构下时,没有放弃原来的C代码编写的haar检测,仍保留了原来的检测部分。另外,Haar在检测中无论是特征计算环节还是判断环节都是三种特征中最简洁的,但是笔者的经验中他的训练环节却往往是耗时最长的。
2) LBP:LBP在2.2中作为人脸检测的一种方法和Haar并列出现,他的单个点的检测方法是三者中较为复杂的一个,所以当检测的点数相同时,如果不考虑特征计算时间,仅计算判断环节,他的时间是最长的。
3) HOG:在2.4.0中开始出现在该类中的HOG检测,其实并不是OpenCV的新生力量,因为在较早的版本中HOG特征已经开始作为单独的行人检测模块出现。比较起来,虽然HOG在行人检测和这里的检测中同样是滑窗机制,但是一个是级联adaboost,另一个是SVM;而且HOG特征为了加入CascadeClassifier支持的特征行列改变了自身的特征计算方式:不再有相邻cell之间的影响,并且采用在Haar和LBP上都可行的积分图计算,放弃了曾经的HOGCache方式,虽然后者的加速性能远高于前者,而简单的HOG特征也使得他的分类效果有所下降(如果用SVM分类器对相同样本产生的两种HOG特征做分类,没有了相邻cell影响的计算方式下的HOG特征不那么容易完成分类)。这些是HOG为了加入CascadeClassifier而做出的牺牲,不过你肯定也想得到OpenCV保留了原有的HOG计算和检测机制。另外,HOG在特征计算环节是最耗时的,但他的判断环节和Haar一样的简洁。
3.CascadeClassifier检测的基本原理:
xml中存放的是训练后的特征池,特征size大小根据训练时的参数而定,检测的时候可以简单理解为就是将每个固定size特征(检测窗口)与输入图像的同样大小区域比较,如果匹配那么就记录这个矩形区域的位置,然后滑动窗口,检测图像的另一个区域,重复操作。由于输入的图像中特征大小不定,比如在输入图像中眼睛是50x50的区域,而训练时的是25x25,那么只有当输入图像缩小到一半的时候,才能匹配上,所以这里还有一个逐步缩小图像,也就是制作图像金字塔的流程.
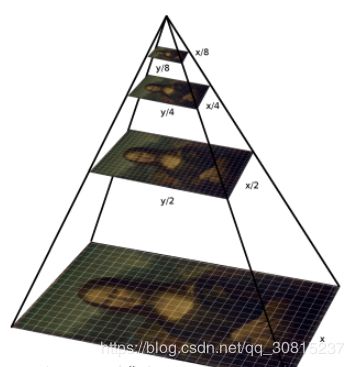
由于人脸可能出现在图像的任何位置,在检测时用固定大小的窗口对图像从上到下、从左到右扫描,判断窗口里的子图像是否为人脸,这称为滑动窗口技术(sliding window)。为了检测不同大小的人脸,还需要对图像进行放大或者缩小构造图像金字塔,对每张缩放后的图像都用上面的方法进行扫描。由于采用了滑动窗口扫描技术,并且要对图像进行反复缩放然后扫描,因此整个检测过程会非常耗时。
以512x512大小的图像为例,假设分类器窗口为24x24,滑动窗口的步长为1,则总共需要扫描的窗口数为:以512x512大小的图像为例,假设分类器窗口为24x24,滑动窗口的步长为1,则总共需要扫描的窗口数为:
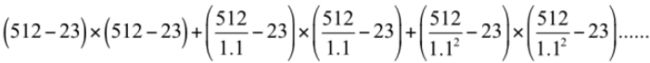
即要检测一张图片需要扫描大于120万个窗口!!!计算量惊人,因此有必要采取某种措施提高效率
from:https://blog.csdn.net/qq_37791134/article/details/80583726
4、detectMultiScale函数详解
cvHaarDetectObjects是opencv1中的函数,opencv2中人脸检测使用的是 detectMultiScale函数。它可以检测出图片中所有的人脸,并将人脸用vector保存各个人脸的坐标、大小(用矩形表示),函数由分类器对象调用:
void detectMultiScale(
const Mat& image,
CV_OUT vector& objects,
double scaleFactor = 1.1,
int minNeighbors = 3,
int flags = 0,
Size minSize = Size(),
Size maxSize = Size()
);
函数介绍:
image--待检测图片,一般为灰度图像加快检测速度;
objects--被检测物体的矩形框向量组,其中每个矩形包含被检测的对象,矩形可以部分位于原始图像之外
scaleFactor--表示在前后两次相继的扫描中,搜索窗口的比例系数。默认为1.1即每次搜索窗口依次扩大10%;
minNeighbors--指定每个候选矩形需要保留多少个相邻矩形,表示构成检测目标的相邻矩形的最小个数(默认为3个)。
如果组成检测目标的小矩形的个数和小于 min_neighbors - 1 都会被排除。
如果min_neighbors 为 0, 则函数不做任何操作就返回所有的被检候选矩形框,
这种设定值一般用在用户自定义对检测结果的组合程序上;
flags=0:可以取如下这些值:
CASCADE_DO_CANNY_PRUNING=1, 利用canny边缘检测来排除一些边缘很少或者很多的图像区域
CASCADE_SCALE_IMAGE=2, 正常比例检测
