之浅谈冒泡排序算法
“简单不先于复杂,而是在复杂之后.” —— Alan Perlis

序言
当我们第一次数组排序的时候,通常都会介绍一种排序算法,那就是冒泡排序.冒泡排序的思路是最简单的,最容易让人理解的.可能看这篇文章的各位大神都在程序的世界遨游已久,会对此嗤之以鼻,说不就是两层For循环嘛,不是简单的很?而我却要说,NO,NO,NO,今天的文章可能让你眼前一亮,请耐心看下去.你会发现一些你认知中所不一样的东西.
冒泡概念简介以及最简单的排序实现
冒泡排序是一种交换排序,它的实现原理是:两两比较相邻的记录值,如果反序则交换,直到没有反序的记录为准,如上图,这就是一次完整的冒泡排序.我们看一下代码是如何实现的.还是以OC语言为基础.在ViewController中实现代码.
#import "ViewController.h"
@interface ViewController ()
@property(nonatomic,strong)NSMutableArray *dataArray;//数据源数组
@end
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
self.dataArray = [NSMutableArray arrayWithArray:@[@6,@5,@3,@1,@8,@7,@2,@4]];
for (int i = 0; i< self.dataArray.count; i++) {
for (int j = i +1 ; j 

上面的冒泡排序算法应该是我们平常最常用的冒泡排序了,但是其实从严格意义上来说,上面的冒泡排序并不能成为严格意义上的冒泡排序,因为它不满足"两两比较相邻记录"的冒泡排序的思想,相比叫它冒泡排序,不如叫它最简单的交换排序.它的思路就是让每一个元素与它后面的每一个元素比较,如果大则交换,这样第一个位置的元素在第一排序之后一定活成为最大值.如上图,这就是一次排序的整个过程.上面的排序方式只能算是最简单的排序方式了,不过这样简单的代码却有缺陷的,比如在第一次排序完成的数组为[5,3,1,8,7,6,2,4]对其他的元素却没有帮助.也就说,这个方法是非常低效的,那么接下来,我们看一下正宗的冒泡排序有没有什么改进的地方.
冒泡排序算法
我们先看一下正宗的冒泡排序代码是如何实现的
self.dataArray = [NSMutableArray arrayWithArray:@[@6,@5,@3,@1,@8,@7,@2,@4]];
for (int i = 0; i< self.dataArray.count; i++) {
//注意j是从后往前循环,从后往前遍历
for (int j = (int)self.dataArray.count-1 ; j >= i ; j--) {
if (self.dataArray[i]< self.dataArray[j]) {
NSNumber *number = self.dataArray[i];
self.dataArray[i] = self.dataArray[j];
self.dataArray[j] = number;
}
}
}
NSLog(@"%@ ",self.dataArray);
}
那么,我们就看第一次遍历,先从最后一个元素4开始,因为4>2,所以交换位置,然后4和7比较,不交换位置,7和8比较,交换位置,最后,8分别和1,3,5,6比较,然后全都交换位置,然后数组的第一次遍历就完成,数组为[8,6,5,3,1,7,4,2];相比于简单排序第一完成之后的数组[5,3,1,8,7,6,2,4],除了元素8往前进了一位,元素6到了数组的后半部分了.这一正宗的算法果然要比前面的要有所进步,可能数组中的元素个数少的时候,可能效率差的不会是很大,如果在上十万条数据的排序过程中,这种差异就会体现出来.但是,这样正宗的冒泡排序有没有改进的方案呢?答案是有的.首先,我们来打印一下冒泡排序和简单的执行次数.
