win10下YOLO v3的安装
本文章所要讲的是如何在win10环境下安装yolov3,然后用官方的权重文件去做识别
【注】非常重要的一点是大家在进行之前首先要看一下自己的显卡,如果连N卡都不如,那就先放一放吧

接下来进行入正题:
一、所需环境和工具:
1.win10系统
2.Visio Studio2019,yolov3支持2012,2013,2015,高版本需要下载相关的数据集
3.OpenCV3.4.0,OpenCV的版本不要高于3.4.0,否则后面会出问题
4.CUDA Tookit10.1
5.CUDNN7.6.2
6.darknet
二、相关工具和软件的安装
1.下载并安装VS2019
下载链接https://visualstudio.microsoft.com/zh-hans/downloads/?lang=en&rr=https%3A%2F%2Fwww.csdn.net%2Flink%2F%3Ftarget_url%3Dhttps%253A%252F%252Fvisualstudio.microsoft.com%252Fdownloads%252F%253Flang%253Den%26id%3D86696540%26token%3D3acf26b89ceeb1c8c6f193e498f852b1安装以下三个即可
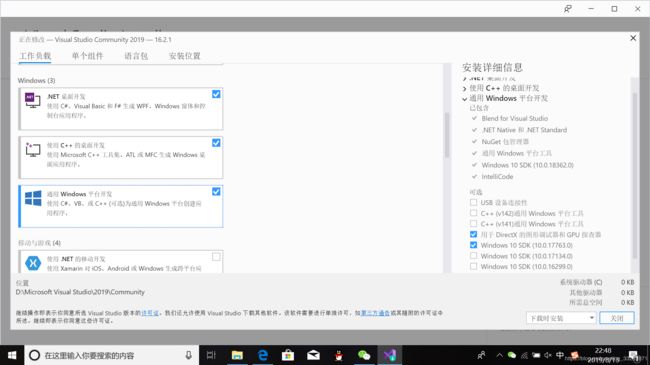
VS2019需要下载相关数据集,在电脑中找到Visio studio intaller:
打开后如下图所示:
 点击修改,找到v140工具集,选中,点击修改即可:
点击修改,找到v140工具集,选中,点击修改即可:

另外,单个组件中的Windows10 SDK (10.0.17763.0)必须要安装,在后面darknet项目重定向的过程中必须要定向到这个,否则在生成darknet.exe的过程中会出错

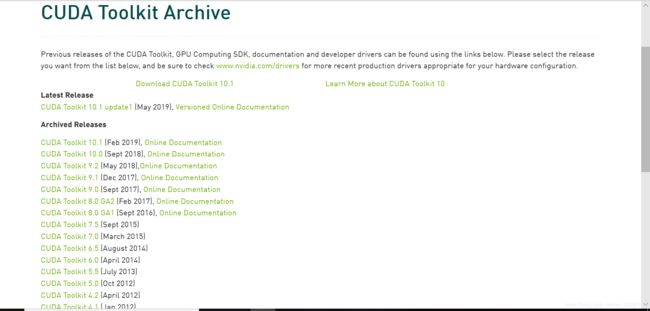
2.下载并安装CUDA10.1