CASCADE_FIND_BIGGEST_OBJECT=4, 只检测最大的物体
CASCADE_DO_ROUGH_SEARCH=8 初略的检测
minSize和maxSize用来限制得到的目标区域的范围。
minSize:对象最小大小,小于该值的对象被忽略。
maxSize:最大可能的对象大小,大于这个值的对象被忽略
5、官网实例:
步骤:
调用opencv训练好的分类器和自带的检测函数检测人脸人眼等的步骤简单直接:
1.加载分类器,分类器就是一个XML文件,该文件中会描述人体各个部位的Haar特征值。包括人脸、眼睛、嘴唇、侧脸、微笑、上半身、下半身、全身等等。分类器本来的位置是在*\opencv\sources\data(harr分类器,也有其他的可以用;也可以自己训练,traincascade的独立应用程序可以从一组样本中训练一系列增强分类器,位置在“\opencv\sources\apps”)

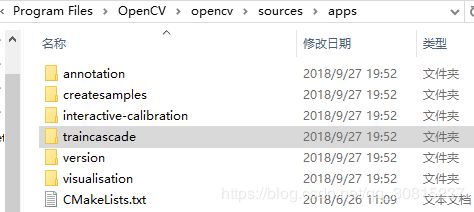
在右上图中,文件夹的名字“haarcascades”、“haarcascades_cuda”、“hogcascades”和“lbpcascades”分别表示通过“haar”、 “harr”、“hog”和“lbp”三种不同的特征而训练出的分类器:即各文件夹里的文件。"haar"特征主要用于人脸检测,“hog”特征主要用于行人检测,“lbp”特征主要用于人脸识别。打开“haarcascades_cuda”文件夹,如下图所示

图中的XML文件即是我们人脸检测所需要的分类器文件。在实际使用中,推荐使用上图中被标记的“haarcascade_frontalface_alt2.xml”分类器文件,准确率和速度都比较好
更多分类器xml文件:https://github.com/opencv/opencv/tree/master/data/haarcascades
2.调用detectMultiScale()函数检测,调整函数的参数可以使检测结果更加精确。
3.把检测到的人脸等用矩形(或者圆形等其他图形)画出来。
//使用 CascadeClassifier进行人脸检测,可运行,还未详细了解
#include
#include
#include
#include
using namespace std;
using namespace cv;
static void help()
{
cout << "\nThis program demonstrates the use of cv::CascadeClassifier class to detect objects (Face + eyes). You can use Haar or LBP features.\n"
"This classifier can recognize many kinds of rigid objects, once the appropriate classifier is trained.\n"
"It's most known use is for faces.\n"
"Usage:\n"
"./facedetect [--cascade= this is the primary trained classifier such as frontal face]\n"
" [--nested-cascade[=nested_cascade_path this an optional secondary classifier such as eyes]]\n"
" [--scale=]\n"
" [--try-flip]\n"
" [filename|camera_index]\n\n"
"see facedetect.cmd for one call:\n"
"./facedetect --cascade=\"../../data/haarcascades/haarcascade_frontalface_alt.xml\" --nested-cascade=\"../../data/haarcascades/haarcascade_eye_tree_eyeglasses.xml\" --scale=1.3\n\n"
"During execution:\n\tHit any key to quit.\n"
"\tUsing OpenCV version " << CV_VERSION << "\n" << endl;
}
void detectAndDraw(Mat& img, CascadeClassifier& cascade,
CascadeClassifier& nestedCascade,
double scale, bool tryflip);
string cascadeName; //face级联器(xml文件)路径
string nestedCascadeName;//eye级联器路径
