python数据清洗之学习总结(六、数据清洗之数据预处理)
文章目录
- 1.重复值处理
- 2. 缺失值处理
- 3. 异常值处理
- 4.数据离散化
1.重复值处理
- DataFrame.duplicated 计算是否有重复值
DataFrame.duplicated(self, subset: Union[Hashable,
Sequence[Hashable], NoneType] = None, keep: Union[str, bool] = 'first')
- DataFrame.drop_duplicates 删除重复值
参考《https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.drop_duplicates.html》
DataFrame.drop_duplicates(self, subset: Union[Hashable, Sequence[Hashable], NoneType] = None, keep: Union[str, bool] ='first', inplace: bool = False, ignore_index: bool = False)
以下是我根据视频完整的操作记录,仅稍作整理,以备后续查看。
import pandas as pd
import numpy as np
import os
进入文档所在路径
os.chdir(r'C:\代码和数据')
#路径前不加r的话需要将单斜杠\变为双斜杠\\
读取文档
df =pd.read_csv('MotorcycleData.csv',encoding='gbk',na_values='Na')
#将数据为‘Na’的当作缺失值处理,注意不要写成na_value,应为na_values
查看前三行
df.head(3)
| Condition | Condition_Desc | Price | Location | Model_Year | Mileage | Exterior_Color | Make | Warranty | Model | ... | Vehicle_Title | OBO | Feedback_Perc | Watch_Count | N_Reviews | Seller_Status | Vehicle_Tile | Auction | Buy_Now | Bid_Count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Used | mint!!! very low miles | $11,412 | McHenry, Illinois, United States | 2013.0 | 16,000 | Black | Harley-Davidson | Unspecified | Touring | ... | NaN | FALSE | 8.1 | NaN | 2427 | Private Seller | Clear | True | FALSE | 28.0 |
| 1 | Used | Perfect condition | $17,200 | Fort Recovery, Ohio, United States | 2016.0 | 60 | Black | Harley-Davidson | Vehicle has an existing warranty | Touring | ... | NaN | FALSE | 100 | 17 | 657 | Private Seller | Clear | True | TRUE | 0.0 |
| 2 | Used | NaN | $3,872 | Chicago, Illinois, United States | 1970.0 | 25,763 | Silver/Blue | BMW | Vehicle does NOT have an existing warranty | R-Series | ... | NaN | FALSE | 100 | NaN | 136 | NaN | Clear | True | FALSE | 26.0 |
3 rows × 22 columns
自定义一个函数用于去掉Price和Mileage中的字符,留下数字,并将数值转为浮点型
def f(x):
if '$' in str(x): #去掉Price中的$和,
x = str(x).strip('$')
x = str(x).replace(',','')
else: #去掉Mileage中的,
x = str(x).replace(',','')
return float(x)
对Price和Mileage两个字段用自定义函数f进行处理
df['Price']=df['Price'].apply(f)
df['Mileage']=df['Mileage'].apply(f)
查看处理后的字段数值
df[['Price','Mileage']].head(3)
| Price | Mileage | |
|---|---|---|
| 0 | 11412.0 | 16000.0 |
| 1 | 17200.0 | 60.0 |
| 2 | 3872.0 | 25763.0 |
#查看处理后的字段类型
df[['Price','Mileage']].info()
RangeIndex: 7493 entries, 0 to 7492
Data columns (total 2 columns):
Price 7493 non-null float64
Mileage 7467 non-null float64
dtypes: float64(2)
memory usage: 117.2 KB
df.duplicated()函数,有重复值时该行显示为TRUE否则为FALSE,默认axis=0判断显示
any(df.duplicated())#判断df中是否含有重复值,一旦有的话就是TRUE
True
df[df.duplicated()].head(3) #展示df重复的数据
| Condition | Condition_Desc | Price | Location | Model_Year | Mileage | Exterior_Color | Make | Warranty | Model | ... | Vehicle_Title | OBO | Feedback_Perc | Watch_Count | N_Reviews | Seller_Status | Vehicle_Tile | Auction | Buy_Now | Bid_Count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 57 | Used | NaN | 4050.0 | Gilberts, Illinois, United States | 2006.0 | 6650.0 | Black | Harley-Davidson | Vehicle does NOT have an existing warranty | Softail | ... | NaN | FALSE | NaN | 7< | 58 | Private Seller | Clear | True | TRUE | 3.0 |