下载链接:
https://developer.nvidia.com/cuda-toolkit-archive
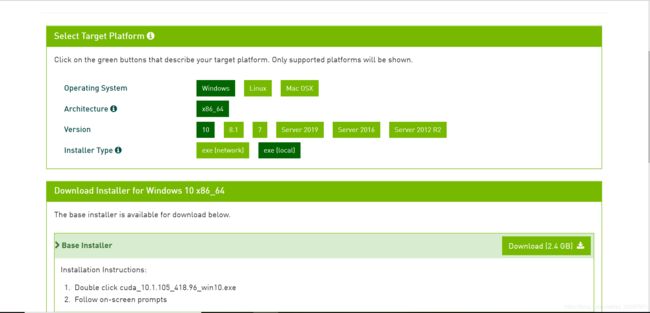
下载好后运行下面的.exe文件:
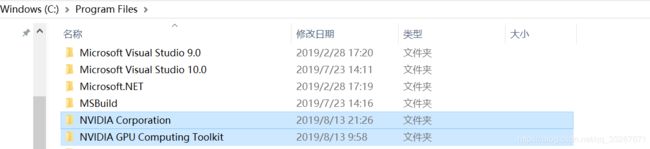
![]() 用默认路径即可,不需要修改,即使你修改了它最后也会给你挪到C盘去,而且需要用到的是下面的这两个文件里面的东西,这两个文件它会给你安装到C盘的下面的这个路径下的:
用默认路径即可,不需要修改,即使你修改了它最后也会给你挪到C盘去,而且需要用到的是下面的这两个文件里面的东西,这两个文件它会给你安装到C盘的下面的这个路径下的:
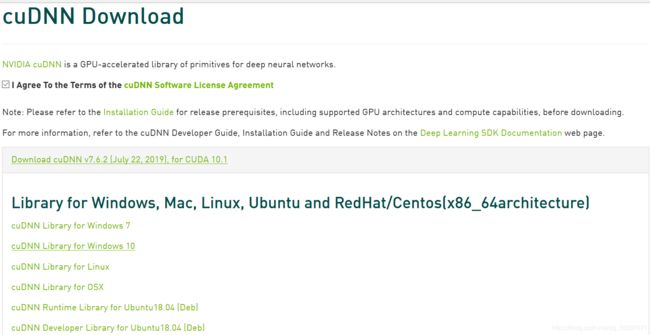
3.下载CUDNN7.6.2
下载链接:
https://developer.nvidia.com/rdp/cudnn-download
需要注册账号才能下载
下载好以后将其进行解压:
![]()
![]()

(1)将\cuda\bin\cudnn64_7.dll 复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin
(2)将 \cuda\ include\cudnn.h 复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\include
(3)将\cuda\lib\x64\cudnn.lib复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\lib\x64
4.下载并安装OpenCV3.4.0
下载链接:
https://opencv.org/releases/
将其安装在某个路径下,记住即可,例如我将其安装在下面的路径下:


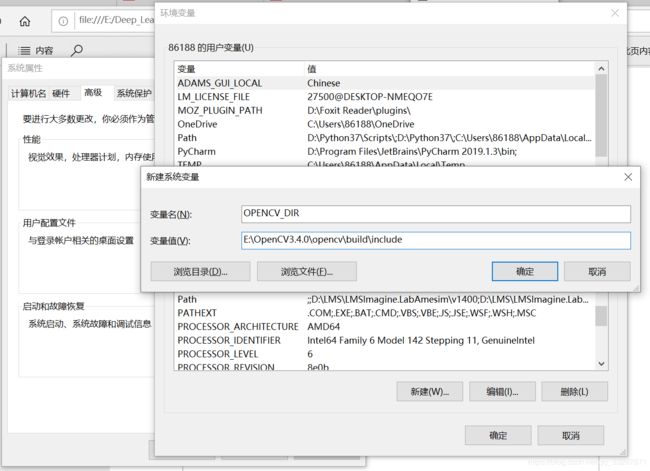