int main(int argc, const char** argv)
{
VideoCapture capture;
Mat frame, image;
string inputName;
bool tryflip;
CascadeClassifier cascade, nestedCascade;
double scale;
cv::CommandLineParser parser(argc, argv,
"{help h||}"
"{cascade|D:/Program Files/OpenCV/opencv/sources/data/haarcascades/haarcascade_frontalface_alt.xml|}"
"{nested-cascade|D:/Program Files/OpenCV/opencv/sources/data/haarcascades/haarcascade_eye_tree_eyeglasses.xml|}"
"{scale|1|}{try-flip||}{@filename|111.jpg|}"
);
if (parser.has("help"))
{
help();
return 0;
}
cascadeName = parser.get("cascade");
nestedCascadeName = parser.get("nested-cascade");
scale = parser.get("scale");
if (scale < 1)
scale = 1;
tryflip = parser.has("try-flip"); //图片翻转
inputName = parser.get("@filename");
if (!parser.check())
{
parser.printErrors();
return 0;
}
if (!nestedCascade.load(nestedCascadeName))
cerr << "WARNING: Could not load classifier cascade for nested objects" << endl;
if (!cascade.load(cascadeName))
{
cerr << "ERROR: Could not load classifier cascade" << endl;
help();
return -1;
}
//else if:如果if的判断没有通过,则进行下面的else if,如果当前的else if判断通过,则执行当前else if的语句。如果if中的条件已经满足了,就不会去判断else if中的条件了
//pS:双if是每一个if都会进行判断,依次对if进行判断,互相之间不会影响;这是与if else if组合的不同之处
//else:else为最后的分支,如果在else之前的if、else if判断都没有通过,就会执行else
//PS:在一条if条件判断中,可以有无数条else if,但是只能有一个else
//PS:如果没有通过当前else if,则一直执行下面的else if判断,如果最后所有else if判断都没有通过,则执行else语句(else为无条件通过),如果也没有else,则最终跳出当前if判断语句
if (inputName.empty() || (isdigit(inputName[0]) && inputName.size() == 1))
{
int camera = inputName.empty() ? 0 : inputName[0] - '0';
if (!capture.open(camera))
cout << "Capture from camera #" << camera << " didn't work" << endl;
}
else if (inputName.size())
{
image = imread(inputName, 1);
if (image.empty())
{
if (!capture.open(inputName))
cout << "Could not read " << inputName << endl;
}
}
else
{
image = imread("E:/test_opencv/ConsoleOpenCV/ConsoleOpenCV/121.jpg", 1);
if (image.empty()) cout << "Couldn't read ../data/lena.jpg" << endl;
}
if (capture.isOpened())
{
cout << "Video capturing has been started ..." << endl;
for (;;)
{
capture >> frame;
if (frame.empty())
break;
Mat frame1 = frame.clone();
