90个前端开发面试必问基础大总结
大家好,我是练习时长一年半的前端练习生,喜欢唱、跳、rap、敲代码。转眼又到了金三银四的时节,相信很多小伙伴已经在为自己心仪的公司做准备,本文是笔者一年多来对前端基础知识的总结和思考,这些题目对自己是总结,对大家也是一点微薄的资料,希望能给大家带来一些帮助和启发。成文过程中得到了许多大佬的帮助,在此感谢恺哥的小册[1]、神三元同学的前端每日一问[2]以及许多素未谋面的朋友们,让我等萌新也有机会在前人的财富中拾人牙慧,班门弄斧Thanks♪(・ω・)ノ
本文将从以下十一个维度为读者总结前端基础知识

行文不易,卑微求个赞(`∀´)Ψ
JS基础
1. 如何在ES5环境下实现let
对于这个问题,我们可以直接查看
babel转换前后的结果,看一下在循环中通过let定义的变量是如何解决变量提升的问题
 babel在let定义的变量前加了道下划线,避免在块级作用域外访问到该变量,除了对变量名的转换,我们也可以通过自执行函数来模拟块级作用域
babel在let定义的变量前加了道下划线,避免在块级作用域外访问到该变量,除了对变量名的转换,我们也可以通过自执行函数来模拟块级作用域
(function(){for(var i = 0; i < 5; i ++){console.log(i) // 0 1 2 3 4}})();console.log(i) // Uncaught ReferenceError: i is not defined
2. 如何在ES5环境下实现const
实现const的关键在于Object.defineProperty()这个API,这个API用于在一个对象上增加或修改属性。通过配置属性描述符,可以精确地控制属性行为。Object.defineProperty() 接收三个参数:
Object.defineProperty(obj, prop, desc)
| 参数 | 说明 |
| obj | 要在其上定义属性的对象 |
| prop | 要定义或修改的属性的名称 |
| descriptor | 将被定义或修改的属性描述符 |
| 属性描述符 | 说明 | 默认值 |
| value | 该属性对应的值。可以是任何有效的 JavaScript 值(数值,对象,函数等)。默认为 undefined | undefined |
| get | 一个给属性提供 getter 的方法,如果没有 getter 则为 undefined | undefined |
| set | 一个给属性提供 setter 的方法,如果没有 setter 则为 undefined。当属性值修改时,触发执行该方法 | undefined |
| writable | 当且仅当该属性的writable为true时,value才能被赋值运算符改变。默认为 false | false |
| enumerable | enumerable定义了对象的属性是否可以在 for...in 循环和 Object.keys() 中被枚举 | false |
| Configurable | configurable特性表示对象的属性是否可以被删除,以及除value和writable特性外的其他特性是否可以被修改 | false |
对于const不可修改的特性,我们通过设置writable属性来实现
function _const(key, value) {const desc = {value,writable: false}Object.defineProperty(window, key, desc)}_const('obj', {a: 1}) //定义objobj.b = 2 //可以正常给obj的属性赋值obj = {} //抛出错误,提示对象read-only
参考资料:如何在 ES5 环境下实现一个const ?[3]
3. 手写call()
call() 方法使用一个指定的 this 值和单独给出的一个或多个参数来调用一个函数
语法:function.call(thisArg, arg1, arg2, ...)