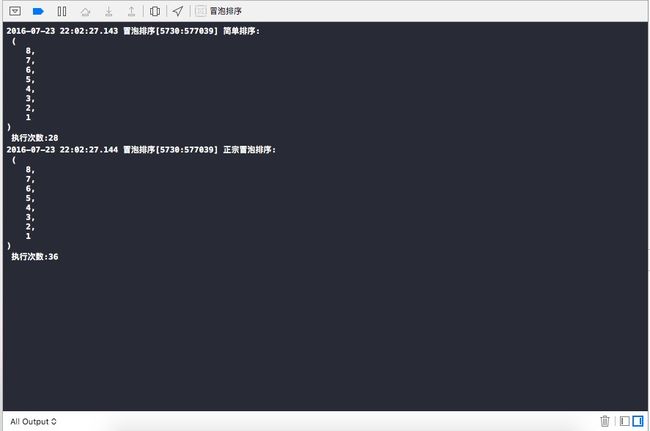
那么,为什么会出现这种情况,我们改如何改进呢?
冒泡排序的优化
为什么冒泡排序会比最贱的排序方式执行次数多呢?比如正宗的冒泡排序第一次执行完成之后的数组为[8,6,5,3,1,7,4,2],我们当执行第二次的时候,最后执行的的是7和8 的比较,明明元素8 的位置就赢改第一位,毋庸置疑,却还要比较一次,尽管没有交换数据,但是比较还是多余的.往后的遍历中,这样的无用的比较缺不改变位置很多,我们改如何改进呢?我们的改进思想是这样的,设置一个BOOL值,在一次的遍历
过程中只要有位置的变动,我们就允许下一次遍历,否则就不再执行下一次遍历,代码实现如下.
self.runNumber = 0;
self.isContinue = YES;
self.dataArray = [NSMutableArray arrayWithArray:@[@6,@5,@3,@1,@8,@7,@2,@4]];
for (int i = 0; i< self.dataArray.count && self.isContinue; i++) {
self.isContinue = NO;
for (int j = (int)self.dataArray.count-1 ; j >= i ; j--) {
if (self.dataArray[i]< self.dataArray[j]) {
self.isContinue = YES;
NSNumber *number = self.dataArray[i];
self.dataArray[i] = self.dataArray[j];
self.dataArray[j] = number;
}
self.runNumber++;
}
}
NSLog(@"冒泡排序优化:\n %@ \n 执行次数:%ld",self.dataArray,self.runNumber);
代码和普通的冒泡排序最大的区别就是多了一个BOOL值,来判断一下程序是否有必要执行下去,进过这样的改进,冒泡排序在性能上就有了一些提升,可以避免因有序的情况下无意义的循环判断.
那么,程序到底优化了多少呢?来,我们打印三次的执行次数,如下图,我们可以从图中可以看出优化的执行次数为30次,而冒泡排序的执行次数是36次,效率提高了16.67%,大大的优化程序性能.
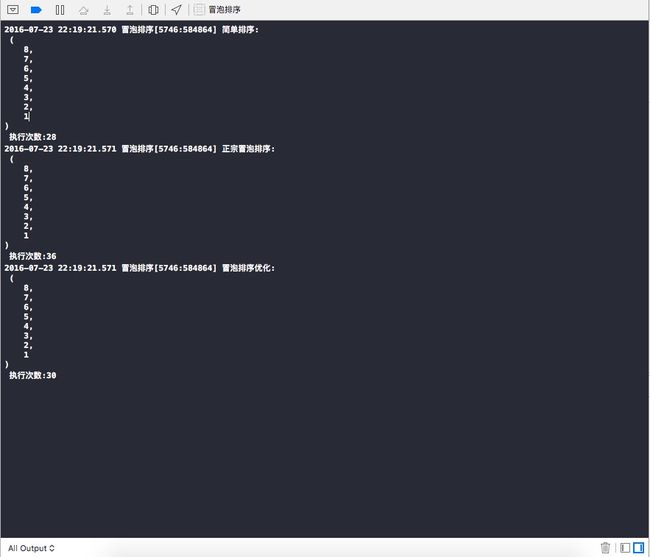
由于一直是使用OC做开发,C语言已经忘了差不多了,所以我这里附上一份OC的冒泡排序Demo,如果有任何疑问,请在下面评论区评论,我会及时的回复您的,谢谢!