| 63 | Used | NaN | 7300.0 | Rolling Meadows, Illinois, United States | 1997.0 | 20000.0 | Black | Harley-Davidson | Vehicle does NOT have an existing warranty | Sportster | ... | NaN | TRUE | 100 | 5< | 111 | Private Seller | Clear | False | TRUE | NaN |
| 64 | Used | Dent and scratch free. Paint and chrome in exc... | 5000.0 | South Bend, Indiana, United States | 2003.0 | 1350.0 | Black | Harley-Davidson | Vehicle does NOT have an existing warranty | Sportster | ... | NaN | FALSE | 100 | 14 | 37 | Private Seller | Clear | False | TRUE | NaN |
3 rows × 22 columns
np.sum(df.duplicated())#计算重复的数量
1221
drop_duplicates()函数,删除重复数据
df.drop_duplicates().head(3)#删除重复的数据,并返回删除后的视图。
# inplace=True 时才会对原数据进行操作
#这是是drop_duplicates不是drop_duplicated
| Condition | Condition_Desc | Price | Location | Model_Year | Mileage | Exterior_Color | Make | Warranty | Model | ... | Vehicle_Title | OBO | Feedback_Perc | Watch_Count | N_Reviews | Seller_Status | Vehicle_Tile | Auction | Buy_Now | Bid_Count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Used | mint!!! very low miles | 11412.0 | McHenry, Illinois, United States | 2013.0 | 16000.0 | Black | Harley-Davidson | Unspecified | Touring | ... | NaN | FALSE | 8.1 | NaN | 2427 | Private Seller | Clear | True | FALSE | 28.0 |
| 1 | Used | Perfect condition | 17200.0 | Fort Recovery, Ohio, United States | 2016.0 | 60.0 | Black | Harley-Davidson | Vehicle has an existing warranty | Touring | ... | NaN | FALSE | 100 | 17 | 657 | Private Seller | Clear | True | TRUE | 0.0 |
| 2 | Used | NaN | 3872.0 | Chicago, Illinois, United States | 1970.0 | 25763.0 | Silver/Blue | BMW | Vehicle does NOT have an existing warranty | R-Series | ... | NaN | FALSE | 100 | NaN | 136 | NaN | Clear | True | FALSE | 26.0 |
3 rows × 22 columns
查看行与列的数量
df.shape
(7493, 22)
查看每一列的名称
df.columns
Index(['Condition', 'Condition_Desc', 'Price', 'Location', 'Model_Year',
'Mileage', 'Exterior_Color', 'Make', 'Warranty', 'Model', 'Sub_Model',
'Type', 'Vehicle_Title', 'OBO', 'Feedback_Perc', 'Watch_Count',
'N_Reviews', 'Seller_Status', 'Vehicle_Tile', 'Auction', 'Buy_Now',
'Bid_Count'],
dtype='object')
删除列’Condition’, ‘Condition_Desc’, ‘Price’, 'Location’重复的值
df.drop_duplicates(subset=['Condition', 'Condition_Desc', 'Price', 'Location'],inplace=True)
查看输出后的列数,明显减少;若未加inplace=True则不会减少
df.shape
(5356, 22)
测试用:选取前两行,只查看第一行
df.head(2)[[True,False]]
| Condition | Condition_Desc | Price | Location | Model_Year | Mileage | Exterior_Color | Make | Warranty | Model | ... | Vehicle_Title | OBO | Feedback_Perc | Watch_Count | N_Reviews | Seller_Status | Vehicle_Tile | Auction | Buy_Now | Bid_Count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Used | mint!!! very low miles | 11412.0 | McHenry, Illinois, United States | 2013.0 | 16000.0 | Black | Harley-Davidson | Unspecified | Touring | ... | NaN | FALSE | 8.1 | NaN | 2427 | Private Seller | Clear | True | FALSE | 28.0 |