接着配置OpenCV的环境变量
我的电脑->属性->高级系统设置->环境变量->新建,变名和变量值(变量值就是自己OpenCV的安装路径下的include的路径)如下图所示:
5.下载darknet并生成darknet.exe
下载链接:
https://github.com/AlexeyAB/darknet
下载好以后解压:
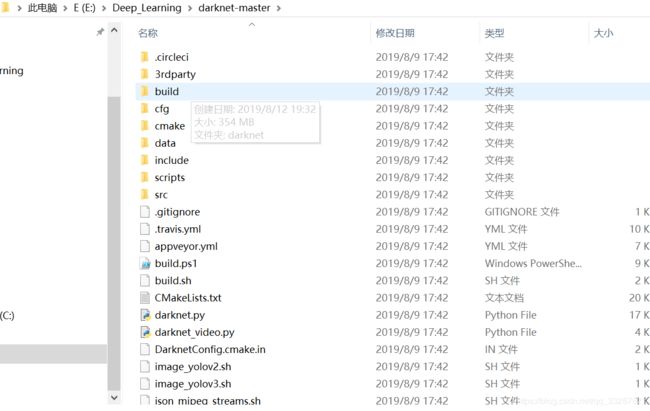
进入到下面的路径下对darknet.vcxproj文件进行修改
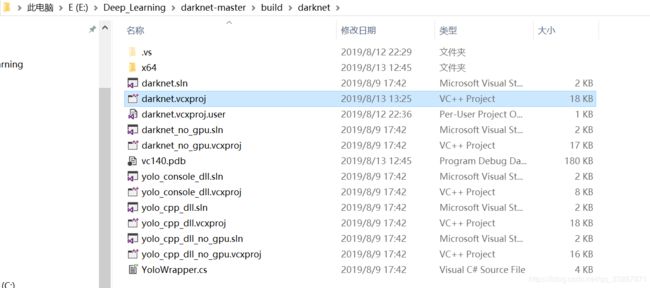 用记事本将其打开并将里面的CUDA 10.0全部替换成CUDA 10.1
用记事本将其打开并将里面的CUDA 10.0全部替换成CUDA 10.1
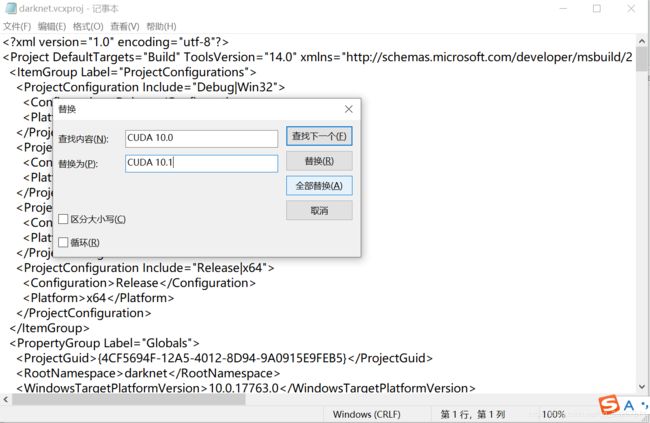
如果用的CUDA9.0,这里还要将compute_75和sm_75分别改为compute_70和sm_70,因为cuda9.0不支持75。
5.2、进入\darknet-master\build\darknet中,没有GPU的打开darknet_no_gpu.sln,有GPU的打开darknet.sln。将项目修改为Release x64。如果是VS2017,需要重定向项目:右键项目–>重定向项目(不升级)
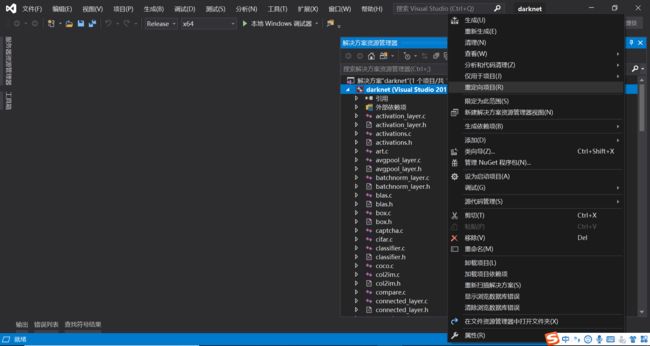
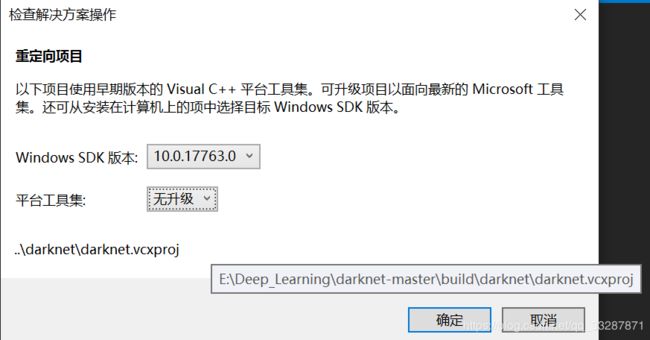
一定要重定向到上图所示的SDK版本,并且选择无升级,否则在生成darknet.exe的过程中会报错
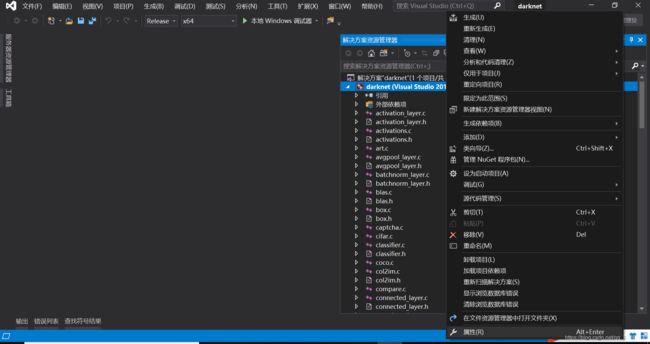
重定向后如下图所示是正确的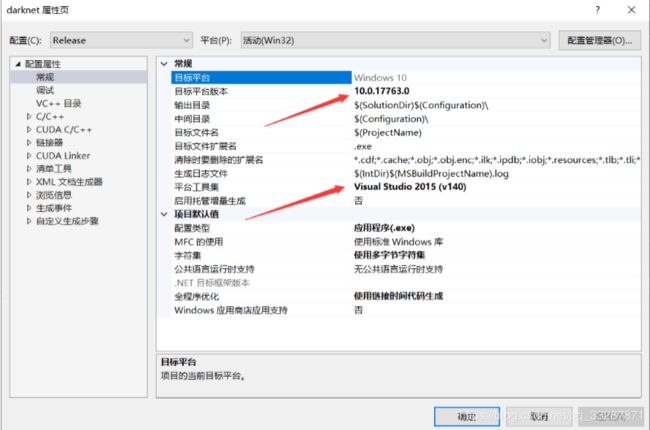
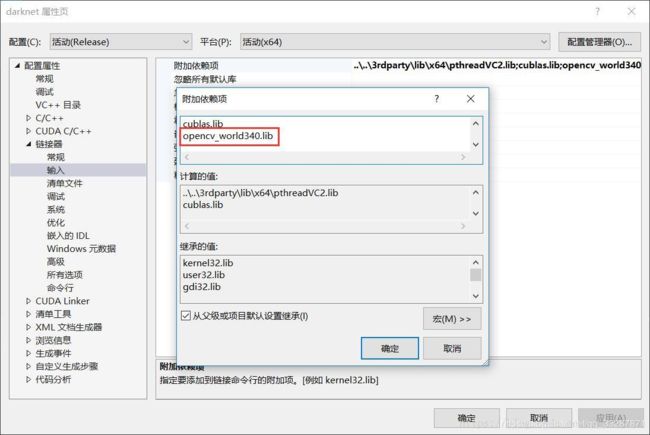