detectAndDraw(frame1, cascade, nestedCascade, scale, tryflip);
char c = (char)waitKey(10);
if (c == 27 || c == 'q' || c == 'Q')
break;
}
}
else
{
cout << "Detecting face(s) in " << inputName << endl;
if (!image.empty())
{
detectAndDraw(image, cascade, nestedCascade, scale, tryflip);
waitKey(0);
}
else if (!inputName.empty())
{
/* assume it is a text file containing the
list of the image filenames to be processed - one per line */
FILE* f = fopen(inputName.c_str(), "rt");
if (f)
{
char buf[1000 + 1];
while (fgets(buf, 1000, f))
{
int len = (int)strlen(buf);
while (len > 0 && isspace(buf[len - 1]))
len--;
buf[len] = '\0';
cout << "file " << buf << endl;
image = imread(buf, 1);
if (!image.empty())
{
detectAndDraw(image, cascade, nestedCascade, scale, tryflip);
char c = (char)waitKey(0);
if (c == 27 || c == 'q' || c == 'Q')
break;
}
else
{
cerr << "Aw snap, couldn't read image " << buf << endl;
}
}
fclose(f);
}
}
}
system("pause");
return 0;
}
//void mysort(Mat a)的a是值传递方式值传递:形参是实参的拷贝,改变形参的值并不会影响外部实参的值。
//从被调用函数的角度来说,值传递是单向的(实参->形参),参数的值只能传入,不能传出。
//当函数内部需要修改参数,并且不希望这个改变影响调用者时,采用值传递。
//void mysort(mat& a)的&a是引用传递方式引用传递:形参相当于是实参的“别名”,
//对形参的操作其实就是对实参的操作,在引用传递过程中,被调函数的形式参数虽然也作为局部变量在栈中开辟了内存空间,但是这时存放的是由主调函数放进来的实参变量的地址。
//被调函数对形参的任何操作都被处理成间接寻址,即通过栈中存放的地址访问主调函数中的实参变量。正因为如此,被调函数对形参做的任何操作都影响了主调函数中的实参变量
void detectAndDraw(Mat& img, CascadeClassifier& cascade,
CascadeClassifier& nestedCascade,
double scale, bool tryflip)
{
double t = 0;
vector faces, faces2;//矩形类(x,y,w,h)
const static Scalar colors[] =
{
Scalar(255,0,0),
Scalar(255,128,0),
Scalar(255,255,0),
Scalar(0,255,0),
Scalar(0,128,255),
Scalar(0,255,255),
Scalar(0,0,255),
Scalar(255,0,255)
};
Mat gray, smallImg;
cvtColor(img, gray, COLOR_BGR2GRAY);
double fx = 1 / scale;
resize(gray, smallImg, Size(), fx, fx, INTER_LINEAR_EXACT);
equalizeHist(smallImg, smallImg);
t = (double)getTickCount();//返回从操作系统启动到当前所经的计时周期数
cascade.detectMultiScale(smallImg, faces,
1.1, 2, 0
//|CASCADE_FIND_BIGGEST_OBJECT
//|CASCADE_DO_ROUGH_SEARCH
| CASCADE_SCALE_IMAGE,
Size(30, 30));
if (tryflip)
{
flip(smallImg, smallImg, 1);
cascade.detectMultiScale(smallImg, faces2,
1.1, 2, 0
//|CASCADE_FIND_BIGGEST_OBJECT
