【python 爬虫】 scrapy 入门--爬取百度新闻排行榜
scrapy 入门–爬取百度新闻排行榜
环境要求:python2/3(anaconda)
scrapy库
开发环境:sublime text + windows cmd
- 下载scrapy(需要python支持)
- 初始化项目
- 添加一个新的spider
- 实现parse函数
- 其他骚操作
在没接触到scrapy之前,我爬虫用的request库去获取HTML然后用正则去匹配出需要的内容,之后可以再按照自己的需要导出成json文件。也尝试过一些模拟登陆的操作
request请求HTML --> 正则解析内容 --> 导出Json
现在scrapy框架已经帮你封装好实现了功能性的代码,只要关注于你要做什么要什么
spider类填写url —> 实现parse函数 --> item pipeline导出数据
接下来我一 一来介绍如何快速上手去爬取百度新闻排行榜
下载scrapy(需要python支持)
我用的用的anaconda来搭建的python2的环境
然后命令行直接输入pip install scrapy等待一段时间久安装好了,如果遇到问题可以百度尝试解决
初始化项目
scrapy startproject 项目名
cd 项目名
生成一个新的scrapy项目
E:.
│ scrapy.cfg
│
└─baidutop
│ items.py 数据模型化对象
│ middlewares.py 中间件
│ pipelines.py 数据获取后的item通道,用于数据对象的处理
│ settings.py 当前爬虫的设置文件
│ __init__.py
│
└─spiders
__init__.py
添加一个新的spider
scrapy genspider BaiBuTop baidu.com 这里以baidutop名为例子
这一步会在spiders文件下产生一个BaiBuTop 的spider文件
你需要做的就是填写url和需要爬取的内容
值得一说的是scrapy采用的是Xpath和css选择器语言,构建于 lxml 库之上,
而这个库是一个基于 ElementTree的python化的XML解析库,(也可以解析HTML)。
使用相对XPaths:
嵌套的选择器,并使用起始为 / 的XPath,那么该XPath将对文档使用绝对路径,而且对于你调用的 Selector 不是相对路径。
//div 从整篇文档中获取
//div/p 从整篇文档中获取div标签下的p标签
.//p 从上一级开始获取p标签,上一级是一个选择器
p 提取所有直系p元素
text():可以获取该元素下的文本
@href、@+属性名:可以获取该元素某个属性的值
table[@class='last']:选择class为last的table元素
实现parse函数
# -*- coding: utf-8 -*-
import scrapy
from baidutop.items import BaidutopItem
from scrapy.contrib.loader import ItemLoader
from scrapy.selector import Selector
class BaidutopSpider(scrapy.Spider):
name = "BaiduTop"
#allowed_domains = ["baidu.com"]
start_urls = ['http://top.baidu.com/buzz?b=1&fr=topindex']
#这里需要填写爬取的url,多个url会产生多个request给parse
def parse(self, response):
newsSelector = Selector(response=response).xpath('//table[@class="list-table"]/tr')
# 选择class为list-table的table标签
for baiduitem in newsSelector:
# 获取百度新闻每一条的title
baiduitem.xpath('td[@class="keyword"]/a[@class="list-title"]/text()')
# 获取百度新闻每一条的link
baiduitem.xpath('td[@class="keyword"]/a[@class="list-title"]/@href')
# 获取百度新闻每一条的hot值
baiduitem.xpath('td[@class="last"]/span/text()')
其他骚操作
我们说爬虫的目的不仅仅只是为了把数据获取出来,而是为了从数据中获取有用的信息,那没为了信息更加利于其他软件的二次分析,我们需要再把数据进行输出,或者持久化保存
scrapy对于数据导出有一套很丰富的类,因为只涉及到入门,我依然举一个简单的例子
首先数据需要实例化
数据获取出来之后需要用一个对象去保存每一个数据
# item类用于实例化数据对象:
import scrapy
class BaidutopItem(scrapy.Item):
title = scrapy.Field()
hot = scrapy.Field()
link = scrapy.Field()
这样获取出来的数据就可以赋值到一个item中来完成实例化,并且交给后面的item pipeline来处理
保存数据到对象中
修改之前的parse方法,将数据数据赋值到item对象里头
这里其实直接实例化好BaidutopItem然后return也有相同的效果
使用ItemLoader是因为它有更加方便的API
add_xpath,nested_xpath,replace_xpath等等
def parse(self, response):