配置包含目录 + 库目录 + 链接器(位置已经用红框框出)

包含目录:在darknet项目上点击鼠标右键->属性,弹出如下界面:然后VC++目录–>包含目录–>编辑添加的目录:…\opencv\build\include(…代表opencv的安装路径,下文同理)…\opencv\build\include\opencv…\opencv\build\include\opencv2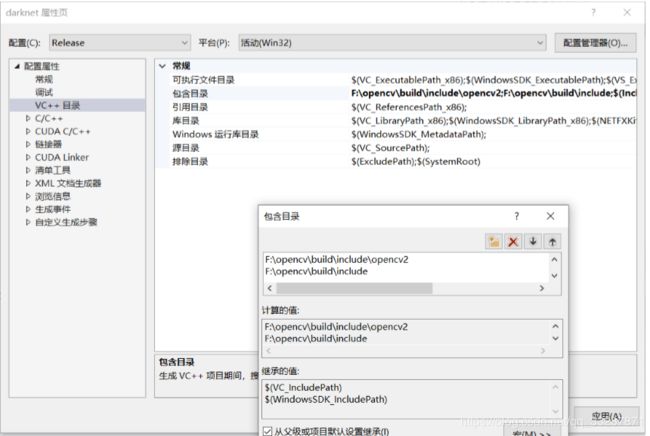
库目录:方法与包含目录类似,添加的目录为:…\opencv\build\x64\vc14\lib
链接器:添加目录…\opencv\build\x64\vc14\lib下库的名字:opencv_world341.lib

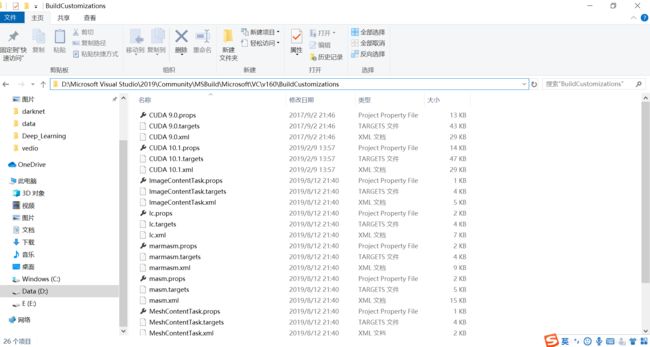
拷贝CUDA 10.1.props等文件:
CUDA 10.1.props 等文件就在cuda的安装目录下,本教程路径是:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\extras\visual_studio_integration\MSBuildExtensions
拷贝所有文件到VS2019安装路径下:
我再生成darknet.exe的时候VS2019报错提示我VS2019安装路径下面某个文件下缺文件,我就把这些文件都拷贝过去了:
右键项目,生成,成功后会生成一个darknet.exe在…\darknet-master\build\darknet\x64目录下,然后将…\opencv\build\x64\vc14\bin下的opencv_world340.dll 和opencv_ffmpeg340_64.dll 复制到 darknet.exe的同级别目录下。
做完上述步骤之后,可以测试下环境是否搭建成功:
在github上下载作者训练好的模型,网址:https://github.com/AlexeyAB/darknet/blob/master/README.md