//|CASCADE_DO_ROUGH_SEARCH
| CASCADE_SCALE_IMAGE,
Size(30, 30));
for (vector::const_iterator r = faces2.begin(); r != faces2.end(); ++r)
{
faces.push_back(Rect(smallImg.cols - r->x - r->width, r->y, r->width, r->height));
}
}
t = (double)getTickCount() - t;
printf("detection time = %g ms\n", t * 1000 / getTickFrequency());
for (size_t i = 0; i < faces.size(); i++)
{
Rect r = faces[i];
Mat smallImgROI;
vector nestedObjects;
Point center;
Scalar color = colors[i % 8];
int radius;
double aspect_ratio = (double)r.width / r.height;
if (0.75 < aspect_ratio && aspect_ratio < 1.3)
{
center.x = cvRound((r.x + r.width*0.5)*scale);
center.y = cvRound((r.y + r.height*0.5)*scale);
radius = cvRound((r.width + r.height)*0.25*scale);
circle(img, center, radius, color, 3, 8, 0);
}
else
rectangle(img, Point(cvRound(r.x*scale), cvRound(r.y*scale)),
Point(cvRound((r.x + r.width - 1)*scale), cvRound((r.y + r.height - 1)*scale)),
color, 3, 8, 0);
if (nestedCascade.empty())
continue;
smallImgROI = smallImg(r);
nestedCascade.detectMultiScale(smallImgROI, nestedObjects,
1.1, 2, 0
//|CASCADE_FIND_BIGGEST_OBJECT
//|CASCADE_DO_ROUGH_SEARCH
//|CASCADE_DO_CANNY_PRUNING
| CASCADE_SCALE_IMAGE,
Size(30, 30));
for (size_t j = 0; j < nestedObjects.size(); j++)
{
Rect nr = nestedObjects[j];
center.x = cvRound((r.x + nr.x + nr.width*0.5)*scale);
center.y = cvRound((r.y + nr.y + nr.height*0.5)*scale);
radius = cvRound((nr.width + nr.height)*0.25*scale);
circle(img, center, radius, color, 3, 8, 0);
}
}
imshow("result", img);
}
代码地址:https://github.com/liuzheCSDN/OpenCV/blob/master/facedelete/haar_cascades.cpp
Haar特征原理:
1、简述:
openCV的的Haar分类器是一个监督分类器,首先对图像进行直方图均衡化并归一化到同样大小(例如,20x20),然后标记里面是否包含要监测的物体。为了检测整副图像,可以在图像中移动搜索窗口,检测每一个位置来确定可能的目标。 为了搜索不同大小的目标物体,分类器被设计为可以进行尺寸改变,这样比改变待检图像的尺寸大小更为有效。所以,为了在图像中检测未知大小的目标物体,扫描程序通常需要用不同比例大小的搜索窗口对图片进行几次扫描。
分类器中的“级联”是指最终的分类器是由几个简单分类器级联组成。在图像检测中,被检窗口依次通过每一级分类器,这样在前面几层的检测中大部分的候选区域就被排除了,全部通过每一级分类器检测的区域即为目标区域。该分类器在级联的每个节点中使用AdaBoost来学习一个高检测率低拒绝率的多层树分类器。它使用了以下一些新的特征:
1. 使用类Haar输入特征:对矩形图像区域的和或者差进行阈值化。
2.积分图像技术加速了矩形区域的45°旋转的值的计算,用来加速类Haar输入特征的计算。
3.使用统计boosting来创建两类问题(人脸和非人脸)的分类器节点(高通过率,低拒绝率)