1 rows × 22 columns
2. 缺失值处理
- 缺失值的定义需要根据实际情况,比如用-1或者-999代替,便于数据处理
- 可采取直接删除法(少用)、替换法、插值法
- 替换法包括:均值替换、前向、后向、常数替换
前向替换:前一个数据替换
查看每一列缺失值比例
df.apply(lambda x: sum(x.isnull()) / len(x), axis=0)
#沿着行的方向判断有多少缺失值,再除以行数,最后对每一列进行同样操作
Condition 0.000000
Condition_Desc 0.752801
Price 0.000000
Location 0.000373
Model_Year 0.000747
······省略·········
Buy_Now 0.024645
Bid_Count 0.690814
dtype: float64
删除空值
df.dropna(how='all',axis=0).head(3)
#any 只要有就删除 ;all 全部为缺失值才删除;默认axis=1,按列删除
删除‘Condition’,‘Price’,'Mileage’中有空值时的数据
df.dropna(how='any',subset=['Condition','Price','Mileage']).head(3)
#只要这三个变量中有数据缺失即删除
#df.dropna实际业务使用较少
直接用数据填补缺失值
df.fillna(0) #将所有缺失值填补为0,未加inplace=True,修改无效
计算均值,将缺失值用均值替换
df.Mileage.mean()
273842.18927030574
查看缺失值数量
sum(df.Mileage.isnull())
25
#用均值填补
df.Mileage.fillna(df.Mileage.mean(),inplace=True)
#不加inplace=True数据不会更改
替换后缺失值数量变为0,未加inplace=True将不会变化
sum(df.Mileage.isnull())
0
查看缺失值,用众数替换
df[df['Exterior_Color'].isnull()].head(2)
| Condition | Condition_Desc | Price | Location | Model_Year | Mileage | Exterior_Color | Make | Warranty | Model | ... | Vehicle_Title | OBO | Feedback_Perc | Watch_Count | N_Reviews | Seller_Status | Vehicle_Tile | Auction | Buy_Now | Bid_Count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 14 | Used | NaN | 5500.0 | Davenport, Iowa, United States | 2008.0 | 22102.0 | NaN | Harley-Davidson | Vehicle does NOT have an existing warranty | Touring | ... | NaN | FALSE | 9.3 | NaN | 244 | Private Seller | Clear | True | FALSE | 16.0 |
| 35 | Used | NaN | 7700.0 | Roselle, Illinois, United States | 2007.0 | 10893.0 | NaN | Harley-Davidson | NaN | Other | ... | NaN | FALSE | 100 | NaN | 236 | NaN | Clear | False | TRUE | NaN |
2 rows × 22 columns
df['Exterior_Color'].mode()[0]#计算众数
'Black'
两种替换方式:
一是只能针对某一列
df['Exterior_Color'].fillna(df['Exterior_Color'].mode()[0]).loc[[14,35]]
#采取众数填补
#查看填补后的缺失值状态
14 Black
35 Black
Name: Exterior_Color, dtype: object
用value值替换可修改多列
df.fillna(value={'Exterior_Color':'Black','Mileage':df['Mileage'].median()}).head(3)
#inplace=True不加将不会填补缺失值
| Condition | Condition_Desc | Price | Location | Model_Year | Mileage | Exterior_Color | Make | Warranty | Model | ... | Vehicle_Title | OBO | Feedback_Perc | Watch_Count | N_Reviews | Seller_Status | Vehicle_Tile | Auction | Buy_Now | Bid_Count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Used | mint!!! very low miles | 11412.0 | McHenry, Illinois, United States | 2013.0 | 16000.0 | Black | Harley-Davidson | Unspecified | Touring | ... | NaN | FALSE | 8.1 | NaN | 2427 | Private Seller | Clear | True | FALSE | 28.0 |
| 1 | Used | Perfect condition | 17200.0 | Fort Recovery, Ohio, United States | 2016.0 | 60.0 | Black | Harley-Davidson | Vehicle has an existing warranty | Touring | ... | NaN | FALSE | 100 | 17 | 657 | Private Seller | Clear | True | TRUE | 0.0 |