直接点这里下载https://pjreddie.com/media/files/yolov3.weights
下载后放在darknet-master\build\darknet\x64下
运行
cd到darknet.exe所在目录,运行命令即可。 命令1:darknet.exe detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
- 采集一端视频,将视频剪辑成图片(.jpg格式)
'''
opencv_机器学习-视频分解图片
实现步骤:
1.加载视频
2.读取视频的Info信息
3.通过parse方法完成数据的解析拿到单帧视频
4.imshow,imwrite展示和保存
'''
import cv2
#获取视频打开的句柄,参数是file name
cap = cv2.VideoCapture('test.avi')
#判断是否打开
isOpened = cap.isOpened
print(isOpened)
#获取帧率,帧率就是每秒钟展示多少张图片
fps = cap.get(cv2.CAP_PROP_FPS)
#获取宽度和高度信息
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
print(fps,width,height)
i = 0
while isOpened:
#这里的10代表读取十张图片
if i == 10:
break
else:
i = i + 1
#读取每一张 flag表示是否读取成功,frame表示图片的内容
(flag,frame) = cap.read()
fileName = 'image' + str(i) + '.jpg'
print(fileName)
if flag == True:
cv2.imwrite(fileName,frame,[cv2.IMWRITE_JPEG_QUALITY,100])
print('end!')