newsSelector = Selector(response=response).xpath('//table[@class="list-table"]/tr')
for baiduitem in newsSelector:
# 迭代元素,为每一行新闻实例化数据对象
baiduItem = ItemLoader(item = BaidutopItem(), selector=baiduitem)
if(len(baiduitem.xpath('td[@class="first"]')) > 0):
baiduItem.add_xpath('title', 'td[@class="keyword"]/a[@class="list-title"]/text()')
baiduItem.add_xpath('hot', 'td[@class="last"]/span/text()')
baiduItem.add_xpath('link', 'td[@class="keyword"]/a[@class="list-title"]/@href')
# 返回方法的迭代器,将数据按照一个一个item的方式进行处理,直到全部获取完毕
yield self.addNews(baiduItem)
def addNews(self, item):
# return 会将这个item交给下面的pipeline进行处理
return item.load_item()
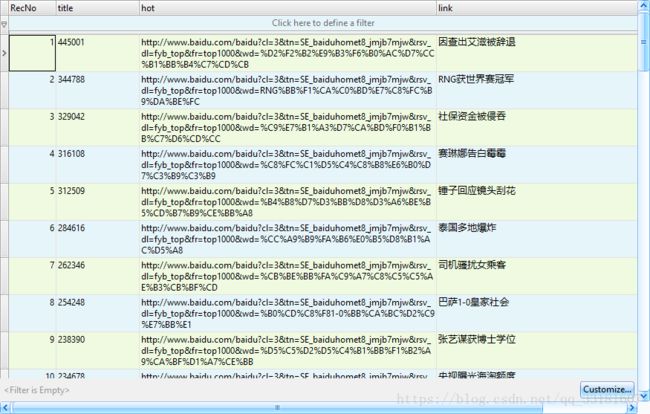
数据的导出
现在我们已经完成了数据获取到实例化的工作了,如果想把数据再进行json对的数据,我们需要再实现一个item pipeline类,让scarpy再进行的保存
item pipeline作为一个通道存在,需要在setting中配置
ITEM_PIPELINES = {
#’baidutop.pipelines.BaidutopPipeline’: 300,
‘baidutop.pipelines.JsonExporterPipeline’: 200,
‘baidutop.pipelines.SQLitePipeline’: 300, #后面数字代表处理的优先级
}
保存为json格式文件:
import codecs, json
from scrapy.exporters import JsonItemExporter
from baidutop.items import BaidutopItem
class JsonExporterPipeline(object):
def __init__(self):
self.file = codecs.open('articlejson.json', 'wb', encoding="utf-8")
# self.exporter = JsonItemExporter(self.file, encoding="utf-8", ensure_ascii=False)
# self.exporter.start_exporting()
def spider_closed(self, spider):
# self.exporter.finish_exporting()
self.file.close()
def process_item(self, item, spider):
# self.exporter.export_item(item)
if isinstance(item, BaidutopItem):
lines = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(lines)
return item
保存到sql数据库:
# 爬取到的数据写入到SQLite数据库
# 可以支持多种数据库
配置数据库名字,在setting文件中
SQLITE_DB_NAME = 'scrapy.db'
# 这里为了方便,我直接用SQLite Expert Personal 3创建好db数据库中的表和字段了
import sqlite3
class SQLitePipeline(object):
#打开数据库
def open_spider(self, spider):
db_name = spider.settings.get('SQLITE_DB_NAME', 'scrapy.db')
self.db_conn = sqlite3.connect(db_name)
self.db_cur = self.db_conn.cursor()
#关闭数据库
def close_spider(self, spider):
self.db_conn.commit()
self.db_conn.close()
#对数据进行处理
def process_item(self, item, spider):
if isinstance(item, BaidutopItem):
self.insert_db(item)
return item
#插入数据
def insert_db(self, item):
print item['title']
values = (
item['title'][0],
item['hot'][0],
item['link'][0],
)
sql = 'INSERT INTO BaiduNews VALUES(?,?,?)'
self.db_cur.execute(sql, values)
最后一步运行爬虫:
在项目路径下打开cmd:
输入 scrapy list 可以看到新加的一个spiders
输入 scrapy crawl + spiders名字 ,开始运行爬虫
最后数据保存成json文件
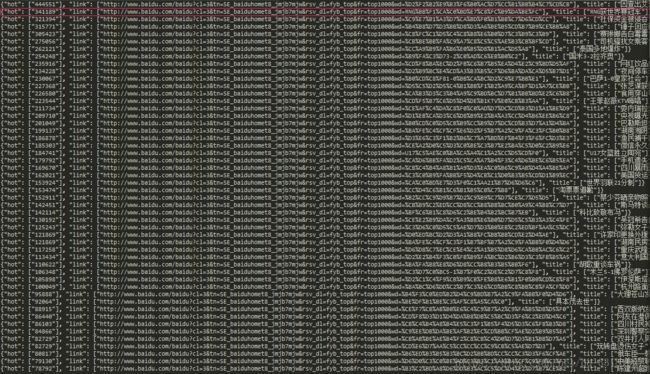
存储到数据库中