call()的原理比较简单,由于函数的this指向它的直接调用者,我们变更调用者即完成this指向的变更:
//变更函数调用者示例function foo() {console.log(this.name)}// 测试const obj = {name: '写代码像蔡徐抻'}obj.foo = foo // 变更foo的调用者obj.foo() // '写代码像蔡徐抻'
基于以上原理, 我们两句代码就能实现call()
Function.prototype.myCall = function(thisArg, ...args) {thisArg.fn = this // this指向调用call的对象,即我们要改变this指向的函数return thisArg.fn(...args) // 执行函数并return其执行结果}
但是我们有一些细节需要处理:
Function.prototype.myCall = function(thisArg, ...args) {if(typeof this !== 'function') {throw new TypeError('error')}const fn = Symbol('fn') // 声明一个独有的Symbol属性, 防止fn覆盖已有属性thisArg = thisArg || window // 若没有传入this, 默认绑定window对象thisArg[fn] = this // this指向调用call的对象,即我们要改变this指向的函数const result = thisArg[fn](...args) // 执行当前函数delete thisArg[fn] // 删除我们声明的fn属性return result // 返回函数执行结果}//测试foo.myCall(obj) // 输出'写代码像蔡徐抻'
4. 手写apply()
apply() 方法调用一个具有给定this值的函数,以及作为一个数组(或类似数组对象)提供的参数。
语法:func.apply(thisArg, [argsArray])
apply()和call()类似,区别在于call()接收参数列表,而apply()接收一个参数数组,所以我们在call()的实现上简单改一下入参形式即可
Function.prototype.myApply = function(thisArg, args) {if(typeof this !== 'function') {throw new TypeError('error')}const fn = Symbol('fn') // 声明一个独有的Symbol属性, 防止fn覆盖已有属性thisArg = thisArg || window // 若没有传入this, 默认绑定window对象thisArg[fn] = this // this指向调用call的对象,即我们要改变this指向的函数const result = thisArg[fn](...args) // 执行当前函数delete thisArg[fn] // 删除我们声明的fn属性return result // 返回函数执行结果}//测试foo.myApply(obj, []) // 输出'写代码像蔡徐抻'
5. 手写bind()
bind()方法创建一个新的函数,在 bind() 被调用时,这个新函数的 this 被指定为 bind() 的第一个参数,而其余参数将作为新函数的参数,供调用时使用。
语法: function.bind(thisArg, arg1, arg2, ...)
从用法上看,似乎给call/apply包一层function就实现了bind():
Function.prototype.myBind = function(thisArg, ...args) {return () => {this.apply(thisArg, args)}}
但我们忽略了三点:
1.bind()除了this还接收其他参数,bind()返回的函数也接收参数,这两部分的参数都要传给返回的函数2.new的优先级:如果bind绑定后的函数被new了,那么此时this指向就发生改变。此时的this就是当前函数的实例3.没有保留原函数在原型链上的属性和方法
Function.prototype.myBind = function (thisArg, ...args) {if (typeof this !== "function") {throw TypeError("Bind must be called on a function")}var self = this// new优先级var fbound = function () {self.apply(this instanceof self ? this : thisArg, args.concat(Array.prototype.slice.call(arguments)))}// 继承原型上的属性和方法fbound.prototype = Object.create(self.prototype);return fbound;}//测试const obj = { name: '写代码像蔡徐抻' }function foo() {console.log(this.name)console.log(arguments)}foo.myBind(obj, 'a', 'b', 'c')() //输出写代码像蔡徐抻 ['a', 'b', 'c']
6. 手写一个防抖函数
防抖和节流的概念都比较简单,所以我们就不在“防抖节流是什么”这个问题上浪费过多篇幅了,简单点一下:
防抖,即
短时间内大量触发同一事件,只会执行一次函数,实现原理为设置一个定时器,约定在xx毫秒后再触发事件处理,每次触发事件都会重新设置计时器,直到xx毫秒内无第二次操作,防抖常用于搜索框/滚动条的监听事件处理,如果不做防抖,每输入一个字/滚动屏幕,都会触发事件处理,造成性能浪费。