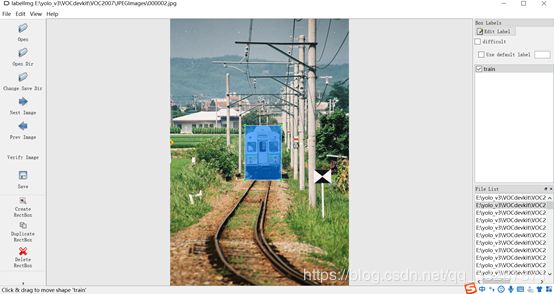
- 用下面的工具为每一张图片打上标签,另存成.xml文件
- 准备自己的数据集文件,路径下的文件名如下图所示:
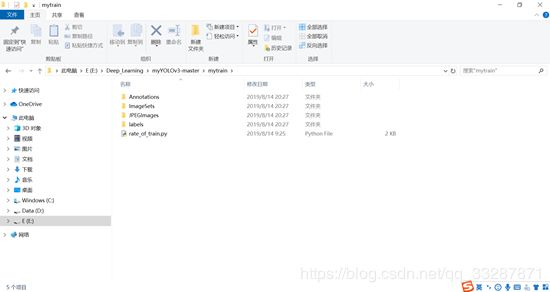
Annotations文件夹中放所有的.xml文件,JPEGImages文件夹放所有的图片(.jpg格式),ImageSets路径下的Main文件夹用于存放生成的train.txt文件
labels文件夹用于存放下一步生成的.txt文件
利用下面的代码生成其他几个txt文件:
import os
import random
trainval_percent = 0.7 # trainval占总数的比例
train_percent = 0.5 # train占trainval的比例
xmlfilepath = r'F:\caffe\py-faster-rcnn-master\data\VOCdevkit2007\VOC2007\Annotations'
txtsavepath = r'F:\caffe\py-faster-rcnn-master\data\VOCdevkit2007\VOC2007\ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open(txtsavepath + r'\trainval.txt', 'w')
ftest = open(txtsavepath + r'\test.txt', 'w')
ftrain = open(txtsavepath + r'\train.txt', 'w')
fval = open(txtsavepath + r'\val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
4. 利用xml_to_txt代码将之前生成的.xml文件转换成.txt文件
该py文件放到了“E:\Deep_Learning\myYOLOv3-master\darknet-master\build\darknet\x64”路径下
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
classes = ["person","cat"]#这里是你的所有分类的名称
myRoot = r'C:\Users\Desktop\myyolov3\mytrain'#这里是你项目的根目录,VOC数据集文件夹的路径
xmlRoot = myRoot +r'\Annotations'
txtRoot = myRoot + r'\labels'
imageRoot = myRoot + r'\JPEGImages'
def getFile_name(file_dir):
L=[]
for root, dirs, files in os.walk(file_dir):
print(files)
for file in files:
if os.path.splitext(file)[1] == '.jpg':
L.append(os.path.splitext(file)[0]) #L.append(os.path.join(root, file))
return L
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open(xmlRoot + '\\%s.xml' % (image_id))
out_file = open(txtRoot + '\\%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
#image_ids_train = open('D:/darknet-master/scripts/VOCdevkit/voc/list.txt').read().strip().split('\',\'') # list格式只有000000 000001
image_ids_train = getFile_name(imageRoot)