| 2 | Used | NaN | 3872.0 | Chicago, Illinois, United States | 1970.0 | 25763.0 | Silver/Blue | BMW | Vehicle does NOT have an existing warranty | R-Series | ... | NaN | FALSE | 100 | NaN | 136 | NaN | Clear | True | FALSE | 26.0 |
3 rows × 22 columns
查看缺失值所在行
df.loc[df['Exterior_Color'].isnull(),'Exterior_Color'].head(3)
14 NaN
35 NaN
41 NaN
Name: Exterior_Color, dtype: object
查看缺失值所在行的前一行数据
df.loc[[13,14,34,35,40,41],'Exterior_Color']
13 Luxury Rich Red
14 NaN
34 Blue
35 NaN
40 Black
41 NaN
Name: Exterior_Color, dtype: object
用前一行数据填充
df['Exterior_Color'].fillna(method='ffill').loc[[13,14,34,35,40,41]]
# ffill 前向替换 bfil 后向填充
13 Luxury Rich Red
14 Luxury Rich Red
34 Blue
35 Blue
40 Black
41 Black
Name: Exterior_Color, dtype: object
3. 异常值处理
- 异常值是指偏离正常范围的值,不是错误值
- 异常值出现频率较低,但会对实际项目造成影响
- 一般采用过箱线图法(分位差法)或者分布图(标准差法)来判断

- 采取盖帽法货或者数据离散化
读取数据
import numpy as np
import pandas as pd
import os
df =pd.read_csv('MotorcycleData.csv',encoding='gbk')
df.head(3)
| Condition | Condition_Desc | Price | Location | Model_Year | Mileage | Exterior_Color | Make | Warranty | Model | ... | Vehicle_Title | OBO | Feedback_Perc | Watch_Count | N_Reviews | Seller_Status | Vehicle_Tile | Auction | Buy_Now | Bid_Count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Used | mint!!! very low miles | $11,412 | McHenry, Illinois, United States | 2013.0 | 16,000 | Black | Harley-Davidson | Unspecified | Touring | ... | NaN | FALSE | 8.1 | NaN | 2427 | Private Seller | Clear | True | FALSE | 28.0 |
| 1 | Used | Perfect condition | $17,200 | Fort Recovery, Ohio, United States | 2016.0 | 60 | Black | Harley-Davidson | Vehicle has an existing warranty | Touring | ... | NaN | FALSE | 100 | 17 | 657 | Private Seller | Clear | True | TRUE | 0.0 |
| 2 | Used | NaN | $3,872 | Chicago, Illinois, United States | 1970.0 | 25,763 | Silver/Blue | BMW | Vehicle does NOT have an existing warranty | R-Series | ... | NaN | FALSE | 100 | NaN | 136 | NaN | Clear | True | FALSE | 26.0 |
3 rows × 22 columns
将Price数据做处理为number类型
df['Price'] = df['Price'].apply(lambda x : x.strip('$').replace('$','').replace(',','')).astype(int)
x_bar = df['Price'].mean()#均值
x_std = df['Price'].std() #标准偏差
any(df['Price'] > x_bar +3* x_std) # 判断是否有数据超过 均值加两倍标准差
# 标准差 一般乘以 2、2.5或者3,具体依据实际情况定
True
any(df['Price'] < x_bar -2* x_std)
False
查看Price的各种数值
df['Price'].describe()
count 7493.000000
mean 9968.811557
std 8497.326850
min 0.000000
25% 4158.000000
50% 7995.000000
75% 13000.000000
max 100000.000000
Name: Price, dtype: float64
Q1 = df['Price'].quantile(q=0.25) #四分之一分位数
Q3 = df['Price'].quantile(q=0.75)#四分之三分位数
IQR = Q3 - Q1 #分位差
any(df['Price'] > Q3 + 1.5*IQR)#是否有超过上限的值
True
any(df['Price'] < Q1 - 1.5*IQR)#是否有超过下限的值
False
import matplotlib.pyplot as plt #画图常用工具
%matplotlib inline
#确保图形可以在jupter notebook运行
箱型图分析数据
df['Price'].plot(kind='box')
#查看箱型图
#超出上限的数据较多

柱状图分析数据
plt.style.use('seaborn')#设置显示风格
df.Price.plot(kind='hist',bins =30,density=True)
#hist柱状图 bins柱状图个数 density是否绘制成概率密度方式
df.Price.plot(kind='kde') #kde折线图
plt.show
#数据显示 拖尾状况较严重,存在异常值

P99=df['Price'].quantile(q=0.99)
P1=df['Price'].quantile(q=0.01)