function debounce(func, wait) {let timeout = nullreturn function() {let context = thislet args = argumentsif (timeout) clearTimeout(timeout)timeout = setTimeout(() => {func.apply(context, args)}, wait)}}
7. 手写一个节流函数
防抖是
延迟执行,而节流是间隔执行,函数节流即每隔一段时间就执行一次,实现原理为设置一个定时器,约定xx毫秒后执行事件,如果时间到了,那么执行函数并重置定时器,和防抖的区别在于,防抖每次触发事件都重置定时器,而节流在定时器到时间后再清空定时器
function throttle(func, wait) {let timeout = nullreturn function() {let context = thislet args = argumentsif (!timeout) {timeout = setTimeout(() => {timeout = nullfunc.apply(context, args)}, wait)}
}}
>实现方式2:使用两个时间戳`prev旧时间戳`和`now新时间戳`,每次触发事件都判断二者的时间差,如果到达规定时间,执行函数并重置旧时间戳```jsfunction throttle(func, wait) {var prev = 0;return function() {let now = Date.now();let context = this;let args = arguments;if (now - prev > wait) {func.apply(context, args);prev = now;}}}
8. 数组扁平化
对于
[1, [1,2], [1,2,3]]这样多层嵌套的数组,我们如何将其扁平化为[1, 1, 2, 1, 2, 3]这样的一维数组呢:
1.ES6的flat()
const arr = [1, [1,2], [1,2,3]]arr.flat(Infinity) // [1, 1, 2, 1, 2, 3]
2.序列化后正则
const arr = [1, [1,2], [1,2,3]]const str = `[${JSON.stringify(arr).replace(/(\[|\])/g, '')}]`JSON.parse(str) // [1, 1, 2, 1, 2, 3]
3.递归
对于树状结构的数据,最直接的处理方式就是递归
const arr = [1, [1,2], [1,2,3]]function flat(arr) {let result = []for (const item of arr) {item instanceof Array ? result = result.concat(flat(item)) : result.push(item)}return result}flat(arr) // [1, 1, 2, 1, 2, 3]
4.reduce()递归
const arr = [1, [1,2], [1,2,3]]function flat(arr) {return arr.reduce((prev, cur) => {return prev.concat(cur instanceof Array ? flat(cur) : cur)}, [])}flat(arr) // [1, 1, 2, 1, 2, 3]
5.迭代+展开运算符
let arr = [1, [1,2], [1,2,3]]while (arr.some(Array.isArray)) {arr = [].concat(...arr);}console.log(arr) // [1, 1, 2, 1, 2, 3]
9. 手写一个Promise
实现一个符合规范的Promise篇幅比较长,建议阅读笔者上一篇文章:异步编程二三事 | Promise/async/Generator实现原理解析 | 9k字[4]
JS面向对象
在JS中一切皆对象,但JS并不是一种真正的面向对象(OOP)的语言,因为它缺少类(class)的概念。虽然ES6引入了class和extends,使我们能够轻易地实现类和继承。但JS并不存在真实的类,JS的类是通过函数以及原型链机制模拟的,本小节的就来探究如何在ES5环境下利用函数和原型链实现JS面向对象的特性
在开始之前,我们先回顾一下原型链的知识,后续new和继承等实现都是基于原型链机制。很多介绍原型链的资料都能写上洋洋洒洒几千字,但我觉得读者们不需要把原型链想太复杂,容易把自己绕进去,其实在我看来,原型链的核心只需要记住三点:
1.每个对象都有__proto__属性,该属性指向其原型对象,在调用实例的方法和属性时,如果在实例对象上找不到,就会往原型对象上找2.构造函数的prototype属性也指向实例的原型对象3.原型对象的constructor属性指向构造函数
![]()
1. 模拟实现new
首先我们要知道new做了什么
1.创建一个新对象,并继承其构造函数的prototype,这一步是为了继承构造函数原型上的属性和方法2.执行构造函数,方法内的this被指定为该新实例,这一步是为了执行构造函数内的赋值操作3.返回新实例(规范规定,如果构造方法返回了一个对象,那么返回该对象,否则返回第一步创建的新对象)