# image_ids_val = open('/home/*****/darknet/scripts/VOCdevkit/voc/list').read().strip().split()
list_file_train = open(myRoot +r'\ImageSets\Main\train.txt', 'w')
#list_file_val = open('boat_val.txt', 'w')
for image_id in image_ids_train:
list_file_train.write(imageRoot + '\\%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file_train.close() # 只生成训练集,自己根据自己情况决定
# for image_id in image_ids_val:
# list_file_val.write('/home/*****/darknet/boat_detect/images/%s.jpg\n'%(image_id))
# convert_annotation(image_id)
# list_file_val.close()
在指定好路径后会程序会识别到上述路径下的文件,并将生成的.txt文件和train.txt文件存放到指定的路径下。
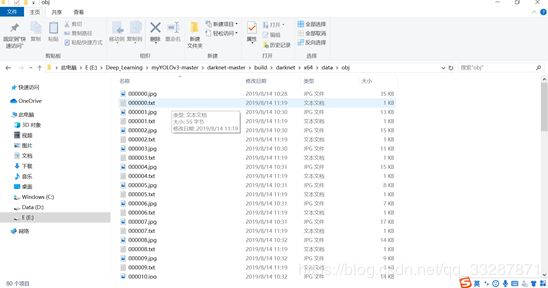
5. 把所有的样本图片和对应的txt文件放到:
darknet-master\build\darknet\x64\data\obj\下面,一张图对应一个txt。
6. 在darknet-master\build\darknet\x64\data\下新建train.txt
把训练图片的路径写在文件里面,每行一个路径,刚刚上面的代码也已经包含了自动写入train.txt(执行前先在myRoot\ImageSets\Main\下新建一个train.txt),如图

7. 将darknet的预训练权重放入darknet-master\build\darknet\x64
链接:https://pan.baidu.com/s/1Gdo2gj1bggjUtW9CyYkIpQ 密码:x5ht
8. 在darknet-master\build\darknet\x64 新建yolo-obj.cfg文件(可以直接复制yolov3.cfg,然后重命名为yolo-obj.cfg)
修改这个文件内容:
batch改成64:batch=64
subdivisions改成8 :subdivisions=8
训练的时候如果出现内存溢出错误(Out of memory),可以,将batch改小些(64,32,16,8),将random改成0关闭多尺度训练。
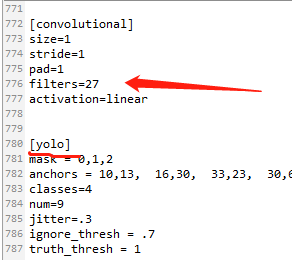
查找每个yolo下(共有3处)的classes改成你自己的类的数量:classes = N
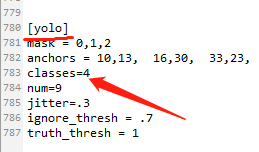
查找每个yolo上面第一个convolutional下的filters(如图)改成你自己的大小,计算方法是: filters=(classes + 5)x3 ,由于我的是4类,所以我的filters=27. (这个也是只有3处)
9. 在darknet-master\build\darknet\x64\data\下新建obj.names文件,里面写入你的要检测的分类的类名,也就是在第二步打标签的所有标签的名字,每个类名占一行。
10.在darknet-master\build\darknet\x64\data\下新建obj.data文件,像这样


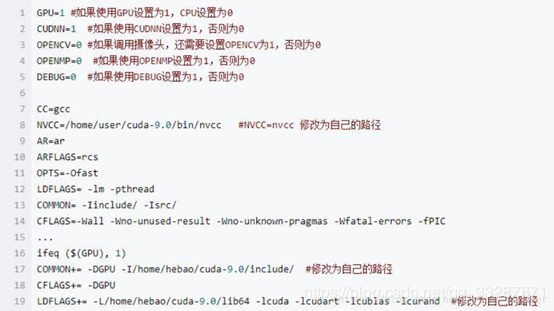
11.修改网络配置文件Makefile(在\darknet-master路径下)
12.开始训练
Win+R打开终端,cd进入darknet-master\build\darknet\x64路径,下面命令开始训练:
darknet.exe detector train data/obj.data yolo-obj.cfg darknet53.conv.74