4.把弱分类器节点组成筛选式级联。即,第一组分类器最优,能通过包含物体的图像区域,同时允许一些不包含物体通过的图像通过;第二组分类器次优分类器,也是有较低的拒绝率;以此类推。也就是说,对于每个boosting分类器,只要有人脸都能检测到,同时拒绝一小部分非人脸, 并将其传给下一个分类器,是为低拒绝率。以此类推,最后一个分类器将几乎所有的非人脸都拒绝掉,只剩下人脸区域。只要图像区域通过了整 个级联,则认为里面有物体。
2、Haar 特征获取
基于Haar特征的cascade分类器(classifiers) 是Paul Viola和 Michael Jone在2001年,论文”Rapid Object Detection using a Boosted Cascade of Simple Features”中提出的一种有效的物品检测(object detect)方法。它是一种机器学习方法,通过许多正负样例中训练得到cascade方程,然后将其应用于其他图片。
现在让我们来看以下人脸检测是如何工作的。首先,算法需要许多正样例(包含人脸的图片)和负样例(不包含人脸的图片)来训练分类器。然后我们要从这些图片中获取特征(extract features)。如下所示为Haar 特征获取的方式。和卷积核(conventional kernel)类似,每个特征由白方块下的像素和减去黑方块的像素和来得到。
在Haar-like特征提出之前,传统的人脸检测算法一般是基于图像像素值进行的,计算量较大且实时性较差。Papageorgiou等人最早将Harr小波用于人脸特征表示,Viola和Jones则在此基础上,提出了多种形式的Haar特征。Lienhart等人对Haar矩形特征做了进一步的扩展,加入了旋转45∘45∘的矩形特征,因此现有的Haar特征模板主要如下图所示:
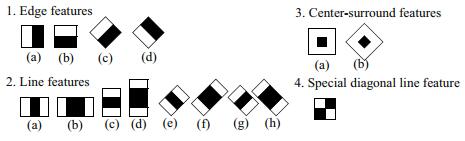
看着上面这一大堆黑白块,我想应该不难理解矩形特征这个词——黑白两部分嘛。规则不是特征,但按某个规则可以找到特征的话,当我们有了很多很多很多规则之后……这就是Haar特征的思想,每一个小黑白块就是一种规则,也是一种特征,也是一个分类器。不过单独一个这样的分类器当真不敢恭维,试想有啥分类能只靠一劈两半看左右这种粗暴直接的方式区分的...所以,他们都是弱分类器,他们能做得不多,就像战场上的士兵不计其数,组合在一起却会有意想不到的变化
在计算Haar特征值时,用白色区域像素值的和减去黑色区域像素值的和,也就是说白色区域的权值为正值,黑色区域的权值为负值,而且权值与矩形区域的面积成反比,抵消两种矩形区域面积不等造成的影响,保证Haar特征值在灰度分布均匀的区域特征值趋近于0。Haar特征在一定程度上反应了图像灰度的局部变化,在人脸检测中,脸部的一些特征可由矩形特征简单刻画,例如,眼睛比周围区域的颜色要深,鼻梁比两侧颜色要浅等。
Haar-like矩形特征分为多类,特征模板可用于图像中的任一位置,而且大小也可任意变化,因此Haar特征的取值受到特征模板的类别、位置以及大小这三种因素的影响,使得在一固定大小的图像窗口内,可以提取出大量的Haar特征。例如,在一个24×24的检测窗口内,矩形特征的数量可以达到16万个。这样就需要解决两个重要问题,快速计算Haar矩形特征值——积分图;筛选有效的矩形特征用于分类识别——AdaBoost分类器。
为了解决大量计算的问题引入了积分图像(intergal images)的概念。它大大简化了像素和的计算,大约只需要像素数目数量级的运算,每次运算只涉及到4个像素。这让一切都变得超级快。
在我们计算的所有特征中,大部分特征是无关紧要的。比如下图这个例子。 顶上一行表示两个不错的特征,第一个特征似乎是根据眼睛所在位置通常比脸颊和鼻子更黑来选择,而第二个特征选择的依据则是眼睛比鼻梁要黑。因此,相同的窗口用于脸颊或者其他部位时就没有意义了。那么我们如何从超过16万个的特征中选择最好的特征呢?我们可以使用Adaboost来实现。

AdaBoost分类器+Cascade 分类器
由输入图像得到积分图,通过取不同种类、大小的Haar特征模板,并在不同位置处,利用积分图提取Haar矩形特征,可快速得到大量Haar特征值,AdaBoost分类器可用于对提取的Haar特征(通常需要做归一化处理)进行训练分类,并应用于人脸检测中。AdaBoost是一种集成分类器,由若干个弱分类器(例如决策树)组合训练得到。
在训练多个弱分类器得到强分类器的过程中,采用了两次加权的处理方法,一是对样本图片进行加权,在迭代过程中,提高错分样本的权重;二是对筛选出的弱分类器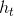 进行加权,弱分类器准确率越高,权重越大。
进行加权,弱分类器准确率越高,权重越大。
此外,还需进一步对强分类器进行级联,以提高检测正确率并降低误识率。级联分类器如下所示:
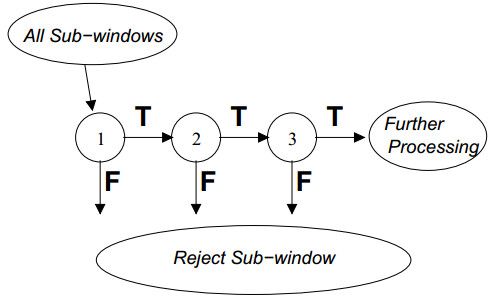