// new是关键字,这里我们用函数来模拟,new Foo(args) <=> myNew(Foo, args)function myNew(foo, ...args) {// 创建新对象,并继承构造方法的prototype属性, 这一步是为了把obj挂原型链上, 相当于obj.__proto__ = Foo.prototypelet obj = Object.create(foo.prototype)// 执行构造方法, 并为其绑定新this, 这一步是为了让构造方法能进行this.name = name之类的操作, args是构造方法的入参, 因为这里用myNew模拟, 所以入参从myNew传入let result = foo.apply(obj, args)// 如果构造方法已经return了一个对象, 那么就返回该对象, 一般情况下,构造方法不会返回新实例,但使用者可以选择返回新实例来覆盖new创建的对象 否则返回myNew创建的新对象return typeof result === 'object' && result !== null ? result : obj}function Foo(name) {this.name = name}const newObj = myNew(Foo, 'zhangsan')console.log(newObj) // Foo {name: "zhangsan"}console.log(newObj instanceof Foo) // true
2. ES5如何实现继承
说到继承,最容易想到的是ES6的extends,当然如果只回答这个肯定不合格,我们要从函数和原型链的角度上实现继承,下面我们一步步地、递进地实现一个合格的继承
一. 原型链继承
原型链继承的原理很简单,直接让子类的原型对象指向父类实例,当子类实例找不到对应的属性和方法时,就会往它的原型对象,也就是父类实例上找,从而实现对父类的属性和方法的继承
// 父类function Parent() {this.name = '写代码像蔡徐抻'}// 父类的原型方法Parent.prototype.getName = function() {return this.name}// 子类function Child() {}// 让子类的原型对象指向父类实例, 这样一来在Child实例中找不到的属性和方法就会到原型对象(父类实例)上寻找Child.prototype = new Parent()Child.prototype.constructor = Child // 根据原型链的规则,顺便绑定一下constructor, 这一步不影响继承, 只是在用到constructor时会需要// 然后Child实例就能访问到父类及其原型上的name属性和getName()方法const child = new Child()child.name // '写代码像蔡徐抻'child.getName() // '写代码像蔡徐抻'
原型继承的缺点:
1.由于所有Child实例原型都指向同一个Parent实例, 因此对某个Child实例的父类引用类型变量修改会影响所有的Child实例2.在创建子类实例时无法向父类构造传参, 即没有实现
super()的功能
// 示例:function Parent() {this.name = ['写代码像蔡徐抻']}Parent.prototype.getName = function() {return this.name}function Child() {}
Child.prototype = new Parent() Child.prototype.constructor = Child
// 测试 const child1 = new Child() const child2 = new Child() child1.name[0] = 'foo' console.log(child1.name) // ['foo'] console.log(child2.name) // ['foo'] (预期是['写代码像蔡徐抻'], 对child1.name的修改引起了所有child实例的变化)
### 二. 构造函数继承构造函数继承,即在子类的构造函数中执行父类的构造函数,并为其绑定子类的`this`,让父类的构造函数把成员属性和方法都挂到`子类的this`上去,这样既能避免实例之间共享一个原型实例,又能向父类构造方法传参```jsfunction Parent(name) {this.name = [name]}Parent.prototype.getName = function() {return this.name}function Child() {Parent.call(this, 'zhangsan') // 执行父类构造方法并绑定子类的this, 使得父类中的属性能够赋到子类的this上}//测试const child1 = new Child()const child2 = new Child()child1.name[0] = 'foo'console.log(child1.name) // ['foo']console.log(child2.name) // ['zhangsan']child2.getName() // 报错,找不到getName(), 构造函数继承的方式继承不到父类原型上的属性和方法
构造函数继承的缺点:
1.继承不到父类原型上的属性和方法
三. 组合式继承
既然原型链继承和构造函数继承各有互补的优缺点, 那么我们为什么不组合起来使用呢, 所以就有了综合二者的组合式继承
function Parent(name) {this.name = [name]}Parent.prototype.getName = function() {return this.name}function Child() {// 构造函数继承Parent.call(this, 'zhangsan')}//原型链继承Child.prototype = new Parent()Child.prototype.constructor = Child//测试const child1 = new Child()const child2 = new Child()child1.name[0] = 'foo'console.log(child1.name) // ['foo']console.log(child2.name) // ['zhangsan']child2.getName() // ['zhangsan']