df['Price_new']=df['Price']
df.loc[df['Price']>P99,'Price_new'] = P99 #将大于99分位数的值替换为99分位数
df.loc[df['Price']<P1,'Price_new'] = P1 #将小于1分位数的值替换为1分位数
df[['Price','Price_new']].describe()#将数值盖帽法替换后
| Price | Price_new | |
|---|---|---|
| count | 7493.000000 | 7493.000000 |
| mean | 9968.811557 | 9821.220873 |
| std | 8497.326850 | 7737.092537 |
| min | 0.000000 | 100.000000 |
| 25% | 4158.000000 | 4158.000000 |
| 50% | 7995.000000 | 7995.000000 |
| 75% | 13000.000000 | 13000.000000 |
| max | 100000.000000 | 39995.320000 |
df['Price_new'].plot(kind='box')
#盖帽法即类似 去掉一个最高值,最低值

4.数据离散化
- 数据离散化就是分箱
- 一般常用分箱方法是等频分箱或者等宽分箱
- 一般使用pd.cut或者pd.qcut函数
pandas.cut(x,bins,right=True,labels)
--x: 数据
--bins: 离散化的数目,或者切分的区间
--labels: 离散化后各个类别的标签
--right: 是否包含区间右边的值
示例代码:
df['Price_bin']=pd.cut(df['Price_new'],bins=5,labels=range(5))
df['Price_bin'].head(5) #数据太多,只显示一部分
#表示价格中前5位数分别在刚才划分的区间里位于哪一个区间
0 1
1 2
2 0
3 0
4 1
Name: Price_bin, dtype: category
Categories (5, int64): [0 < 1 < 2 < 3 < 4]
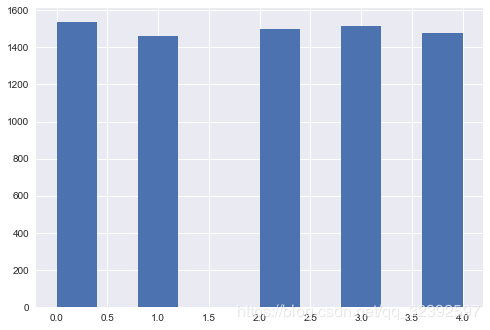
df['Price_bin'].value_counts().plot(kind='bar')
# .value_counts()计算每个区间的价格数量
#绘制成柱状图.plot(kind='bar')
# plt.plot?查看语法

df['Price_bin'].hist()

w=[100,1000,50000,10000,20000,40000]
df['Price_bin']=pd.cut(df['Price_new'],bins=w)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
in
----> 1 df['Price_bin']=pd.cut(df['Price_new'],bins=w)
D:\Anaconda3\lib\site-packages\pandas\core\reshape\tile.py in cut(x, bins, right, labels, retbins, precision, include_lowest, duplicates)
233 bins = _convert_bin_to_numeric_type(bins, dtype)
234 if (np.diff(bins) < 0).any():
--> 235 raise ValueError('bins must increase monotonically.')
236
237 fac, bins = _bins_to_cuts(x, bins, right=right, labels=labels,
ValueError: bins must increase monotonically.
# bins must increase monotonically.
#这里报错是因为我设置的w区间没有单调递增
w=[100,1000,5000,10000,20000,40000]#5000多写了0
df['Price_bin']=pd.cut(df['Price_new'],bins=w)#修改后运行不报错
df[['Price_new','Price_bin']].head(3)
| Price_new | Price_bin | |
|---|---|---|
| 0 | 11412.0 | (10000, 20000] |
| 1 | 17200.0 | (10000, 20000] |
| 2 | 3872.0 | (1000, 5000] |
df['Price_bin']=pd.cut(df['Price_new'],bins=w,labels=range(5))
#加入标签labels,将数值区间更直观化
df[['Price_new','Price_bin']].head(3)
| Price_new | Price_bin | |
|---|---|---|
| 0 | 11412.0 | 3 |
| 1 | 17200.0 | 3 |
| 2 | 3872.0 | 1 |
df['Price_bin'].hist()
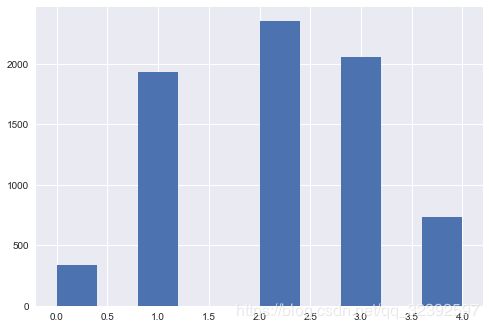
k = 5
w = [1.0 * i/k for i in range(k+1 )] #将1划分成5段
df['Price_bin']=pd.qcut(df['Price_new'], q =w,labels=range(5))
#q代表分位数
pd.qcut
#查看语法,之前命令写错
df['Price_bin'].hist()

[1.0 * i/k for i in range(k+1)]
[0.0, 0.2, 0.4, 0.6, 0.8, 1.0]
k = 5
w1 = df['Price_new'].quantile([ 1.0 * i/k for i in range(k+1)])
#得出符合分位数的数值
w1
0.0 100.00
0.2 3500.00
0.4 6491.00
0.6 9777.00
0.8 14999.00
1.0 39995.32
Name: Price_new, dtype: float64
w1[0] = w1[0]*0.95
w1[1.0] = w1[1.0]*1.1
w1[[0,1.0]]
0.0 95.000
1.0 43994.852
Name: Price_new, dtype: float64
df['Price_bin']=pd.cut(df['Price_new'],bins=w1,labels=range(5))
df['Price_bin'].hist()