首先将所有待检测的子窗口输入到第一个分类器中,如果某个子窗口判决通过,则进入下一个分类器继续检测识别,否则该子窗口直接退出检测流程,也就是说后续分类器不需要处理该子窗口。通过这样一种级联的方式可以去除一些误识为目标的子窗口,降低误识率。例如,单个强分类器,99%的目标窗口可以通过,同时50%的非目标窗口也能通过,假设有20个强分类器级联,那么最终的正确检测率为0.9920=98%0.9920=98%,而错误识别率为0.5020≈0.0001%0.5020≈0.0001%,在不影响检测准确率的同时,大大降低了误识率。当然前提是单个强分类器的准确率非常高,这样级联多个分类器才能不影响最终的准确率或者影响很小。
在一幅图像中,为了能够检测到不同位置的目标区域,需要以一定步长遍历整幅图像;而对于不同大小的目标,则需要改变检测窗口的尺寸,或者固定窗口而缩放图像。这样,最后检测到的子窗口必然存在相互重叠的情况,因此需要进一步对这些重叠的子窗口进行合并,也就是非极大值抑制(NMS,non-maximum suppression),同时剔除零散分布的错误检测窗口。
from:https://blog.csdn.net/Zachary_Co/article/details/78811605
我们将每个特征都应用于所有训练集图片中,对于每个特征,找出人脸图片分类效果最好的阈值。显然,分类会有误分类,我们选择分类错误率最小的那些特征,也就是说这些特征可以最好的将人脸图片和非人脸图片区分开。(实际上没有那么简单,每个图片初始时给定相同的权重。每次分类后,提升被分类错误图片的权重。然后再根据新的权重分类,计算出新的错误率和新的权重,直到错误率或迭代次数达到要求即停止(实际上就是Adaboost的流程))。
最终的分类器是这些弱分类器的加权和。之所以称之为弱分类器是因为每个分类器不能单独分类图片,但是将他们聚集起来就形成了强分类器。论文表明,只需要200个特征的分类器在检测中的精确度达到了95%。最终的分类器大约有6000个特征。(将超过160000个特征减小到6000个,这是非常大的进步了)
假设现在你有一张图片,使用24x24的滑动窗口,将6000个特征应用于图片来检测图片是否为人脸。嗯….这是不是有点效率低下,浪费时间?确实是的,不过作者自有妙计。
事实上,一张图片中大部分的区域都不是人脸。如果能找到一个简单的方法能够检测某个窗口是不是人脸区域,如果该窗口不是人脸区域,那么就只看一眼便直接跳过,也就不用进行后续处理了,这样就能集中精力判别那些可能是人脸的区域。为此引入了Cascade 分类器。它不是将6000个特征都用在一个窗口,而是将特征分为不同的阶段,然后一个阶段一个阶段的应用这些特征(通常情况下,前几个阶段只有很少量的特征)。如果窗口在第一个阶段就检测失败了,那么就直接舍弃它,无需考虑剩下的特征。如果检测通过,则考虑第二阶段的特征并继续处理。如果所有阶段的都通过了,那么这个窗口就是人脸区域。
作者的检测器将6000+的特征分为了38个阶段,前五个阶段分别有1,10,25,25,50个特征(前文图中提到的两个特征实际上是Adaboost中得到的最好的两个特征)。根据作者所述,平均每个子窗口只需要使用6000+个特征中的10个左右。
以上就是Viola-Jones 人脸识别的工作原理,简述此技术不限于人脸检测,还可用于其他物体的检测,如汽车、飞机等的正面、侧面、后面检测。在检测时,先导入训练好的参数文件,其中haarcascade_frontalface_alt2.xml对正面脸的识别效果较好,haarcascade_profileface.xml对侧脸的检测效果较好。当然,如果要达到更高的分类精度,可以收集更多的数据进行训练。
3、自己训练
在opencv的安装目录中的bin文件夹下有两个可执行文件opencv_createsamples.exe和opencv_traincascade.exe。traincascade快速使用详解:https://blog.csdn.net/guduruyu/article/details/70183372
如果对分类器的参数不满意,或者说想识别其他的物体例如车、人、飞机、苹果等等等等,只需要选择适当的样本训练,获取该物体的各个方面的参数,完整的细节在:https://docs.opencv.org/2.4/doc/user_guide/ug_traincascade.html
训练过程可以通过openCV的haartraining实现(参考haartraining参考文档opencv/apps/traincascade ),主要包括个步骤:
1. 收集打算学习的物体数据集(如正面人脸图,侧面汽车图等, 1000~10000个正样本为宜),把它们存储在一个或多个目录下面。
2. 使用createsamples来建立正样本的向量输出文件,通过这个文件可以重复训练过程,使用同一个向量输出文件尝试各种参数。
3. 获取负样本,即不包含该物体的图像。
4. 训练。