组合式继承的缺点:
1.每次创建子类实例都执行了两次构造函数(
Parent.call()和new Parent()),虽然这并不影响对父类的继承,但子类创建实例时,原型中会存在两份相同的属性和方法,这并不优雅
四. 寄生式组合继承
为了解决构造函数被执行两次的问题, 我们将指向父类实例改为指向父类原型, 减去一次构造函数的执行
function Parent(name) {this.name = [name]}Parent.prototype.getName = function() {return this.name}function Child() {// 构造函数继承Parent.call(this, 'zhangsan')}//原型链继承// Child.prototype = new Parent()Child.prototype = Parent.prototype //将`指向父类实例`改为`指向父类原型`Child.prototype.constructor = Child//测试const child1 = new Child()const child2 = new Child()child1.name[0] = 'foo'console.log(child1.name) // ['foo']console.log(child2.name) // ['zhangsan']child2.getName() // ['zhangsan']
但这种方式存在一个问题,由于子类原型和父类原型指向同一个对象,我们对子类原型的操作会影响到父类原型,例如给Child.prototype增加一个getName()方法,那么会导致Parent.prototype也增加或被覆盖一个getName()方法,为了解决这个问题,我们给Parent.prototype做一个浅拷贝
function Parent(name) {this.name = [name]}Parent.prototype.getName = function() {return this.name}function Child() {// 构造函数继承Parent.call(this, 'zhangsan')}//原型链继承// Child.prototype = new Parent()Child.prototype = Object.create(Parent.prototype) //将`指向父类实例`改为`指向父类原型`Child.prototype.constructor = Child//测试const child = new Child()const parent = new Parent()child.getName() // ['zhangsan']parent.getName() // 报错, 找不到getName()
到这里我们就完成了ES5环境下的继承的实现,这种继承方式称为寄生组合式继承,是目前最成熟的继承方式,babel对ES6继承的转化也是使用了寄生组合式继承
我们回顾一下实现过程:
一开始最容易想到的是原型链继承,通过把子类实例的原型指向父类实例来继承父类的属性和方法,但原型链继承的缺陷在于对子类实例继承的引用类型的修改会影响到所有的实例对象以及无法向父类的构造方法传参。
因此我们引入了构造函数继承, 通过在子类构造函数中调用父类构造函数并传入子类this来获取父类的属性和方法,但构造函数继承也存在缺陷,构造函数继承不能继承到父类原型链上的属性和方法。
所以我们综合了两种继承的优点,提出了组合式继承,但组合式继承也引入了新的问题,它每次创建子类实例都执行了两次父类构造方法,我们通过将子类原型指向父类实例改为子类原型指向父类原型的浅拷贝来解决这一问题,也就是最终实现 —— 寄生组合式继承
![]()
V8引擎机制
1. V8如何执行一段JS代码
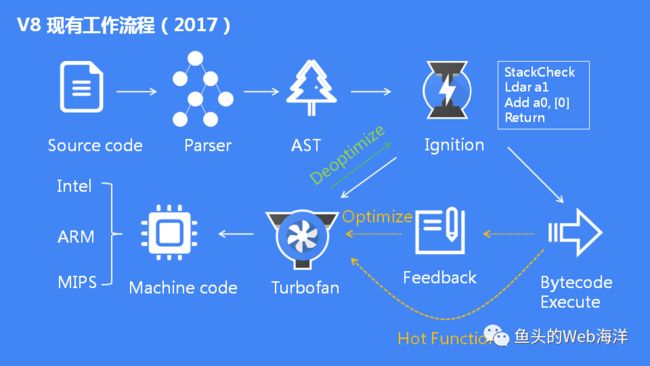
1.预解析:检查语法错误但不生成AST2.生成AST:经过词法/语法分析,生成抽象语法树3.生成字节码:基线编译器(Ignition)将AST转换成字节码4.生成机器码:优化编译器(Turbofan)将字节码转换成优化过的机器码,此外在逐行执行字节码的过程中,如果一段代码经常被执行,那么V8会将这段代码直接转换成机器码保存起来,下一次执行就不必经过字节码,优化了执行速度
上面几点只是V8执行机制的极简总结,建议阅读参考资料:
1.V8 是怎么跑起来的 —— V8 的 JavaScript 执行管道[5]
2.JavaScript 引擎 V8 执行流程概述[6]
2. 介绍一下引用计数和标记清除
•引用计数:给一个变量赋值引用类型,则该对象的引用次数+1,如果这个变量变成了其他值,那么该对象的引用次数-1,垃圾回收器会回收引用次数为0的对象。但是当对象循环引用时,会导致引用次数永远无法归零,造成内存无法释放。•标记清除:垃圾收集器先给内存中所有对象加上标记,然后从根节点开始遍历,去掉被引用的对象和运行环境中对象的标记,剩下的被标记的对象就是无法访问的等待回收的对象。
3. V8如何进行垃圾回收
JS引擎中对变量的存储主要有两种位置,栈内存和堆内存,栈内存存储基本类型数据以及引用类型数据的内存地址,堆内存储存引用类型的数据
![]()
栈内存的回收:
栈内存调用栈上下文切换后就被回收,比较简单
堆内存的回收:
V8的堆内存分为新生代内存和老生代内存,新生代内存是临时分配的内存,存在时间短,老生代内存存在时间长
![]()
•新生代内存回收机制:
•新生代内存容量小,64位系统下仅有32M。新生代内存分为From、To两部分,进行垃圾回收时,先扫描From,将非存活对象回收,将存活对象顺序复制到To中,之后调换From/To,等待下一次回收
•老生代内存回收机制
•晋升:如果新生代的变量经过多次回收依然存在,那么就会被放入老生代内存中•标记清除:老生代内存会先遍历所有对象并打上标记,然后对正在使用或被强引用的对象取消标记,回收被标记的对象•整理内存碎片:把对象挪到内存的一端
参考资料:聊聊V8引擎的垃圾回收[7]
4. JS相较于C++等语言为什么慢,V8做了哪些优化
1.JS的问题:
•动态类型:导致每次存取属性/寻求方法时候,都需要先检查类型;此外动态类型也很难在编译阶段进行优化•属性存取:C++/Java等语言中方法、属性是存储在数组中的,仅需数组位移就可以获取,而JS存储在对象中,每次获取都要进行哈希查询
2.V8的优化:
•优化JIT(即时编译):相较于C++/Java这类编译型语言,JS一边解释一边执行,效率低。V8对这个过程进行了优化:如果一段代码被执行多次,那么V8会把这段代码转化为机器码缓存下来,下次运行时直接使用机器码。•隐藏类:对于C++这类语言来说,仅需几个指令就能通过偏移量获取变量信息,而JS需要进行字符串匹配,效率低,V8借用了类和偏移位置的思想,将对象划分成不同的组,即隐藏类•内嵌缓存:即缓存对象查询的结果。常规查询过程是:获取隐藏类地址 -> 根据属性名查找偏移值 -> 计算该属性地址,内嵌缓存就是对这一过程结果的缓存•垃圾回收管理:上文已介绍

参考资料:为什么V8引擎这么快?[8]
浏览器渲染机制
1. 浏览器的渲染过程是怎样的
 大体流程如下:
大体流程如下:
1.HTML和CSS经过各自解析,生成DOM树和CSSOM树2.合并成为渲染树3.根据渲染树进行布局4.最后调用GPU进行绘制,显示在屏幕上
2. 如何根据浏览器渲染机制加快首屏速度
1.优化文件大小:HTML和CSS的加载和解析都会阻塞渲染树的生成,从而影响首屏展示速度,因此我们可以通过优化文件大小、减少CSS文件层级的方法来加快首屏速度2.避免资源下载阻塞文档解析:浏览器解析到
5. meta有哪些属性,作用是什么
meta标签用于描述网页的元信息,如网站作者、描述、关键词,meta通过name=xxx和content=xxx的形式来定义信息,常用设置如下:
•charset:定义HTML文档的字符集
•http-equiv:可用于模拟http请求头,可设置过期时间、缓存、刷新
<meta http-equiv="expires" content="Wed, 20 Jun 2019 22:33:00 GMT">•viewport:视口,用于控制页面宽高及缩放比例
name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1">6. viewport有哪些参数,作用是什么
•width/height,宽高,默认宽度980px•initial-scale,初始缩放比例,1~10•maximum-scale/minimum-scale,允许用户缩放的最大/小比例•user-scalable,用户是否可以缩放 (yes/no)
7. http-equive属性的作用和参数
•expires,指定过期时间•progma,设置no-cache可以禁止缓存•refresh,定时刷新•set-cookie,可以设置cookie•X-UA-Compatible,使用浏览器版本•apple-mobile-web-app-status-bar-style,针对WebApp全屏模式,隐藏状态栏/设置状态栏颜色

CSS相关
清除浮动的方法
为什么要清除浮动:清除浮动是为了解决子元素浮动而导致父元素高度塌陷的问题
![]() 1.添加新元素
1.添加新元素
2.使用伪元素
/* 对父元素添加伪元素 */.parent::after{content: "";display: block;height: 0;clear:both;}
3.触发父元素BFC
/* 触发父元素BFC */.parent {overflow: hidden;/* float: left; *//* position: absolute; *//* display: inline-block *//* 以上属性均可触发BFC */}
常见布局
编辑中,请稍等-_-||
什么是BFC
BFC全称 Block Formatting Context 即块级格式上下文,简单的说,BFC是页面上的一个隔离的独立容器,不受外界干扰或干扰外界
如何触发BFC
•float不为 none•overflow的值不为 visible•position 为 absolute 或 fixed•display的值为 inline-block 或 table-cell 或 table-caption 或 grid
BFC的渲染规则是什么
•BFC是页面上的一个隔离的独立容器,不受外界干扰或干扰外界•计算BFC的高度时,浮动子元素也参与计算(即内部有浮动元素时也不会发生高度塌陷)•BFC的区域不会与float的元素区域重叠•BFC内部的元素会在垂直方向上放置•BFC内部两个相邻元素的margin会发生重叠
BFC的应用场景
•清除浮动:BFC内部的浮动元素会参与高度计算,因此可用于清除浮动,防止高度塌陷•避免某元素被浮动元素覆盖:BFC的区域不会与浮动元素的区域重叠•阻止外边距重叠:属于同一个BFC的两个相邻Box的margin会发生折叠,不同BFC不会发生折叠

总结
对于前端基础知识的讲解,到这里就告一小段落。前端的世界纷繁复杂,远非笔者寥寥几笔所能勾画,笔者就像在沙滩上拾取贝壳的孩童,有时侥幸拾取收集一二,就为之欢欣鼓舞,迫不及待与伙伴们分享。
转自https://mp.weixin.qq.com/s/aywCFgyDhosDvaTBxdh7SA