训练时,每训练100轮,都会生成一个权重文件在build\darknet\x64\backup\ 下,文件名例如:yolo-obj_100.weights(后面的100是训练100轮是的权重)。
如果训练的时候IOU出现全是-nan(ind),这应该是你的数据集有问题了,仔细检查下图片或txt文件的路径有没有写对或放对。可以在labels下放置图片标签txt文件试试。
13.测试
输入:同意cd进入darknet-master\build\darknet\x64路径,然后输入
darknet.exe detector test data/obj.data yolo-obj.cfg yolo-obj_100.weights(最后的权重改为自己的权重)。
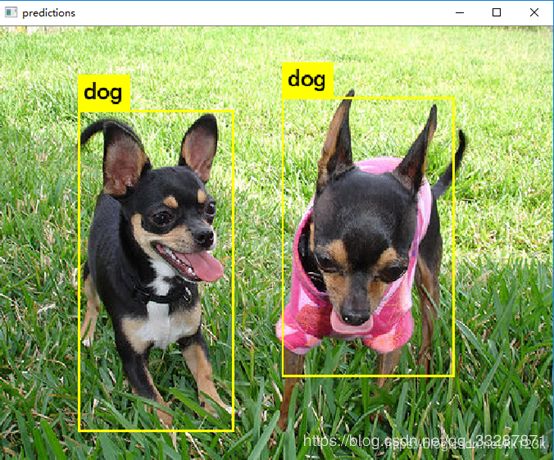
然后终端会提醒你输入图片路径,然后你输入测试图片的绝对路径即可看到效果。
在backup路径下会生成weights文件,如果中途按下了CTRL+C,又想在原来的基础上接着训练,则在终端中输入如下命令,即将darknet53.conv.74替换成backup/yolo-obj_last.weights


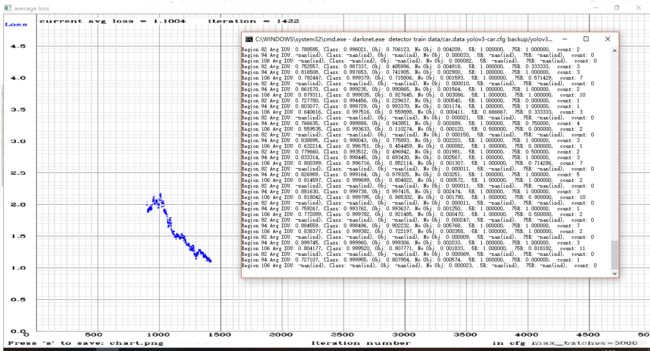
IOU:代表预测的矩形框和真实目标的交集与并集之比;
class:标注物体分类的正确率,期望该值趋近于1;
Obj:越接近1越好;
No Obj:越接近0越好;
.5R: 1.000000: 是在 recall/count 中定义的, 是当前模型在所有 subdivision 图片中检测出的正样本与实际的正样本的比值;
0.75R: 以IOU=0.75为阈值时候的recall;
count:正样本数目。
1.什么时候停止训练
官方给出的是,average loss在0.05~3之间,0.05是相对来说小模型而且简单的数据集(for a small model and easy dataset),3是较大模型并且复杂的数据集 (for a big model and a difficult dataset)。非常简单的特性,就是发现avg loss在很多代中不再下降了,就可以停止训练了。
2.并不是迭代次数越多越好,也不是avg loss越低越好。
官方的说法如下,训练次数过多可能会出现过拟合的现象:可以在train数据集中检测到物体,但是在其他的数据集中效果会降低。
or example, you stopped training after 9000 iterations, but the best result can give one of previous weights (7000, 8000, 9000). It can happen due to overfitting. Overfitting - is case when you can detect objects on images from training-dataset, but can’t detect objects on any others images. You should get weights from Early Stopping Point
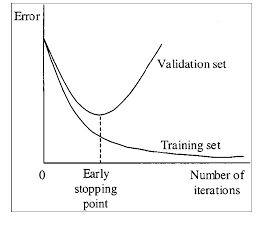
3.选择一个效果最好的weights文件。
在训练过程中得到了三个weights文件,如下,迭代次数大小关系为1000<2000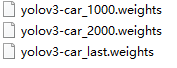
分别使用三个命令行进行测试:
darknet.exe detector map data/car.data yolov3-car.cfg backup\yolo-car_1000.weights
darknet.exe detector map data/car.data yolov3-car.cfg backup\yolo-car_2000.weights
darknet.exe detector map data/car.data yolov3-car.cfg backup\yolo-car_last.weights