Spark学习之路(一)【概述、环境搭建、基本操作】
Spark
一、概述
http://spark.apache.org/
Apache Spark™ is a unified(统一) analytics engine for large-scale data processing.
特点
- 高效:Run workloads 100x faster.
- 易用:Write applications quickly in Java, Scala, Python, R, and SQL
- 通用:Combine SQL, streaming, and complex analytics
- 兼容:Spark runs on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud. It can access diverse data sources.
二、环境搭建
注: Spark支持4中集群类型,分别为Standalone、Apache Mesos 、Hadoop YARN 、Kubernetes
以下环境搭建为:Standalone 集群
环境要求
- Linux/Mac OS操作系统
- JDK
- Scala
- Hadoop HDFS环境(版本需要匹配Spark)
下载
https://spark.apache.org/downloads.html
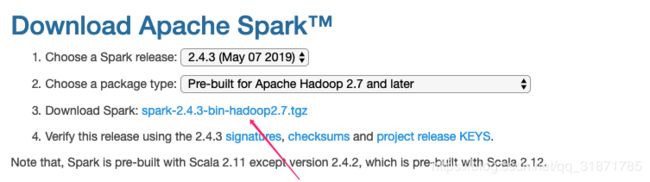
安装
gaozhy@gaozhydeMacBook-Pro ~ tar -zxvf Downloads/spark-2.4.3-bin-hadoop2.7.tgz -C software/
配置
gaozhy@gaozhydeMacBook-Pro ~ cd software/spark-2.4.3-bin-hadoop2.7
gaozhy@gaozhydeMacBook-Pro ~ cp conf/spark-env.sh.template conf/spark-env.sh
gaozhy@gaozhydeMacBook-Pro ~ vim conf/spark-env.sh
# 在配置文件中添加如下配置
export SPARK_MASTER_HOST=spark
export SPARK_MASTER_PORT=7077
gaozhy@gaozhydeMacBook-Pro ~/software/spark-2.4.3-bin-hadoop2.7 cp conf/slaves.template conf/slaves
gaozhy@gaozhydeMacBook-Pro ~/software/spark-2.4.3-bin-hadoop2.7 vim conf/slaves
# 将配置文件中localhost修改为spark
spark
gaozhy@gaozhydeMacBook-Pro ~/software/spark-2.4.3-bin-hadoop2.7 sudo vim /etc/hosts
# 在配置文件末尾添加
127.0.0.1 spark
gaozhy@gaozhydeMacBook-Pro ~/software/spark-2.4.3-bin-hadoop2.7 sudo vim /etc/profile
# 添加spark环境变量信息
export SCALA_HOME=/Users/gaozhy/software/scala-2.11.8
export SPARK_HOME=/Users/gaozhy/software/spark-2.4.3-bin-hadoop2.7
export PATH=$PATH:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin
gaozhy@gaozhydeMacBook-Pro ~/software/spark-2.4.3-bin-hadoop2.7 source /etc/profile
运行Spark服务
gaozhy@gaozhydeMacBook-Pro ~/software/spark-2.4.3-bin-hadoop2.7 start-all.sh
注:关闭服务可使用指令
stop-all.sh

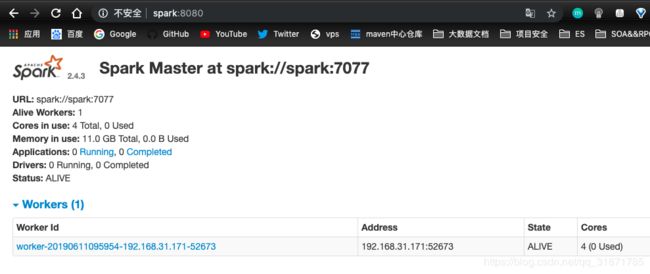
Spark Web UI
访问地址:http://spark:8080
三、快速开始
通过Spark Shell进行交互式分析
运行spark shell
gaozhy@gaozhydeMacBook-Pro ~ spark-shell

基本操作
准备数据文件/Users/gaozhy/test.json
{"id":1,"name":"zs","sex":"男"}
{"id":2,"name":"ls","sex":"女"}
{"id":3,"name":"ww","sex":"男"}
spark-shell操作
scala> val dataset = spark.read.json("/Users/gaozhy/test.json")
dataset: org.apache.spark.sql.DataFrame = [id: bigint, name: string ... 1 more field]
注:
DataSet是Spark抽象出来的一个弹性分布式数据集
DataSet处理
# 数据记录数
scala> dataset.count()
res0: Long = 3
# 获取数据集第一条数据
scala> dataset.first
res1: org.apache.spark.sql.Row = [1,zs,男]
# 性别为男性的记录个数
scala> dataset.filter(row => row(2).equals("男")).count()
res4: Long = 2
# 计算男性和女性用户人数
scala> dataset.rdd.map(row => (row(2),1)).reduceByKey(_+_).saveAsTextFile("/Users/gaozhy/result2")
-----------------------------------------
(男,2)
(女,1)
通过Spark API分析
创建Maven项目并导入开发依赖
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>2.4.3version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>2.4.3version>
dependency>
dependencies>
测试代码
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
object SimpleApp2 {
def main(args: Array[String]): Unit = {
// 任务提交到spark集群
val sparkConf = new SparkConf().setMaster("spark://spark:7077").setAppName("simple app").setJars(Array("/Users/gaozhy/workspace/20180429/spark01/target/spark01-1.0-SNAPSHOT.jar"))
// 本地模拟
// val sparkConf = new SparkConf().setMaster("local[*]").setAppName("simple app")
val sparkContext = new SparkContext(sparkConf)
val spark = SparkSession.builder.getOrCreate
val dataset = spark.read.json("/Users/gaozhy/test.json")
dataset.rdd.map(row => (row(2),1)).reduceByKey(_+_).saveAsTextFile("/Users/gaozhy/result2")
spark.stop()
}
}
运行结果
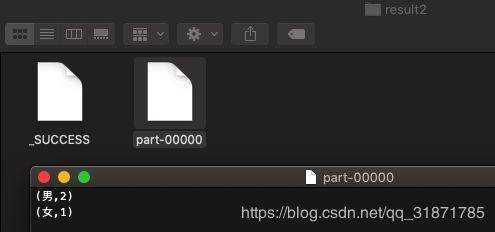
通过提交Jar包分析
将spark应用打成jar包

使用spark-submit提交任务
gaozhy@gaozhydeMacBook-Pro ~ spark-submit --class "SimpleApp2" --master spark://spar:7077 /Users/gaozhy/workspace/20180429/spark01/target/spark01-1.0-SNAPSHOT.jar
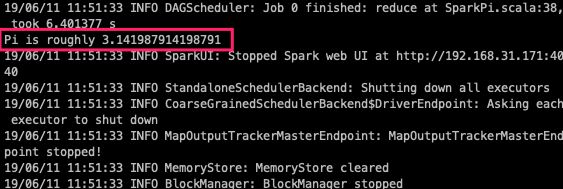
官方提供的例子(计算圆周率)
提交任务
gaozhy@gaozhydeMacBook-Pro ~/software/spark-2.4.3-bin-hadoop2.7 bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://spark:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.11-2.4.3.jar \
100
计算结果